







学习scrapy已经有一段时间了,之前因为各种事吧一直没有对这部分内容进行总结,好啦,现在言归正传了。
1.最烦人的scrapy安装已经解决了,接下来就是利用scrapy进行实战演练。
2.首先,在命令窗口中创建项目,输入scrapy startproject project-name.
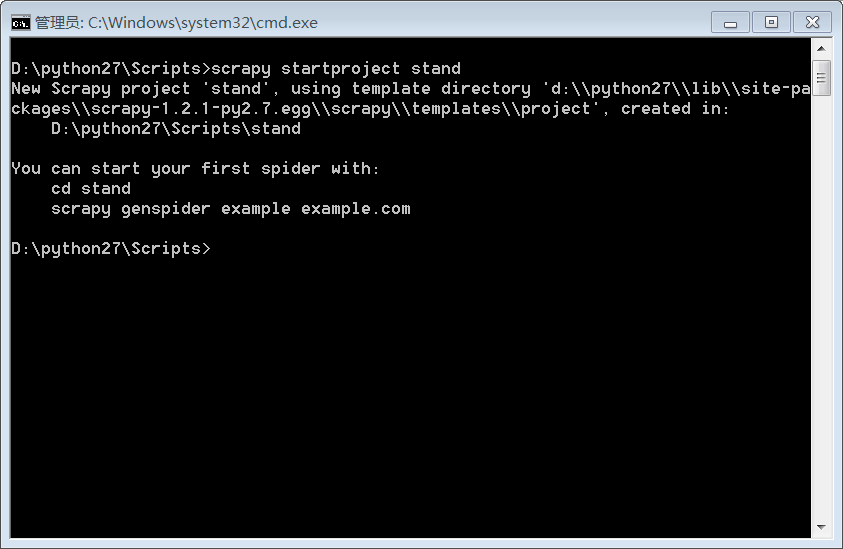
3.查过资料后,知道各个项目的意义:
scrapy.cfg----项目的配置文件
stand/spiders/----放置spiders代码的目录(就是之后在这里建咱们自己写的爬虫代码)
stand/items.py----爬取的目标(自己随便起名字)
stand/pipelines.py----管道,即若将爬到的内容放到数据库中就在这写明,若存到本地,便不用改
stand/settings.py----放置,即储存的路径、格式
4.下面我将在创建的"heart"项目下写代码。
items.py
import scrapy
from scrapy import Item,Field
class HeartItem(scrapy.Item):
novname = scrapy.Field()
link = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
passsettings.py
BOT_NAME = 'heart'
USER_AGENT='Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:49.0) Gecko/20100101 Firefox/49.0'
FEED_URI=u'file///D:/Python27/Scripts/heart/nov1.CSV'
FEED_FORMAT = 'CSV'
SPIDER_MODULES = ['heart.spiders']
NEWSPIDER_MODULE = 'heart.spiders'qidian.py(随便起的爬虫名字)
# coding:utf-8
from scrapy.spiders import CrawlSpider
from scrapy.http import Request
import requests
from scrapy.selector import Selector
from heart.items import HeartItem
class heartSpider(CrawlSpider):
for i in range(1,3):
name = "heart"
start_urls = ['http://f.qidian.com/all?size=-1&sign=-1&tag=-1&chanId=-1&subCateId=-1&orderId=&update=-1&page=%d&month=-1&style=1&action=-1' % i]
def __init__(self):
self.item = HeartItem()
def parse(self, response):
selector = Selector(response)
urls = selector.xpath('//div[@class="book-mid-info"]/h4/a/@href').extract()
novname = selector.xpath('//div[@class="book-mid-info"]/h4/text()').extract()
for url in urls:
url = "http:" + url
yield Request(url, callback=self.parseContent)
def parseContent(self,response):
selector1 = Selector(response)
links = selector1.xpath('//ul[@class="cf"]/li/a/@href').extract()
novname = selector1.xpath('//title/text()').extract()
self.item['novname'] = novname
for link in links:
self.item['link'] = 'http:'+link
r = requests.get(self.item["link"])
sel = Selector(r)
# selector2 = Selector(response)
title = sel.xpath('//title/text()').extract()
content = sel.xpath('//div[@class="read-content j_readContent"]/p/text()').extract()
self.item['title'] = title
self.item['content'] = content
yield self.item5.写爬虫代码时需要注意:
***确保安装好requests,requests学习网址:
http://blog.csdn.net/iloveyin/article/details/21444613
http://jingyan.baidu.com/article/b2c186c8f5d219c46ef6ff85.html
6.学习完后,终于再次体会到“前人栽树,后人乘凉”的感觉,这里提供一些比较好的scrapy学习网址,真的很有用!!!
http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
http://blog.csdn.net/yedoubushishen/article/details/50984045















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









