







1.ElasticSearch文档分值_score计算底层原理
1)boolean model
根据用户的query条件,先过滤出包含指定term的doc
query "hello world" --> hello / world / hello & world
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能
2)relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关。
Field-length norm:field长度,field越长,相关度越弱
3)vector space model
多个term对一个doc的总分数
hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量。hello这个term,给的基于所有doc的一个评分是3,world这个term,给的基于所有doc的一个评分是6,则query vector 为 [3, 6]
doc vector,3个doc,一个包含hello,一个包含world,一个包含hello 以及 world
3个doc
doc1:包含hello --> [3, 0]
doc2:包含world --> [0, 6]
doc3:包含hello, world --> [3, 6]
会给每一个doc,拿每个term计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector,画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数,每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数。
弧度越大,分数越低; 弧度越小,分数越高
如果是多个term,那么就是线性代数来计算,无法用图表示
4)分析一个document上的_score是如何被计算出来的
GET /aid_rdr_hzqy_smza_index_3/_doc/mz_6320698/_explain
{
"query": {
"match": {
"aid_pat_visit.visit_dept_name": "老年睡眠障碍"
}
}
}2.分词器工作流程
1)分词器的作用
切分词语,normalization
recall,召回率:搜索的时候,增加能够搜索到的结果的数量
character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
tokenizer:分词,hello you and me --> hello, you, and, me
token filter:lowercase,stop word,synonymom,liked --> like,Tom --> tom,a/the/an --> 干掉,small --> little
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引
2)内置分词器的介绍
Set the shape to semi-transparent by calling set_trans(5)
standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)
simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
stop analyzer: 移除停用词,比如a the it 等等
测试:
POST _analyze
{
"analyzer":"standard",
"text":"Set the shape to semi-transparent by calling set_trans(5)"
}
3)定制分词器
3.1)默认的分词器 standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
3.2)修改分词器的设置
// 启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
GET /my_index/_analyze
{
"analyzer": "es_std",
"text": "a dog is in the house"
}
// 定制化自己的分词器
DELETE my_index
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=> and"
]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [
"the",
"a"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
}
}
}
}
}
GET /my_index/_analyze
{
"text": "tom&jerry are a friend in the house, <a>, HAHA!!",
"analyzer": "my_analyzer"
}
PUT /my_index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}3.3)ik分词器详解
ik配置文件地址:es/plugins/ik/config目录
IKAnalyzer.cfg.xml:用来配置自定义词库
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
quantifier.dic:放了一些单位相关的词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
ik原生最重要的两个配置文件
main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
stopword.dic:包含了英文的停用词,停用词,stopword a the and at but
一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中
3.4)IK分词器自定义词库
(1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里,需要自己补充自己的最新的词语,到ik的词库里面去。
IKAnalyzer.cfg.xml:ext_dict,custom/mydict.dic
(2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索;custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es。
补充自己的词语,然后需要重启es,才能生效
IK分词器源码下载:https://github.com/medcl/elasticsearch-analysis-ik/tree
3.5)IK热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">location</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">location</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">words_location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">words_location</entry>
</properties>3. es生产集群部署之针对生产集群的脑裂问题专门定制的重要参数
1)集群脑裂是什么?
所谓脑裂问题,就是同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master。如果因为网络的故障,导致一个集群被划分成了两片,每片都有多个node,以及一个master,那么集群中就出现了两个master了。但是因为master是集群中非常重要的一个角色,主宰了集群状态的维护,以及shard的分配,因此如果有两个master,可能会导致数据异常。
2)脑裂的过程
如:

节点1在启动时被选举为主节点并保存主分片标记为0P,而节点2保存复制分片标记为0R,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应,这是有可能发生的。
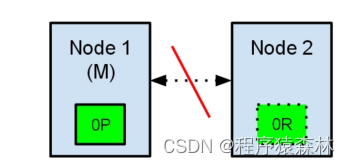
两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。在elasticsearch集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升Node2节点为主节点。

现在的集群在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
3)解决脑裂的方法
通过设置 elasticsearch.yml 中配置 discovery.zen.minimum_master_nodes 参数来解决。
这个参数的作用,就是告诉es直到有足够的master候选节点时,才可以选举出一个master,否则就选不出。这个参数必须被设置为集群中master候选节点的quorum数量,也就是大多数。至于quorum的算法,就是:master候选节点数量 / 2 + 1。
假如有10个节点都能维护数据,也可以是master候选节点,那么quorum就是10 / 2 + 1 = 6。
假如有3个master候选节点,还有100个数据节点,那么quorum就是3 / 2 + 1 = 2
假如有2个节点,都可以是master候选节点,那么quorum是2 / 2 + 1 = 2。此时就有问题了,因为如果一个node挂掉了,那么剩下一个master候选节点,是无法满足quorum数量的,也就无法选举出新的master,集群就彻底挂掉了。此时就只能将这个参数设置为1,但是这就无法阻止脑裂的发生了。
3个节点,discovery.zen.minimum_master_nodes设置为2,是如何避免脑裂的?
假如有3个节点,quorum是2。现在网络故障,1个节点在一个网络区域,另外2个节点在另外一个网络区域,不同的网络区域内无法通信。这个时候有两种情况情况:
(1)如果master是单独的那个节点,另外2个节点是master候选节点,那么此时那个单独的master节点因为没有指定数量的候选master node在自己当前所在的集群内,因此就会取消当前master的角色,尝试重新选举,但是无法选举成功。然后另外一个网络区域内的node因为无法连接到master,就会发起重新选举,因为有两个master候选节点,满足了quorum,因此可以成功选举出一个master。此时集群中就会还是只有一个master。
(2)如果master和另外一个node在一个网络区域内,然后一个node单独在一个网络区域内。那么此时那个单独的node因为连接不上master,会尝试发起选举,但是因为master候选节点数量不到quorum,因此无法选举出master。而另外一个网络区域内,原先的那个master还会继续工作。这也可以保证集群内只有一个master节点。
综上所述,集群中master节点的数量至少3台,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。














 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









