







一、项目背景
对淘宝用户行为进行分析,从而探索淘宝用户的行为模式,具体指标包括:日PV和日UV分析,付费率分析,复购行为分析,漏斗流失分析和用户价值RFM分布
二、数据来源
https://tianchi.aliyun.com/dataset/dataDetail?dataId=46&userId=1
三、提出问题
1.日PV有多少
2.日UV有多少
3.付费率情况如何
4.复购率是多少
5.漏斗流失情况如何
6.用户价值情况
四、理解数据
本数据集共有104万条左右数据,数据为淘宝APP2014年11月18日到2014年12月18日的用户行为数据,共计6列字段,列字段分别是:
user_id:用户身份,脱敏
item_id:商品ID,脱敏
behavior_type:用户行为类型(包含点击,收藏,加购物车,支付四种行为,分别用数字1、2、3、4表示)
user_geohash:地理位置
item_category:品类ID(商品所属的品类)
time:用户行为发生的时间
五、数据清洗
5.1导入python中的包
import pandas as pd
from matplotlib import pyplot as plt
import numpy as py
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
data_user = pd.read_csv(r'H:\python案例分析,淘宝\tianchi_mobile_recommend_train_user.csv')
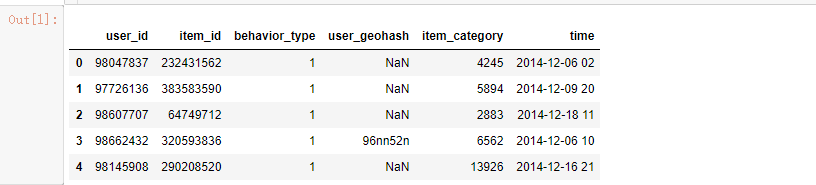
data_user.head()
读取前5行
看看一共有多少行的数据
data_user.shape
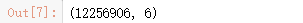
查看数据类型
data_user.info()

5.2缺失值处理
#缺失值处理
missingTotal=data_user.isnull().sum()
print(missingTotal)

可以看到user_geohash缺失值为8334824,而其他列不缺
这个缺失值,不能删除,因为有其他的关联信息,所以我们这里暂不处理
5.3数据处理。拆数据集

我们把日期和小时拆开,分成两列
拆分日期
#一致化处理
import re
#拆分数据集
data_user['date']=data_user['time'].map(lambda s:re.compile(' ').split(s)[0])
#这个S是data_user['time']的结果,然后通过map函数映射到lambda函数
拆分小时
data_user['hour']=data_user['time'].map(lambda s:re.compile(' ').split(s)[1])
#lambda只是一个表达式,没有函数体,lambda arg1,arg2,arg3,……:expression
#arg1,arg2,arg3表示具体的参数,expression表示参数要执行的操作
data_user.head()

可以看到已经拆分成两列了
下面讲解一下,这个re.compile()函数

5.4查看data_user数据集数据类型
data_user.dtypes
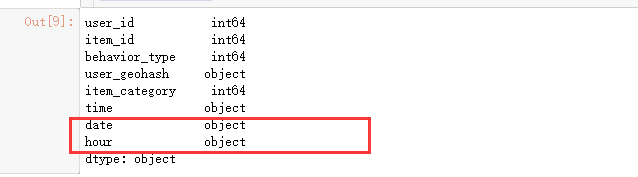
发现time列和date列应该转化为日期类数据类型,hour列应该是字符串数据类型
#数据类型化
data_user['date']=pd.to_datetime(data_user['date'])
data_user['time']=pd.to_datetime(data_user['time'])
data_user['hour']=data_user['hour'].astype('int64')
data_user.dtypes
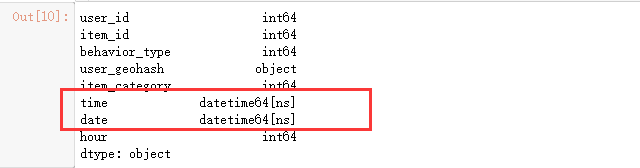
5.5异常值处理
data_user=data_user.sort_values(by='time',ascending=True)
data_user

data_user=data_user.reset_index(drop=True)
data_user

#异常值处理
data_user=data_user 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









