







介绍:
这篇文章主分析了红酒的通用数据集,这个数据集一共有1600个样本,11个红酒的理化性质,以及红酒的品质(评分从0到10)。这里主要用python进行分析,主要内容分为:单变量,双变量,和多变量分析。
注意:我们在分析数据之前,一定要先了解数据。
1.导入python中相关的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# 颜色
color = sns.color_palette()
# 数据print精度
pd.set_option('precision',3)
2.读取数据
注意:读取数据之前应该先看一下数据文件的格式,再进行读取
 我们看到这个数据使用‘;’进行分隔的,所以我们用‘;’进行分隔读取
我们看到这个数据使用‘;’进行分隔的,所以我们用‘;’进行分隔读取
pandas.read_csv(filepath, sep=’, ’ ,header=‘infer’, names=None)
filepath:文本文件路径;sep:分隔符;header默认使用第一行作为列名,如果header=None则pandas为其分配默认的列名;也可使用names传入列表指定列名
data=pd.read_csv(r'H:\阿里云\红酒数据集分析\winequality-red.csv',sep=';')
data.head()
先读取数据的前五行

然后我们也可以把这个整理好的数据,再另存为csv文件或者excel文件
data.to_csv(r'H:\阿里云\红酒数据集分析\winequality-red2.csv')
data.to_excel(r'H:\阿里云\红酒数据集分析\winequality-red3.xlsx')
winequality-red2.csv如图:
 winequality-red3.xlsx如图:
winequality-red3.xlsx如图:
 这样呢,我们就保存好了文件。这也是整理文件的一种方式
这样呢,我们就保存好了文件。这也是整理文件的一种方式
3.查看数据集的数据类型和空值情况等
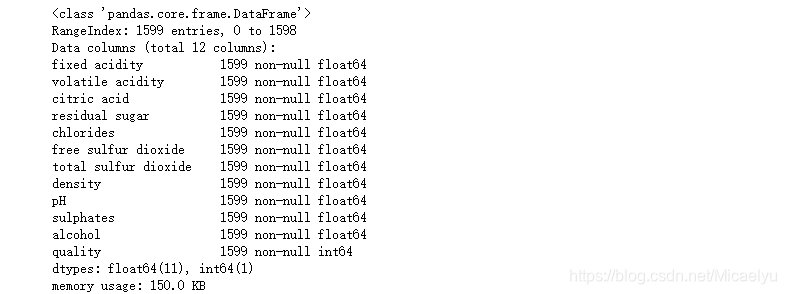
可以看出没有缺失值,数据整齐
4.单变量分析
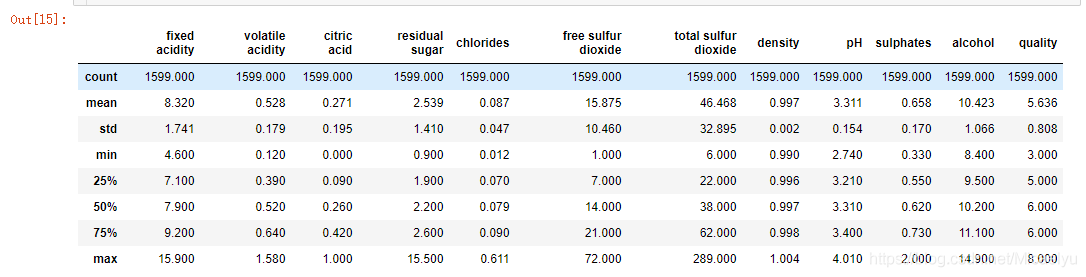
#简单的数据统计
data.describe()
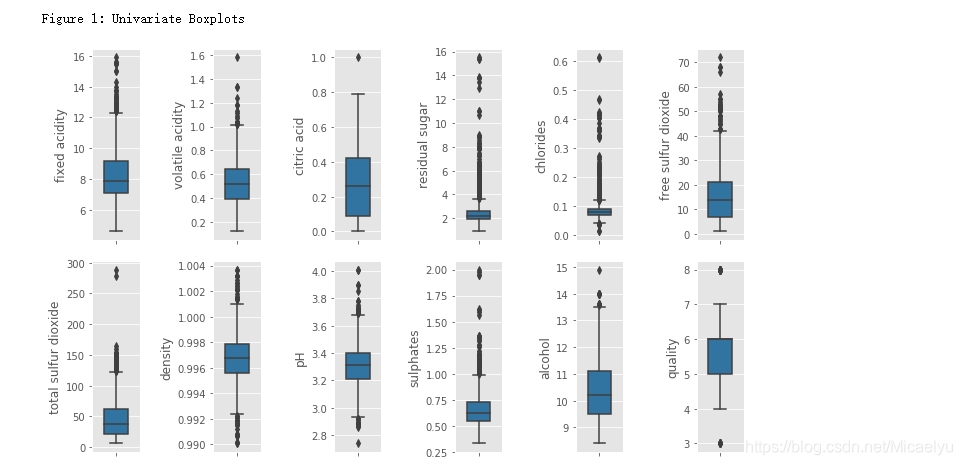
5.绘图
# 获取所有的自带样式
plt.style.available
# 使用自带的样式进行美化
plt.style.use('ggplot')
#获取所有列索引,并且转化成列表格式
colnm = data.columns.tolist()
fig = plt.figure(figsize = (10, 6))
for i in range(12):
#绘制成2行6列的图
plt.subplot(2,6,i+1)
#绘制箱型图
#Y轴标题
sns.boxplot(data[colnm[i]], orient="v", width = 0.5, color = color[0])
plt.ylabel(colnm[i],fontsize = 12)
#plt.subplots_adjust(left=0.2, wspace=0.8, top=0.9)
plt.tight_layout()
print('\nFigure 1: Univariate Boxplots')
colnm = data.columns.tolist()
plt.figure(figsize = (10, 8))
for i in range(12):
plt.subplot(4,3,i+1)
#data.hist绘制直方图
data[colnm[i]].hist(bins = 100, color = color[0])
plt.xlabel(colnm[i],fontsize = 12)
plt.ylabel('Frequency')
plt.tight_layout( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









