









前言
之前的文章中讲到了位图 BitMap(下文简称BM),大家应该被它的性能深深折服。在它适用的场景,无论是查询的时间复杂度O(1),还是存储的空间复杂度(理想情况下是int数组的1/32),都是无敌的存在。
既然性能如此的优越,为什么还有人说BM不好用呢?人无完人,技术亦是如此。在看到某种技术优点的同时,也要看到他的缺点。那么BM的缺点是什么呢?
BM最大的缺点恰恰也是空间的问题。如果使用位BM储10亿个连续的正整数,那么大约需要120M的空间,但是如果需要存储1和10亿两个数字,那么BM仍旧需要120M,而此时使用int数组则只需要8byte。
为什么会这样呢?这和BM的存储方式有关系,有兴趣了解或者需要先恶补知识的可以参考我之前BM相关的文章:面试以及大数据处理中的常客BitMap到底是个什么样子的存在?,这里就不多说了。
真是成也萧何败萧何,从上面的例子我们可以看出BM适合连续密集的正整数存储,对于稀疏的正整数存储,其性能在很多时候是没办法和int数组相比的,尤其是正整数跨度较大的场景。
由于业务场景和需求的复杂性,上述的弱点显然极大的限制了BM的发展,使用场景大大受限。话说哪里有压迫,哪里就有反抗,在各路大神的加持下,BM的升级进化版本 RoaringBitmap(下文简称RBM)诞生了。
正文
什么是 RoaringBitmap
到底什么是RBM,这里直接引用网上的定义:
Roaring bitmaps are compressed bitmaps. They can be hundreds of times faster.
从上述的定义可以看出,RBM还是使用到了BM,只是在位图的的基础上进化成了高效压缩位图,从而达到了高性能以及更广泛的使用场景。
RoaringBitmap 的代码结构
下面先来看看RBM的代码结构:
首先先说一下,下面的代码讲解都是基于java版本的RBM实现,其他语言应该也有类似的开源实现,但是原理是一样的,可以通过下面的讲解先了解下具体的实现机制。
先留下java版本的RBM的maven依赖:
<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>0.9.30</version>
</dependency>
接下来看看两张类图:
第一张类图是RBM的入口类 RoaringBitmap 的结构,除了因为各种功能以及需求而实现的各种接口外,主要关注下该类的 highLowContainer 属性,RoaringBitmap 的绝大数据的操作就是基于这个属性展开的。
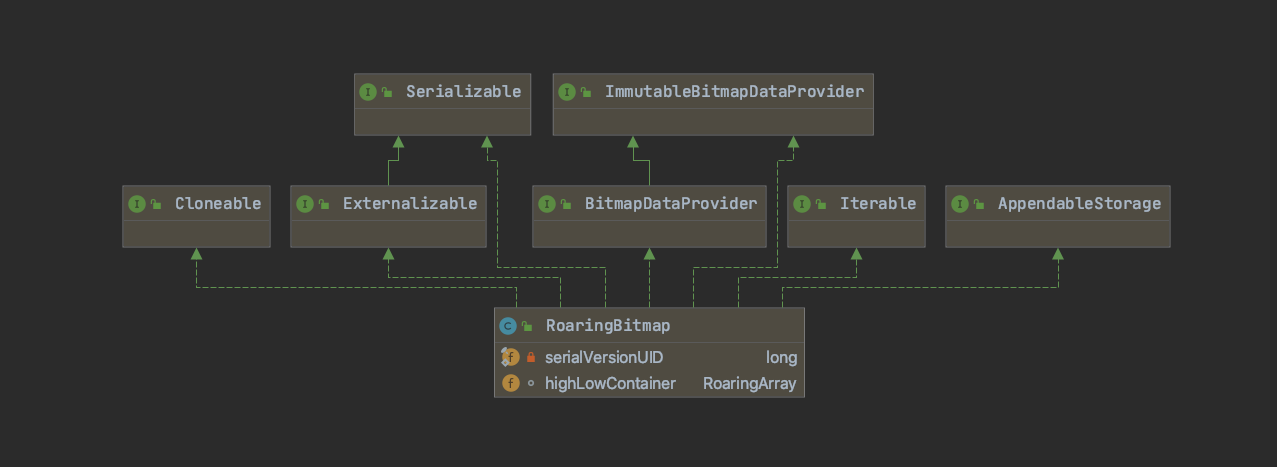
第二张类图则是 highLowContainer 中维护和操作的各种 container,这些 containers 支撑起了整个RBM的体系,也是奇迹产生的地方。

RoaringBitmap 的数据结构
接下来再来看看RBM的数据结构:

首先先讲一下RBM的实现原理,然后再通过这个数据结构图来解释下RBM是如何存取数据的。RBM的实现原理如下:
-
将 32bit int(无符号的)类型数据 划分为 2^16 个桶,即最多可能有65536个桶(即 container ),每个桶最多(此处注意最多这个词,下文会详细讲解)存放2^16 即65536个数值,那么所有的桶存放的数值正好就是2^32即32位无符号整数的全体值。
-
在存储和查询数值时,将数值 k 划分为高 16 位和低 16 位,取高 16 位值找到对应的桶,然后在将低 16 位值存放在相应的 Container 中(存储时如果找不到就会新建一个)
-
Container分为三类,描述可以参照图中的文字,这三类 Container 就构成了RBM存储和查询的基础,在不同场景下使用不同的 Container,下面将详细讲解。
下面就使用将921插入到RBM的例子来具体说说RBM的写入和读取过程来具象化上面的实现原理:
-
按照上面的原理将32位的无符号int拆分成高16位和低16位分开处理,这个如果大家感觉很麻烦的话,可以理解为将需要处理的int值按65536取模,模值即为高16位的值,而余数就是低16位的值
-
回到921这个值,按照65536取模后,得到高16位就是0,而低16位就是921,即在图中921会被放在0号桶中
-
但是在0号桶中怎么存储和读取这就是RBM的核心逻辑了,图片中使用了 ArrayContainer 存储是便于大家理解,实际存储过程中会根据实际情况来选择和转换,下面的章节会详细讲解
-
查询的道理其实和存储是一样的,存储是找到合适的地方用合适的方式将数据存储起来;而查询则是找到对的地方用合适的方式将处理后的数据转码成原始数据并将数据返回,大家思考下就明白了
最后,理论上BM能解决的问题,RBM都能解决。只是在某些适合使用BM的场景可以直接使用BM,毕竟BM的实现和使用成本还是低于RBM的。下面就来看看RBM是如何给BM查缺补漏的。
RoaringBitMap 是如何解决Bitmap的短板
扬长避短
RBM出于BM,而胜于BM。既然出于BM,那肯定是继承了BM的优点,然后改正了BM的缺点。
听起来很复杂,其实就是在适合使用BM的时候使用BM,不适合使用BM的时候使用其他合适的数据结构存储数据。这个问题的答案同样也是上文中当一个数据写入到RBM时到底使用哪种 Container 来存储数据这个问题的答案。
回到本文开头,我们已经说过了,BM适合于大量密集数据的存储,而int数组适合于少量稀疏数据的存储。于是RBM决定各取所长,根据数据的特点在不同情况下采取不同的存储方式。
这是个好主意,扬长避短,但是问题也随之而来,评判的标准是什么?什么时候使用位图即 BitmapContainer 存储,什么时候使用数组即 ArrayContainer 存储?
这个问题说复杂也复杂,说简单也简单,最后RBM使用了数据大小来作为评判标准,于是就有了下面的处理逻辑:
-
首先当一个桶被创建时,第一个元素一定会被放在 ArrayContainer 中存储,因为此时的数据是绝对的稀疏
-
然后后续的数据被放入到该桶时,RBM会计算 ArrayContainer 的数值个数,当数值个数超过4096时,就会将 ArrayContainer 转化为 BitmapContainer 存储,而超过4096即是RBM认为的数据密集的阈值
为什么是4096
看到上面的处理逻辑,大家可能会感到疑惑,为什么会选择4096这个阈值呢?其实也很简单,看下面这张图:
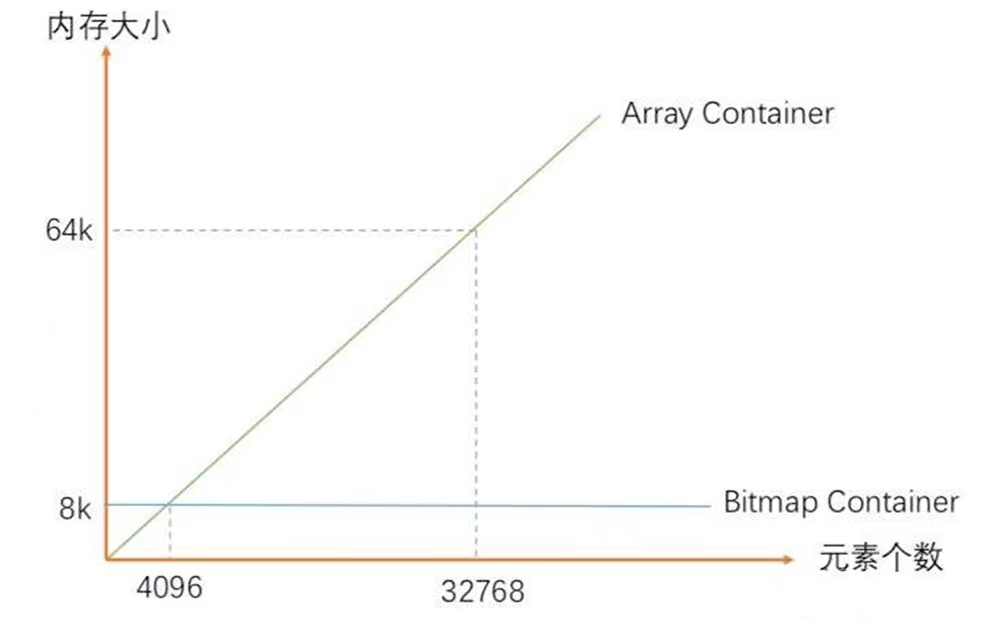
从上图可以看出 ArrayContainer 和 BitmapContainer 的内存占用随元素个数增加的变化曲线。理论上来说两条线的交点就是整个临界点,在这个点之前 ArrayContainer 占用的内存更少;在此之后 BitmapContainer 空间占用更有优势。
上图中 ArrayContainer 的大小随元素个数的增加线性增长;而 BitmapContainer 则恒定为8KB。所以8KB就是临界点,而8KB对应的ArrayContainer存储的数据量恰恰是4096(存储的是无符号的short类型数据,一个2 byte),这就是4096这个阈值的来历。
上面的例子和处理方式是不是很眼熟?没错,另一个我们常用的数据结构HashMap也有类似的骚操作,那就是为了保证查询的时间复杂度保持为O(logN)而非O(N),HashMap也有在数据长度超过一定数量后将链表转化为红黑树的操作。可见为了保持在所有场景的性能,这种操作已经慢慢变成常规操作了。
RunContainer 去哪里了
上面热热闹闹的讲解了ArrayContainer 和 BitmapContainer,大家却没有发现 RunContainer 的影子? RunContainer 去哪里了呢?
首先先看看 RunContainer 的实现原理:
RunContainer 中的Run指的是行程长度压缩算法(Run Length Encoding),对连续数据有比较好的压缩效果。它的原理是,对于连续出现的数字,只记录初始数字和后续数量。即:
-
对于数列11,它会压缩为11,0;
-
对于数列11,12,13,14,15,它会压缩为11,4;
-
对于数列11,12,13,14,15,21,22,它会压缩为11,4,21,1;
上面的回答只是解释了 RunContainer 的实现原理,并没有揭开 RunContainer 的消失之谜。最后还得求助于源码,看过源码以后发现,其实RBM中常用的是ArrayContainer 和 BitmapContainer,而 RunContainer 是非常规的 Container,只有在手动调用runOptimize()方法的时候才会产生。来看下源码:
/**
* Use a run-length encoding where it is more space efficient
*
* @return whether a change was applied
*/
public boolean runOptimize() {
boolean answer = false;
for (int i = 0; i < this.highLowContainer.size(); i++) {
Container c = this.highLowContainer.getContainerAtIndex(i).runOptimize();
if (c instanceof RunContainer) {
answer = true;
}
this.highLowContainer.setContainerAtIndex(i, c);
}
return answer;
}
这段源码就是runOptimize()方法的实现,它主要是循环调用 highLowContainer 中所有 Container 的runOptimize()方法,对 Container 进行优化,然后将优化后的 Container 放回 highLowContainer 中。
@Override
public Container runOptimize() {
int numRuns = numberOfRunsLowerBound(MAXRUNS); // decent choice
int sizeAsRunContainerLowerBound = RunContainer.serializedSizeInBytes(numRuns);
if (sizeAsRunContainerLowerBound >= getArraySizeInBytes()) {
return this;
}
// else numRuns is a relatively tight bound that needs to be exact
// in some cases (or if we need to make the runContainer the right
// size)
numRuns += numberOfRunsAdjustment();
int sizeAsRunContainer = RunContainer.serializedSizeInBytes(numRuns);
if (getArraySizeInBytes() > sizeAsRunContainer) {
return new RunContainer(this, numRuns);
} else {
return this;
}
}
下面这个源码就是 BitmapContainer 的 runOptimize() 方法,里面可以明显的看到new RunContainer 的方法,显然是在实例化 RunContainer。
所以,RunContainer 默认是不存在的,只有在需要的时候手动调用才会产生。为什么这样呢?其实这是因为 RunContainer 的优缺点更明显,甚至比BM更明显:
这种压缩算法的性能和数据的连续性(紧凑性)关系极为密切,对于连续的100个short,它能从200字节压缩为4字节,但对于完全不连续的100个short,编码完之后反而会从200字节变为400字节。
如果要分析 RunContainer 的容量,我们可以做下面两种极端的假设:
-
最好情况,即只存在一个数据或只存在一串连续数字,那么只会存储2个short,占用4字节
-
最坏情况,0~65535的范围内填充所有的奇数位(或所有偶数位),需要存储65536个short,128kb
总结
上文详细讲解了 RoaringBitmap 的实现原理以及使用方法,可以看到RBM在继承了BM的优点以后,同时改进了BM的缺点,使得RBM的使用场景大大拓展了。于是各个大数据组件,包含但不限于 Spark、HIVE、Lucene的底层大量采用RBM-like的实现方式来解决各种性能问题。
可以预见的是,将来RBM的使用场景会越来越广阔,而这种设计以及实现方式也会成为我们在未来功能设计以及代码编写提供良好的思路。
文章到这里就结束了,最后路漫漫其修远兮,大数据之路还很漫长。如果想一起大数据的小伙伴,欢迎点赞转发加关注,下次学习不迷路,我们在大数据的路上共同前进!














 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









