







Task5 文本表示
- 词袋模型:离散、高维、稀疏。
- 分布式表示:连续、低维、稠密。word2vec词向量原理并实践,用来表示文本。
- word2vec1 word2vec
- word2vec 中的数学原理详解(一)目录和前言 - peghoty - CSDN博客 https://blog.csdn.net/itplus/article/details/37969519
- word2vec原理推导与代码分析-码农场 http://www.hankcs.com/nlp/word2vec.html
一、 词袋模型:离散、高维、稀疏
离散:无法衡量词向量之间的关系。比如酒店、宾馆、旅社三者都只在某一个固定的位置为 1 ,所以找不到三者的关系,各种度量(与或非、距离)都不合适,即太稀疏,很难捕捉到文本的含义。
高维:词表维度随着语料库增长膨胀,n-gram 序列随语料库膨胀更快。
数据稀疏: 数据都没有特征多,数据有 100 条,特征有 1000 个
二、文本表示
文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。文本表示是自然语言处理的开始环节。
文本表示按照细粒度划分,一般可分为字级别、词语级别和句子级别的文本表示。
文本表示分为离散表示(离散、高维、稀疏)和分布式表示(连续、低维、稠密)。离散表示的代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。分布式表示也叫做词嵌入(word embedding),经典模型是word2vec,还包括后来的Glove、ELMO、GPT和最近很火的BERT。
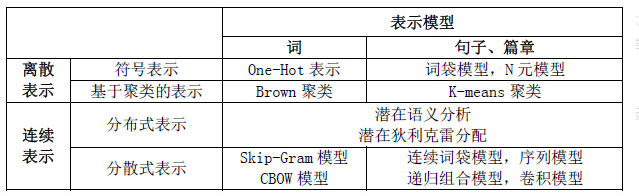
1.从one-hot 到word2vec
(1)One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
优点: 解决了分类器不好处理离散数据的问题,并且在一定程度上也起到了扩充特征的作用。
缺点: 在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。更大的问题是其不满足我们前面的期望——相似的词的距离较近而不相似的较远。对于one-hot向量来说,相同的词距离是0,而不同的词距离是1。这显然是有问题的,因为cat和dog的距离肯定要比cat和apple要远。但是在one-hot的表示里,cat和其它任何词的距离都是1。
下面是参考文献1的三段代码:
手动One-hot编码
from numpy import argmax
# define input string
data = 'hello world'
print(data)
# define universe of possible input values
alphabet = 'abcdefghijklmnopqrstuvwxyz '
# define a mapping of chars to integers
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
int_to_char = dict((i, c) for i, c in enumerate(alphabet))
# integer encode input data
integer_encoded = [char_to_int[char] for char in data]
print(integer_encoded)
# one hot encode
onehot_encoded = list()
for value in integer_encoded:
letter = [0 for _ in range(len(alphabet))]
letter[value] = 1
onehot_encoded.append(letter)
print(onehot_encoded)
# invert encoding
inverted = int_to_char[argmax(onehot_encoded[0])]
print(inverted)基于sklearn
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
# define example
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = array(data)
print(values)
# integer encode
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded)
# binary encode
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
# invert first example
inverted = label_encoder.inverse_transform([argmax(onehot_encoded[0, :])])
print(inverted)基于keras
from numpy import array
from numpy import argmax
from keras.utils import to_categorical
# define example
##对字符串
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = array(data)
print(values)
# integer encode
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded)
##对数值
#data=[1, 3, 2, 0, 3, 2, 2, 1, 0, 1]
#data=array(data)
#print(data)
# one hot encode
encoded = to_categorical(integer_encoded)
print(encoded)
# invert encoding
inverted = argmax(encoded[0])
print(inverted)(2)word2vec,是为了解决上述缺陷而提出的方法。其实这基于Firth 教授在1957年提出一个分布式语义的假设,即A word’s meaning is given by the words that frequently appear close-by (一个词的语义是由它周围经常出现的词决定的)。 word2vec的本质就是求词向量的框架。这里对于每一个词用一个低纬度的稠密向量来表示,词是由所有维度共同表示,单独一维并没有的独立的含义。
word2vec模型其实就是简单化的神经网络。既然是神经网络,那么就有对应的输入层,隐层与输出层。输入就是上边提到的One-Hot Vector,隐层没有激活函数,只是线性的单元。输出层维度跟输入层一样,用的是Softmax回归。当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
那么这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
- CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。CBOW是通过目标单词的语境推测出可能出现的单词。
- Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。Skip-Gram model是通过目标单词推测语境,在大规模的数据集中Skip-Gram model训练速度快
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。两种都采用了滑动窗口,前者是用窗口内的其他词去预测中心词,而后者则是用中心词去预测窗口的其他词。现实中,两者的效果接近。
算法流程:
第一步:将one-hot形式的词向量输入到单层神经网络中,其中输入层的神经元结点个数应该和one-hot形式的词向量维数相对应。比如,输入词是“夏天”,它对应的one-hot词向量[0,0,1],那么,我们设置输入层的神经元个数就应该是3。
第二步:通过神经网络中的映射层中的激活函数,计算目标单词与其他词汇的关联概率,其中在计算时,使用了负采样(negative sampling)的方式来提高其训练速度和正确率
第三步:通过使用随机梯度下降(SGD)的优化算法计算损失
第四步:通过反向传播算法将神经元的各个权重和偏置进行更新
所以,word2vec实质上是一种降维操作,将one-hot形式的词向量转化为word2vec形式。
参考博客:















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









