



Training dynamic
loss (损失函数)
在机器学习和深度学习中,Loss(损失函数)是衡量模型预测结果与真实标签之间差异的函数。它是模型优化的目标,通过最小化损失函数来调整模型参数,从而提高模型的性能。
损失函数的作用
- 量化误差:损失函数将模型的预测值与真实值之间的差异转化为一个具体的数值。
- 指导优化:通过计算损失函数的梯度,优化算法(如梯度下降)可以更新模型参数,使损失函数值逐渐减小。
loss爆炸的因素
-
学习率过高:如果学习率设置得太大,模型在更新参数时可能会跳过最优解,导致损失值急剧增加。
-
梯度消失或爆炸:在深层网络中,梯度在反向传播过程中可能会变得非常小(消失)或非常大(爆炸),这会影响参数的更新,导致损失不稳定。
-
权重初始化不当:如果模型参数的初始值设置不当,可能会导致某些层的输出过大或过小,进而影响梯度的计算,导致损失爆炸。
-
数据预处理问题:如果输入数据没有进行适当的归一化或标准化,可能会导致某些特征对损失函数的影响过大,从而引起损失爆炸。(可以简单的理解为数据被污染了)
-
模型复杂度:过于复杂的模型可能会在训练过程中产生过拟合现象,导致损失函数在训练集上表现良好但在验证集上表现不佳,甚至出现损失爆炸。
学习率衰减 Learning rate decay
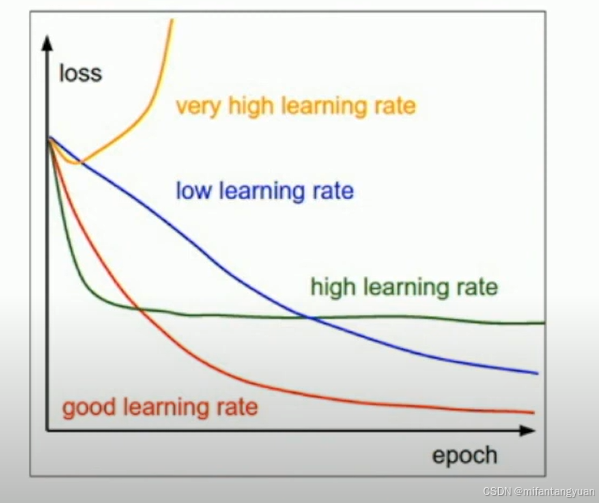
分步方案 (最常用的方案)
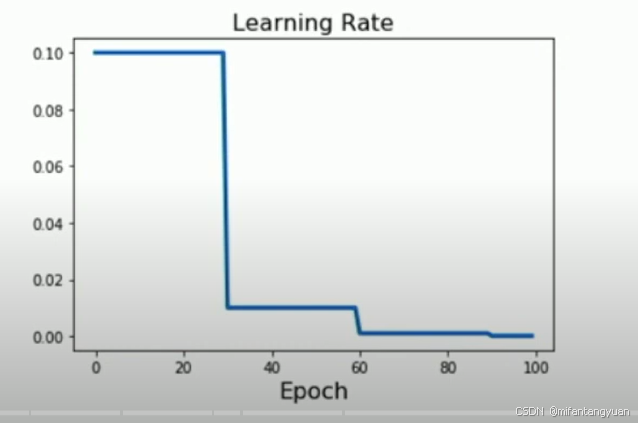
相对的训练损失
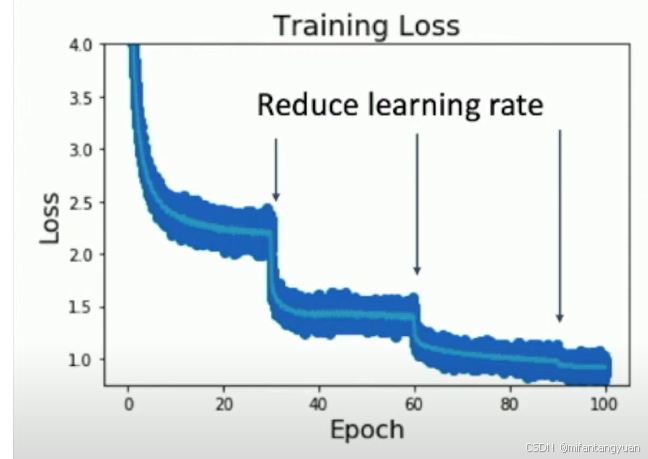
通过观察可知,当loss梯度基本消失时(即难以优化时)改变学习速度
余弦学习率衰减
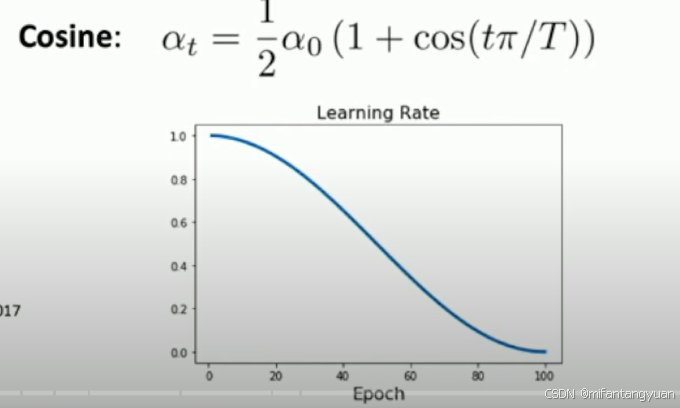
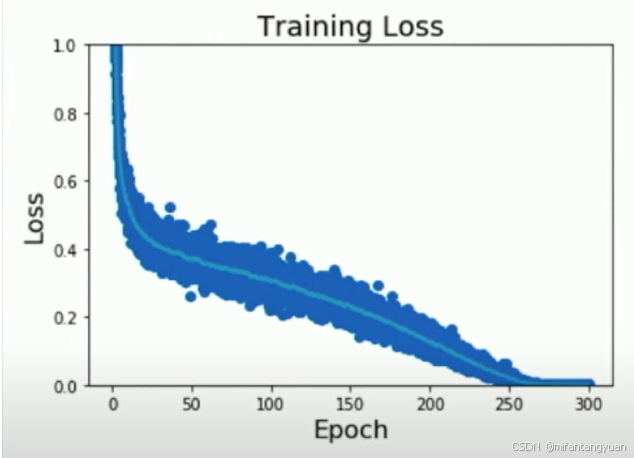
优势:比分步方案超参数少
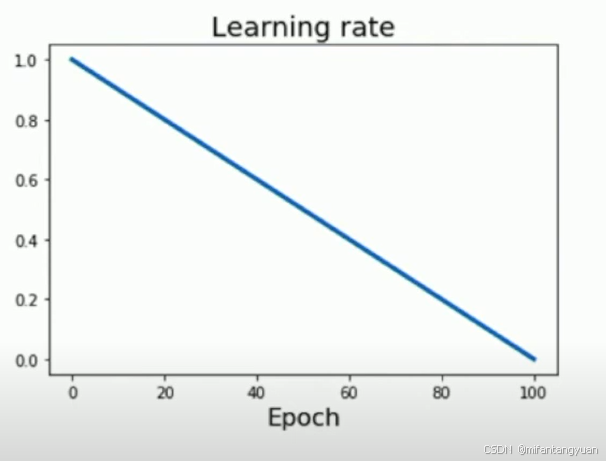
线性 Linear
![]()
反平方根 Inverse Sqrt
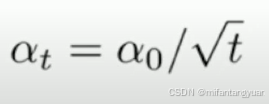
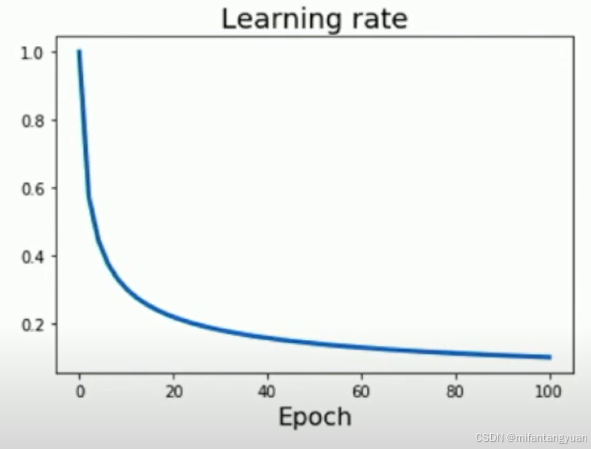
缺点:模型在初始高学习率阶段所消耗的时间很少。
常数 Constant
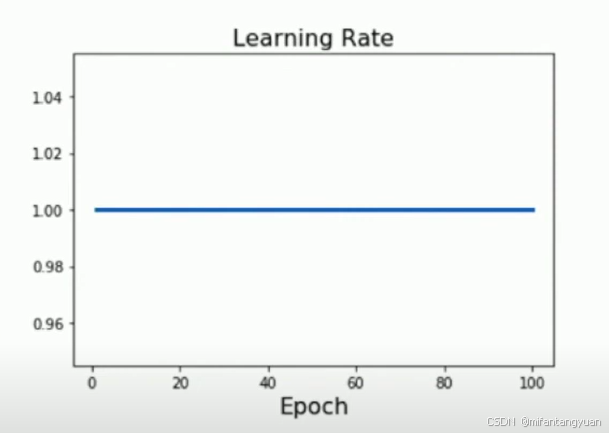
大道至简,意外好用
配合Adam优化器食用更佳
Adam优化器
Adam优化器(Adaptive Moment Estimation)是一种常用的优化算法,广泛应用于深度学习模型的训练中。它结合了动量法(Momentum)和RMSProp的优点,能够自适应地调整学习率,从而在训练过程中更高效地更新模型参数。
核心思想
- 动量法:Adam利用了动量法的思想,通过累积梯度的指数加权平均来加速收敛,减少震荡。
- 自适应学习率:Adam借鉴了RMSProp的思想,通过计算梯度平方的指数加权平均来调整每个参数的学习率,从而适应不同参数的更新需求。
公式
Adam的更新规则如下:
- 计算梯度的一阶矩估计(均值):
- 计算梯度的二阶矩估计(未中心化的方差):
- 对一阶矩和二阶矩进行偏差修正(因为初始值为0):
- 更新参数:
其中:- ( g_t ) 是当前时间步的梯度。
- ( m_t ) 和 ( v_t ) 分别是梯度的一阶矩和二阶矩估计。
- (
) 和 (
) 是超参数,通常取值为 (
- (
) 是学习率。
- (
) 是一个很小的常数(如
),用于防止分母为零。
优点
- 自适应学习率:Adam能够为每个参数自适应地调整学习率,适合处理稀疏梯度或非平稳目标函数。
- 高效收敛:结合动量和自适应学习率,Adam通常能够快速收敛。
- 鲁棒性强:对超参数的选择相对不敏感,适合大多数深度学习任务。
缺点
- 内存占用较高:需要存储每个参数的一阶矩和二阶矩估计,内存消耗较大。
- 可能陷入局部最优:在某些情况下,Adam可能会收敛到次优解
训练停止时间
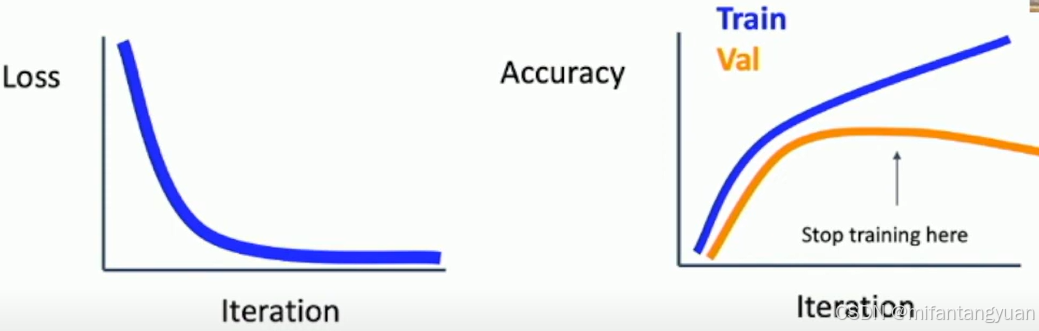
在模型在 验证集(val)中表现未明显改善或劣化时停止
hyperparmeter optimization
超参数是在机器学习模型训练之前需要手动设置的参数,它们不通过训练数据学习得到。
网格搜索 Grid Search
原理
- 定义超参数空间:为每个超参数指定一组候选值。
- 遍历所有组合:对超参数的所有可能组合进行穷举搜索。
- 评估模型性能:对每个组合训练模型,并使用验证集评估性能(如准确率、F1分数、均方误差等)。
- 选择最优组合:选择性能最好的超参数组合作为最终模型配置
优点:
全面性:穷举所有可能的超参数组合,确保找到全局最优解。
易于实现:许多机器学习库(如Scikit-learn)提供了内置的网格搜索工具。
缺点:
计算成本高:当超参数数量多或候选值范围大时,计算量会指数级增长。
效率低:对于连续型超参数,网格搜索可能无法精确找到最优值。
优化方法
-
随机搜索(Random Search):
从超参数空间中随机采样组合,而不是穷举所有组合。
适用于超参数空间较大的情况。 -
贝叶斯优化(Bayesian Optimization):
使用概率模型指导超参数搜索,更高效地找到最优解。 -
HalvingGridSearchCV:
Scikit-learn提供的一种高效网格搜索方法,通过逐步淘汰表现较差的组合来减少计算量。
随机搜索 Random Search
原理
- 定义超参数空间:为每个超参数指定一个分布(如均匀分布、对数均匀分布等)。
- 随机采样组合:从超参数空间中随机采样一定数量的组合。
- 评估模型性能:对每个采样组合训练模型,并使用验证集评估性能。
- 选择最优组合:选择性能最好的超参数组合作为最终模型配置。
优点:
高效:在超参数空间较大时,随机搜索比网格搜索更快找到较优解。
灵活性:可以定义连续型超参数的分布(如均匀分布、对数均匀分布)。
计算成本低:只需评估少量组合,适合资源有限的情况。
缺点:
不完全遍历:可能错过某些最优组合,尤其是超参数空间较小的情况。
随机性:结果可能因随机采样不同而有所波动。
随机搜索的优化方法
- 增加采样次数:增加
n_iter可以提高找到最优解的概率,但会增加计算成本。 - 结合网格搜索:先用随机搜索缩小超参数范围,再用网格搜索精细调参。
- 贝叶斯优化:在随机搜索的基础上,使用概率模型指导采样,进一步提高效率。
使用场景
- 超参数空间较大:当超参数数量多或候选值范围大时,随机搜索比网格搜索更高效。
- 资源有限:在计算资源有限的情况下,随机搜索可以快速找到较优解。
- 初步调参:在模型开发的早期阶段,可以使用随机搜索快速找到一组较好的超参数。
随机搜索 vs 网格搜索
| 特性 | 网格搜索(Grid Search) | 随机搜索(Random Search) |
|---|---|---|
| 搜索方式 | 穷举所有组合 | 随机采样组合 |
| 计算成本 | 高 | 低 |
| 适用场景 | 超参数空间较小 | 超参数空间较大 |
| 灵活性 | 只能定义离散值 | 可以定义连续分布 |
| 结果稳定性 | 稳定 | 可能因随机采样不同而波动 |
选择超参数流程
1. 检查初始损失:首先,关闭权重衰减(一种防止模型过拟合的技术),在模型初始化时检查损失值。对于使用softmax函数的多分类问题(C个类别),初始损失应该接近log(C)。这一步是为了确保模型在开始训练前的状态是合理的。
2. 过拟合小样本:接下来,使用一小部分训练数据(5-10个小批次)进行训练,目标是让模型在这些数据上达到100%的准确率。在这个过程中,可以调整模型的结构、学习率和权重初始化方法,并关闭正则化(如权重衰减)。如果损失没有下降,可能是因为学习率设置不当:学习率太低会导致损失下降缓慢,而学习率太高可能导致损失值爆炸(变为无穷大或NaN)。
3. 找到合适的学习率:使用上一步确定的模型结构,打开少量的权重衰减,并使用全部训练数据。尝试不同的学习率(如1e-1, 1e-2, 1e-3, 1e-4),找到一个能在约100次迭代内显著降低损失的学习率。
4. 粗略网格搜索:在确定了初步的学习率后,进行粗略的网格搜索,训练模型1-5个周期(epochs),观察模型的表现。
5. 细化网格搜索:在粗略搜索的基础上,进一步细化学习率的范围,并延长训练时间,以找到更优的学习率。
6. 观察学习曲线:最后,通过观察训练和验证损失曲线,评估模型的训练效果,判断是否存在过拟合或欠拟合,并据此调整模型参数。
7. 回到第5步
模型集成
-
传统方法:训练多个独立模型。
-
新方法:快照集成(Snapshot Ensemble):在训练过程中使用单个模型的多个快照。
学习率调度策略
-
标准学习率调度:学习率随时间逐渐降低。
-
循环学习率调度:学习率周期性变化,先降低后升高,形成循环。
提示和技巧
训练多个独立模型
保持参数向量的移动平均并在测试时使用它,而不是使用实际的参数向量(Polyak平均法)
迁移学习 Transfer Learning
-
迁移学习是一种技术,它允许将在一个任务上训练的模型应用于另一个不同的任务。
CNN特征提取
-
CNN在大型数据集(如ImageNet)上预训练,以学习通用的特征表示。
-
预训练的CNN可以用作新任务的特征提取器。
CNN结构组件
-
全连接层(FC):用于分类或其他任务的输出层。
-
卷积层(Conv):用于提取图像特征。
-
池化层(MaxPool):用于降低特征的空间维度,减少计算量。
迁移学习步骤
-
移除最后一层:在新任务中,通常移除预训练CNN的最后一层。
-
冻结前面层:在训练新任务时,冻结CNN的前面层以保留预训练的特征。
模型微调
-
在迁移学习中,可以对CNN的最后几层进行微调,以适应新任务。
分类性能
-
在Caltech-101数据集上的实验表明,使用CNN特征提取的分类方法随着训练样本的增加而提高准确率。
正则化技术
-
Dropout:一种正则化技术,用于减少过拟合。
-
逻辑回归(LogReg)和支持向量机(SVM):两种不同的分类器,可以与Dropout结合使用。
性能比较
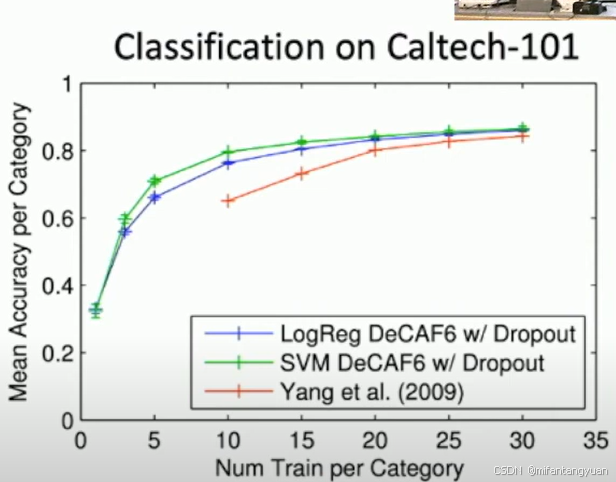
比较不同方法在Caltech-101数据集上的性能,显示了随着每个类别训练样本数量的增加,分类准确率的提高。
质疑
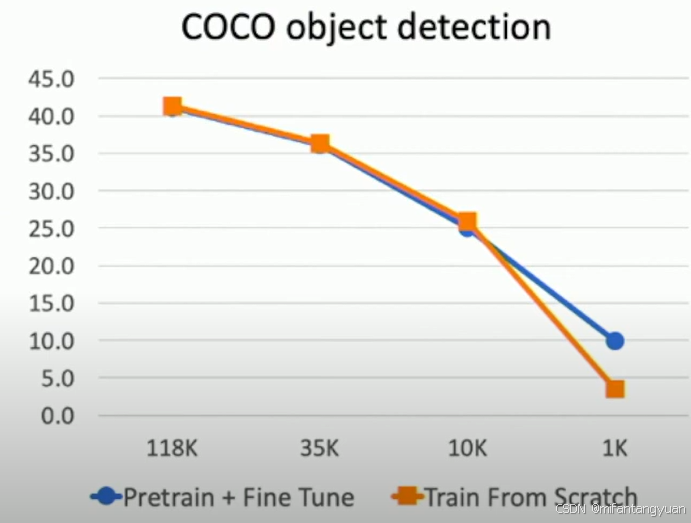
-
图表中的橙色线(迁移学习)在数据集较小时(118K)表现较好,但随着数据集增大(10M),蓝色线(从头开始训练)的性能提升更快,最终超过了迁移学习的性能。
存在迁移学习效果不如直接训练
结论
-
预训练+微调:这种方法可以加快训练速度,因此在实践中非常有用。
-
迁移学习在数据集较小的情况下可能更有优势,但在有大量数据的情况下,从头开始训练可能更有效。
-
迁移学习领域仍有待进一步研究和探索。
分布式训练 Distributed Training
想法1:在不同的gpu上运行不同的层
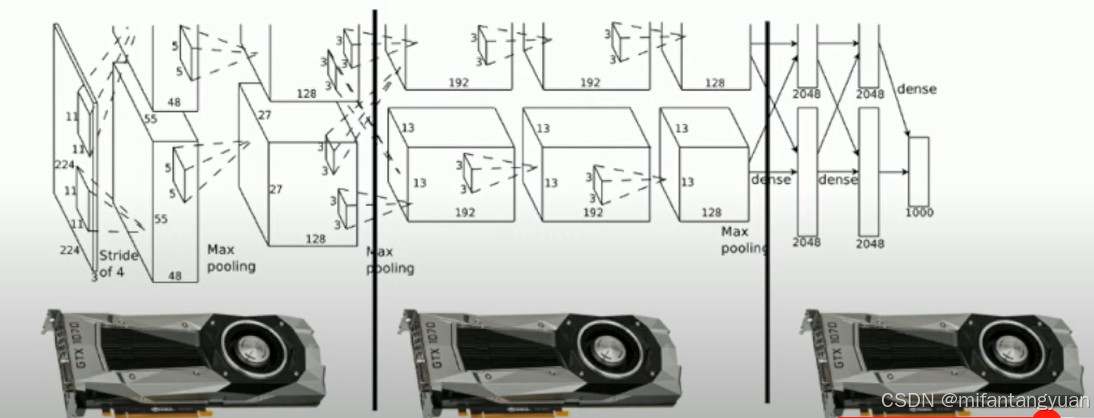
问题:GPU有很长时间闲置
想法2:在不同的gpu上运行模型的并行分支

问题:跨gpu同步是昂贵的:涉及到大量的数据传输和协调工作
需要沟通激活和损失梯度
想法3:数据并行 在多个处理器或计算节点上同时处理不同数据子集
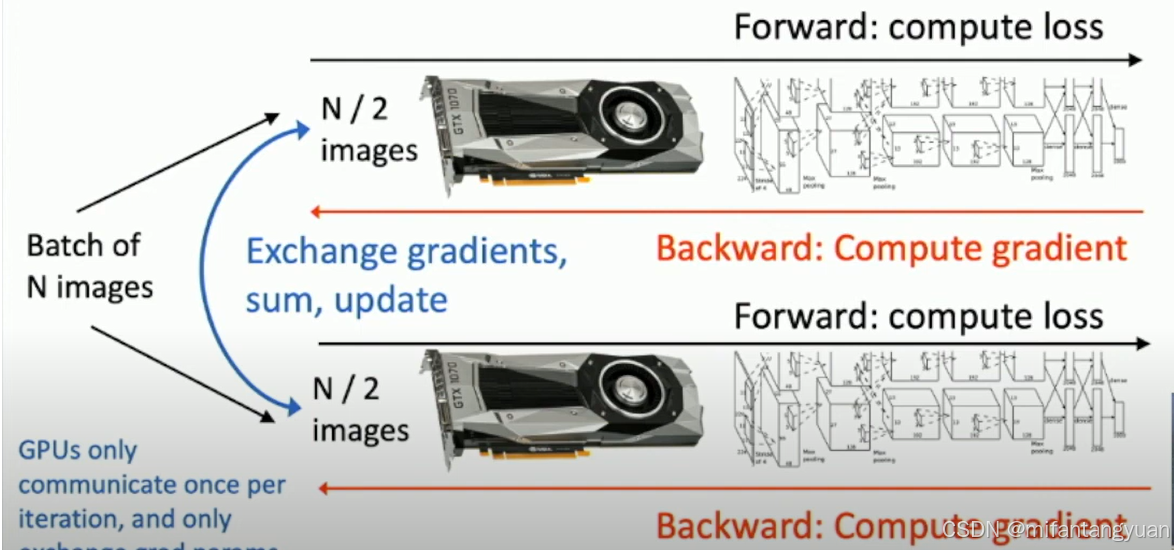 4
4
向末端传播loss
像前端传播梯度
gpu在每次迭代中只通信一次,并且只交换梯度grad参数
YOLO可以这么用
大批次训练 Large-Batch Training
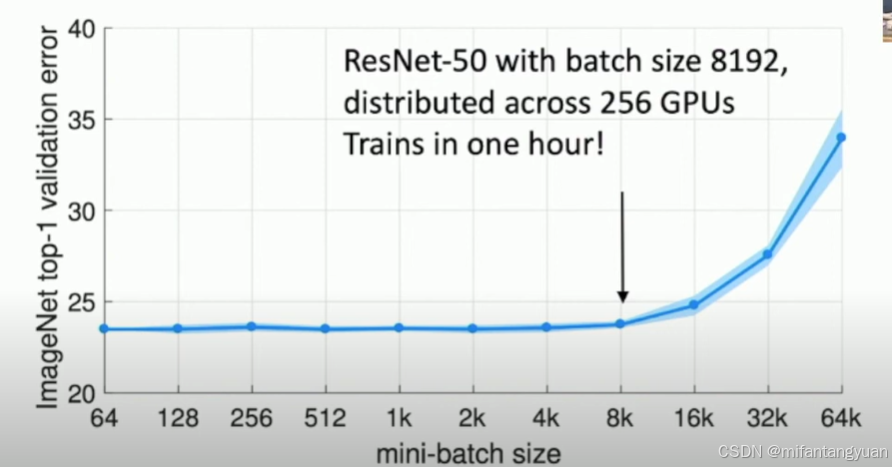
GPU数量越多,速度越快
军备竞赛


















 4518
4518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









