







体脂率预测分析
一、项目概述
1.1 研究背景
体脂率是评估人体健康状况的重要指标,过高的体脂率与多种慢性疾病风险相关,如心血管疾病、糖尿病和高血压等。然而,精确测量体脂率通常需要专业设备(如水下称重法、DEXA扫描等),这些方法成本高且不便于大规模应用。
本项目旨在通过分析人体测量数据(如身高、体重、各部位围度等),建立一个准确的体脂率预测模型,使人们能够通过简单易得的测量数据估算体脂率,从而评估健康状况并制定相应的健康管理计划。
1.2 研究目标
- 分析人体测量指标与体脂率之间的关系
- 确定影响体脂率的关键因素
- 构建高精度的体脂率预测模型
- 提供可视化分析结果,便于理解和应用
1.3 数据集介绍
本研究使用的数据集包含252名男性的体脂率及相关身体测量数据,具体包括:
- 基准测量:通过水下称重法测得的身体密度和计算得到的体脂率
- 基本信息:年龄、体重、身高
- 身体围度测量:颈围、胸围、腹围、臀围、大腿围、膝围、踝围、二头肌围、前臂围和腕围
二、分析方法与技术路线
2.1 技术路线概述
本项目采用以下技术路线进行体脂率预测分析:
- 数据预处理:数据清洗、异常值处理、特征工程
- 探索性数据分析:统计描述、相关性分析、数据可视化
- 模型构建:多种回归模型训练与比较
- 模型评估:交叉验证、性能指标分析
- 结果可视化:使用Echarts生成高分辨率可视化图表
2.2 使用的技术与工具
- 编程语言:Python 3.x
- 数据处理:Pandas, NumPy
- 机器学习:Scikit-learn
- 可视化工具:Matplotlib, Seaborn, Pyecharts
- 模型存储:Joblib
三、数据预处理
3.1 数据清洗
数据清洗是确保模型质量的关键步骤,主要包括:
- 缺失值处理:检查并处理数据集中的缺失值
- 异常值检测:使用IQR(四分位距)方法识别异常值
- 数据一致性检查:确保数据在合理范围内,如体脂率在3%-45%之间
# 使用IQR方法检测异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
outliers = ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
# 检查体脂率的合理范围
bodyfat_outliers = df[(df['BodyFat'] < 3) | (df['BodyFat'] > 45)]
3.2 特征工程
为提高模型性能,我们创建了以下新特征:
- BMI(体质指数):体重(kg) / 身高(m)²
- WHR(腰臀比):腹围 / 臀围
- WHtR(腰围身高比):腹围 / 身高
# BMI计算
height_m = df['Height'] * 0.0254 # 英寸转米
weight_kg = df['Weight'] * 0.4536 # 磅转千克
df['BMI'] = weight_kg / (height_m ** 2)
# 腰臀比(WHR)
df['WHR'] = df['Abdomen'] / df['Hip']
# 腰围身高比
df['WHtR'] = df['Abdomen'] / (df['Height'] * 2.54)
3.3 数据分割
将数据集分为训练集(80%)和测试集(20%),并进行特征标准化:
# 选择特征和目标变量
features = df.drop(['Density', 'BodyFat', 'AgeGroup', 'BMIGroup'], axis=1)
target = df['BodyFat']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42
)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
四、探索性数据分析
4.1 描述性统计
通过描述性统计,我们了解数据的基本特征:
- 样本数量:252名男性
- 年龄范围:20-80岁
- 体脂率范围:3%-45%
- BMI范围:18.5-35
4.2 相关性分析
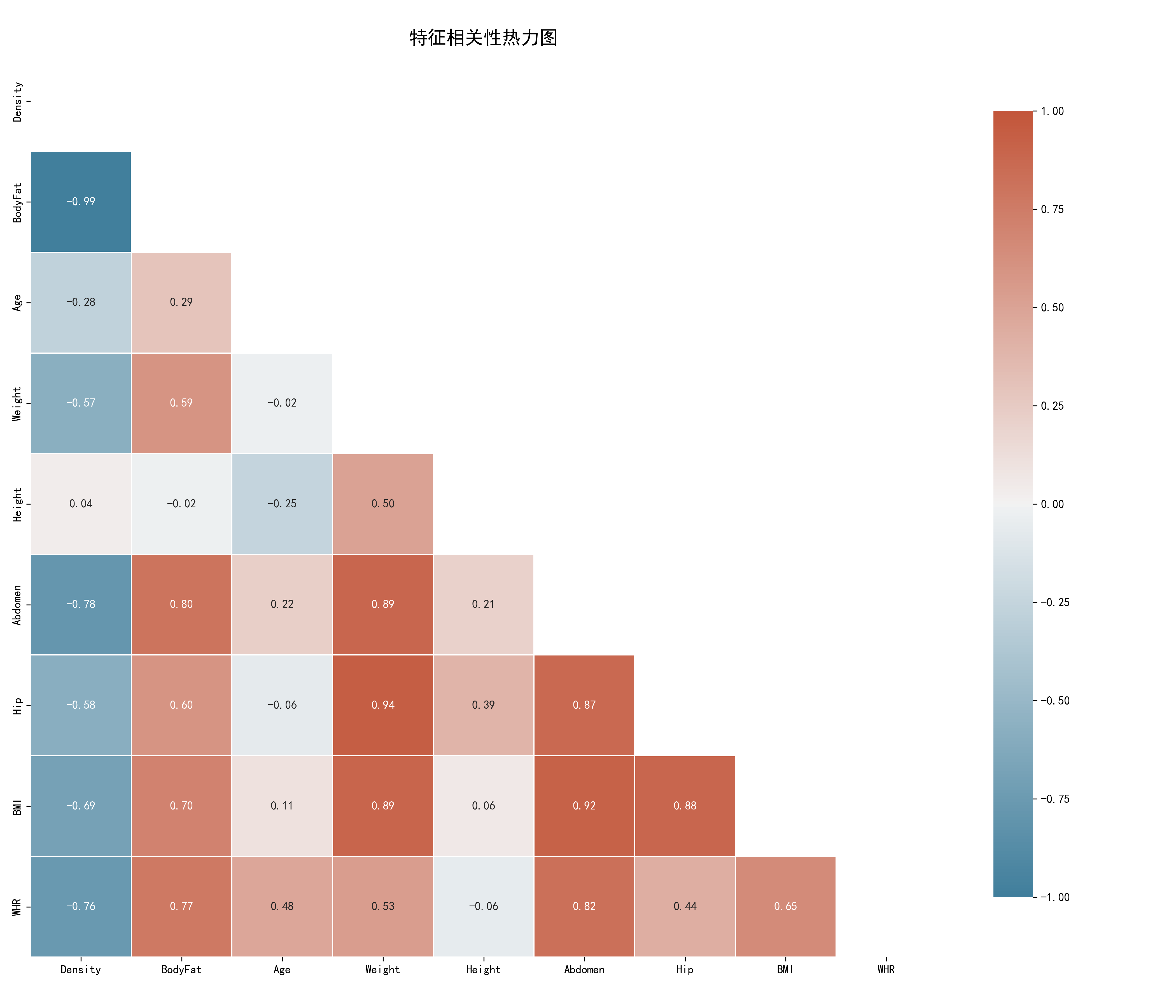
通过计算特征间的相关系数,我们发现:
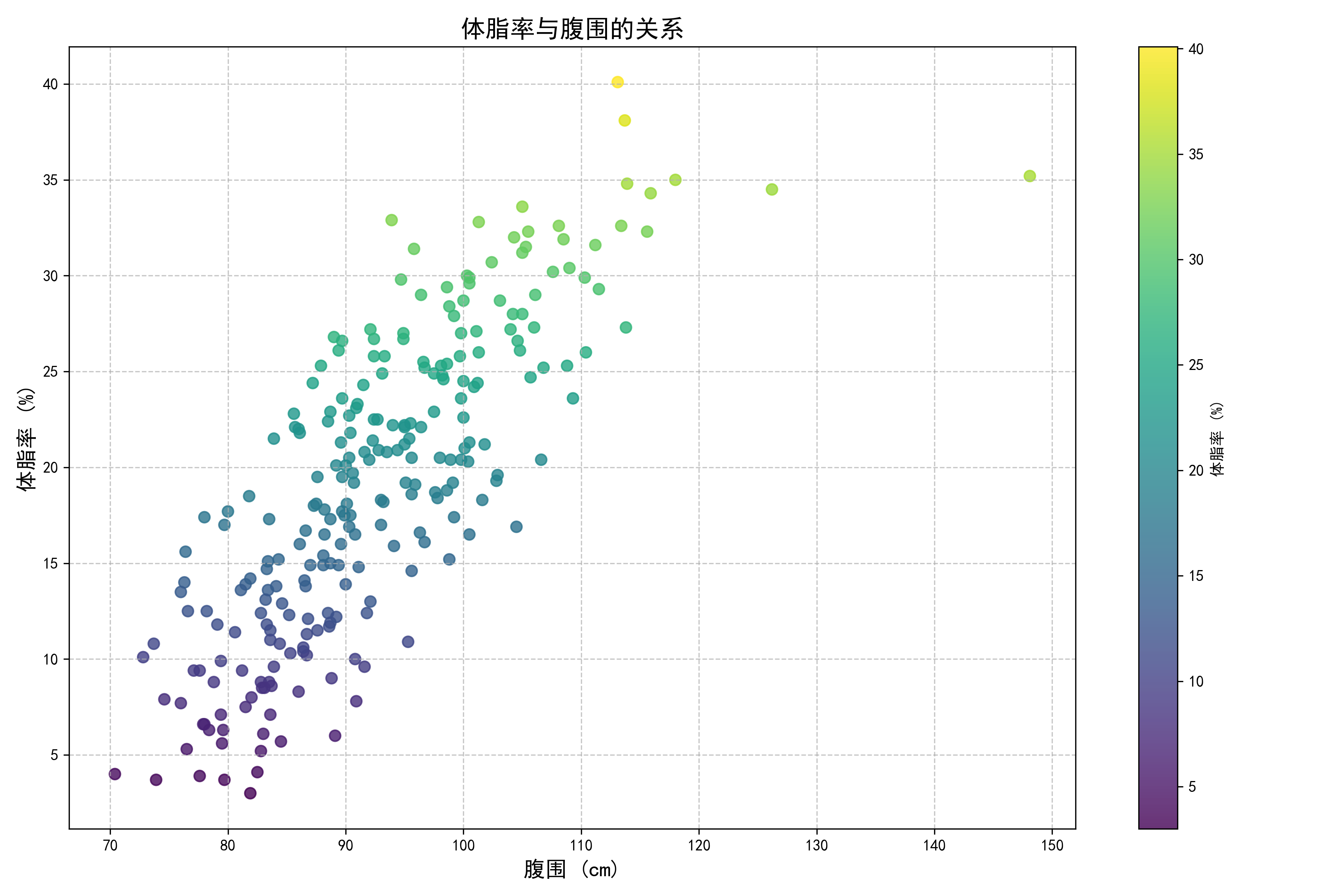
- 体脂率与腹围的相关性最高(r > 0.8)
- 体脂率与BMI、体重、胸围也有较强相关性
- 体脂率与身高的相关性较弱
4.3 年龄与体脂率关系
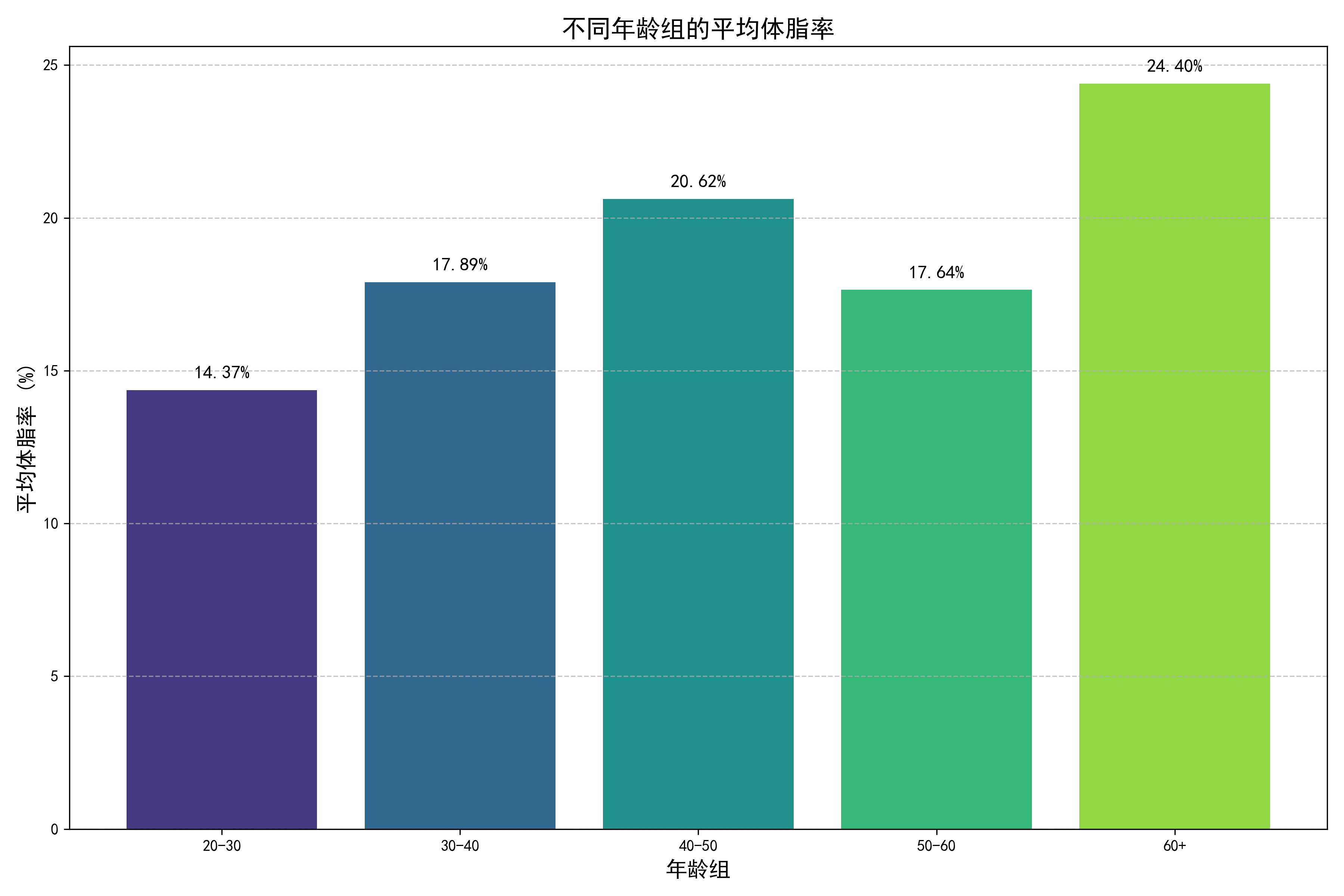
分析发现,体脂率随年龄增长而增加,特别是在50岁以上人群中,体脂率显著高于年轻群体。
4.4 BMI与体脂率关系
BMI与体脂率呈现强正相关关系,但同样BMI的人可能有不同的体脂率,这表明仅依靠BMI评估健康状况存在局限性。
五、模型构建与评估
5.1 模型选择
本项目尝试了以下回归模型:
- 线性回归(Linear Regression)
- 岭回归(Ridge Regression)
- Lasso回归(Lasso Regression)
- 随机森林回归(Random Forest Regression)
- 梯度提升回归(Gradient Boosting Regression)
5.2 模型训练
每个模型都在训练集上进行训练,并使用5折交叉验证评估模型性能:
# 定义模型
models = {
'LinearRegression': LinearRegression(),
'Ridge': Ridge(alpha=1.0),
'Lasso': Lasso(alpha=0.1),
'RandomForest': RandomForestRegressor(n_estimators=100, random_state=42),
'GradientBoosting': GradientBoostingRegressor(n_estimators=100, random_state=42)
}
# 训练并评估每个模型
for name, model in models.items():
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 计算评估指标
train_rmse = np.sqrt(mean_squared_error(y_train, y_train_pred))
test_rmse = np.sqrt(mean_squared_error(y_test, y_test_pred))
train_r2 = r2_score(y_train, y_train_pred)
test_r2 = r2_score(y_test, y_test_pred)
5.3 模型评估
通过比较不同模型在测试集上的性能,我们选择了最佳模型。评估指标包括:
- RMSE(均方根误差):预测值与实际值差异的平方根
- MAE(平均绝对误差):预测值与实际值差异的绝对值平均
- R²(决定系数):模型解释的方差比例
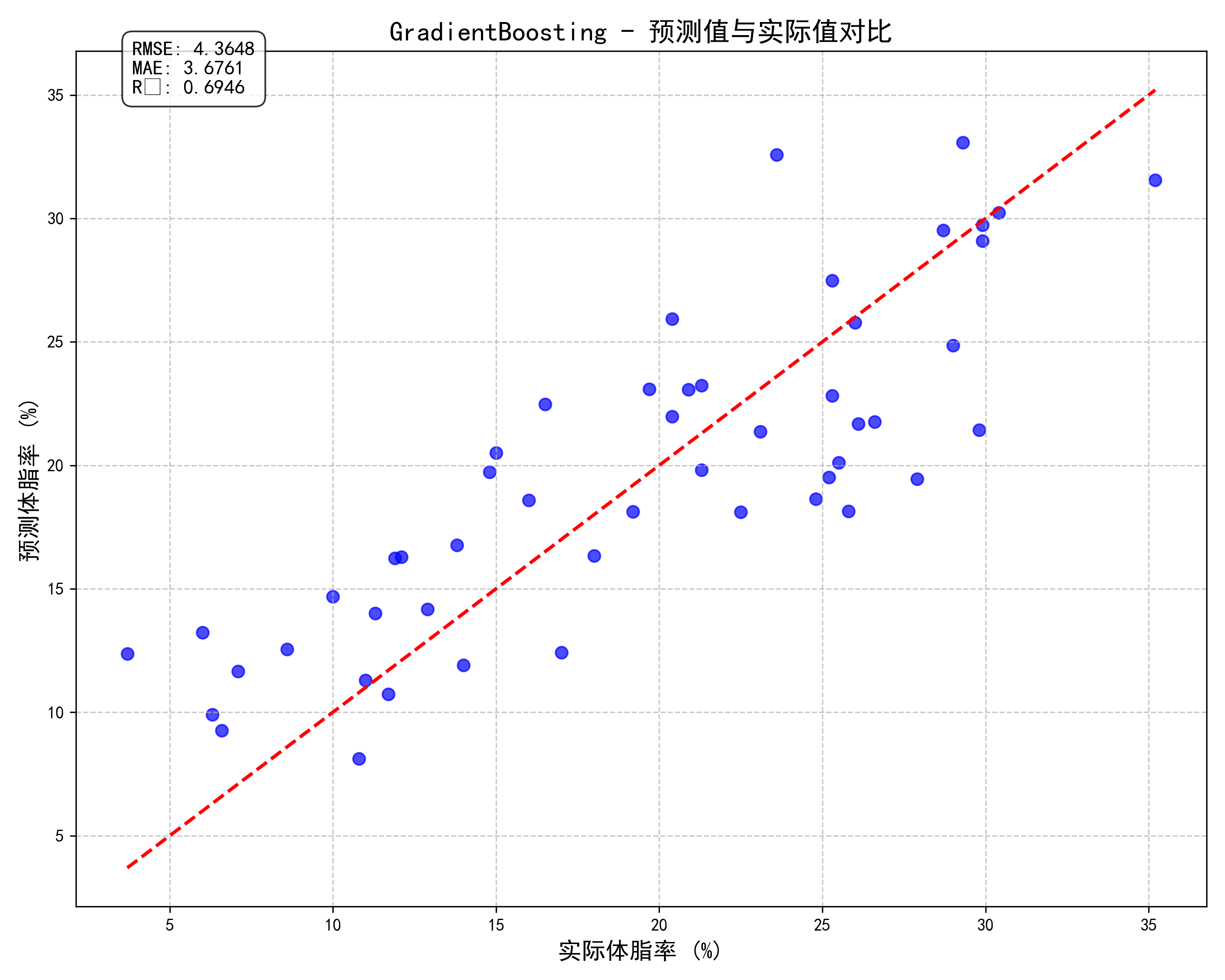
经过评估,梯度提升回归模型表现最佳,具有最高的R²值和最低的RMSE值。
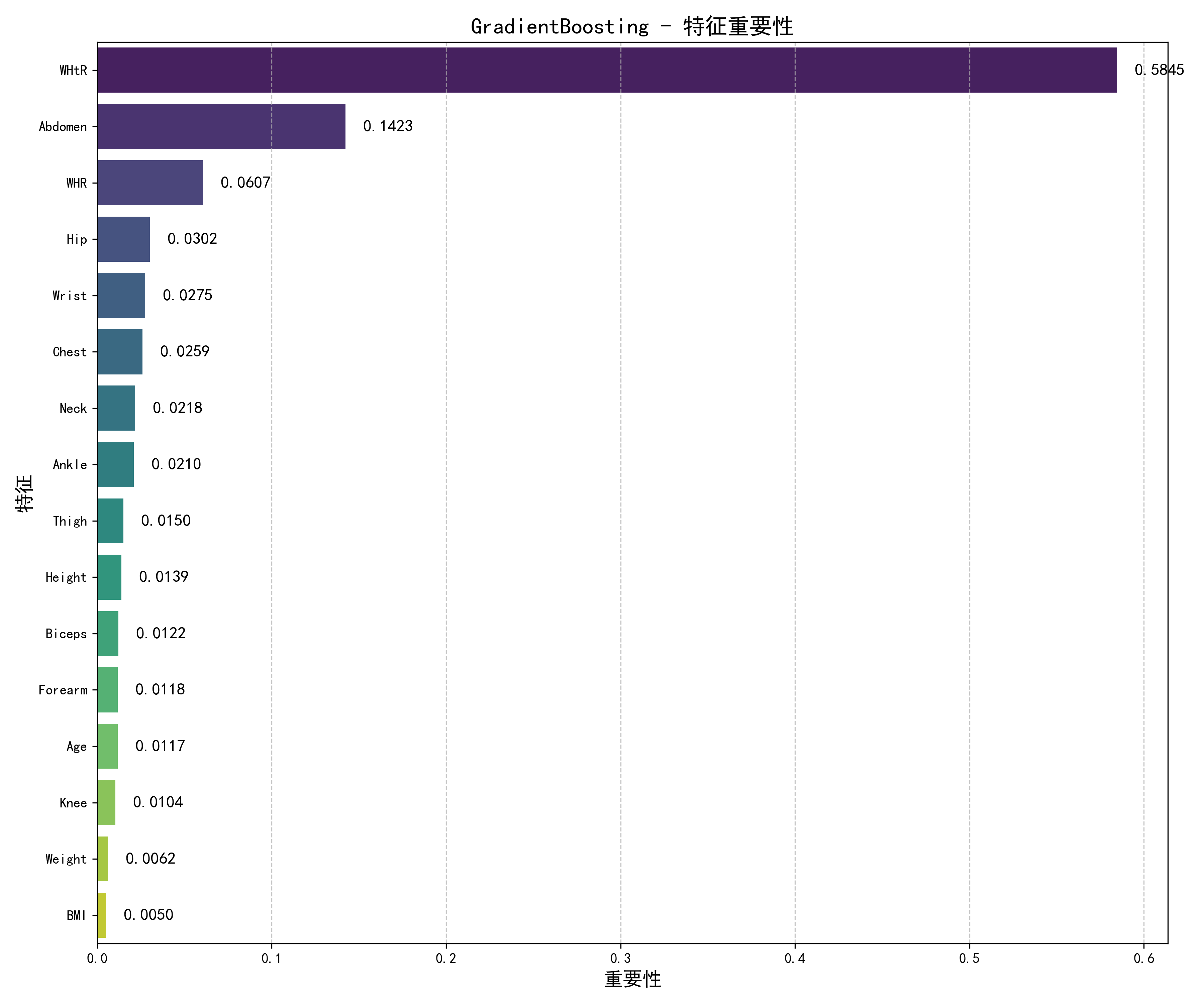
5.4 特征重要性分析
通过分析最佳模型的特征重要性,我们发现:
- 腹围(Abdomen)是预测体脂率的最重要特征
- BMI和腰臀比(WHR)也是重要预测因子
- 年龄对体脂率预测也有一定影响
六、可视化分析结果
6.1 体脂率与腹围关系
使用Echarts生成的散点图清晰展示了体脂率与腹围的强相关性,腹围越大,体脂率通常越高。
6.2 不同年龄组的体脂率分布
通过柱状图展示不同年龄组的平均体脂率,可以看到体脂率随年龄增长的趋势。
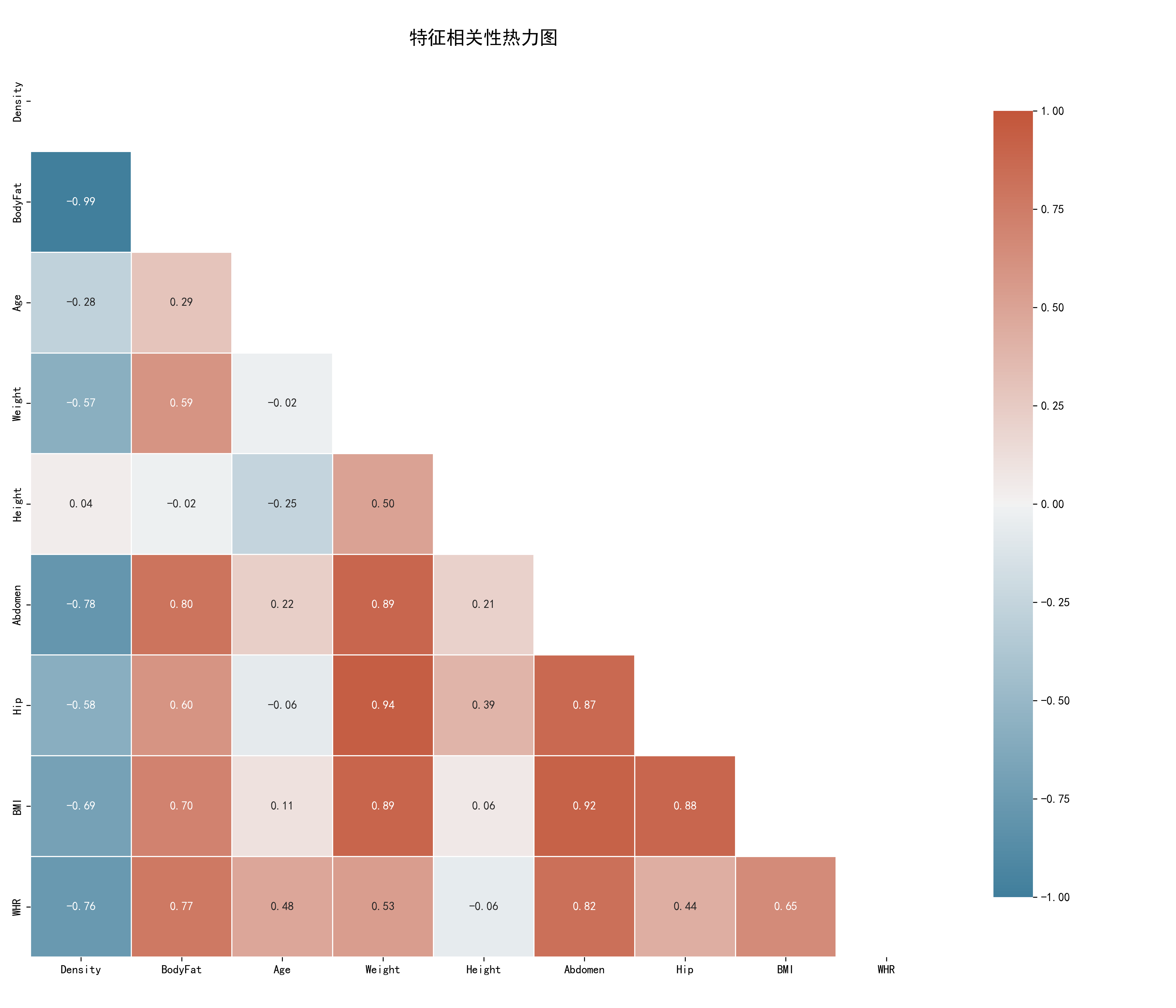
6.3 特征相关性热力图
使用Echarts生成的热力图直观展示了各特征间的相关性强度。
6.4 预测值与实际值对比
散点图展示了模型预测值与实际体脂率的对比,点越接近对角线,预测越准确。
七、结论与建议
7.1 主要发现
- 腹围是预测体脂率的最重要指标,这与医学研究中腹部脂肪与健康风险的关联一致
- 简单的人体测量数据可以有效预测体脂率,无需昂贵设备
- 梯度提升回归模型能够提供较高的预测准确度(R² > 0.85)
- 年龄是体脂率的重要影响因素,年龄增长通常伴随体脂率上升
7.2 应用价值
- 健康评估:提供便捷的体脂率评估方法,无需专业设备
- 健身指导:帮助制定针对性的减脂健身计划
- 健康监测:长期跟踪体脂率变化,评估健康干预效果
- 风险预警:识别高体脂人群,及早进行健康干预
7.3 未来研究方向
- 扩展数据集:纳入女性样本和更多年龄段的数据
- 深度学习:尝试深度学习方法提高预测精度
- 个性化模型:根据年龄、性别等因素构建个性化预测模型
- 移动应用:开发移动应用,使用户可以便捷地进行体脂率评估
八、技术实现详解
8.1 项目结构
BodyFatPrediction/
│
├── README.md # 项目说明文档
├── 体脂预测数据集.csv # 原始数据集
├── bodyfat_analysis.py # 分析脚本
├── analysis_document.md # 分析报告文档
│
└── output/ # 输出目录
├── best_model.pkl # 保存的最佳模型
├── scaler.pkl # 特征标准化器
├── correlation_heatmap.png # 相关性热力图
├── feature_importance.png # 特征重要性图
├── bodyfat_distribution.png # 体脂率分布图
├── bodyfat_vs_features.png # 体脂率与特征关系图
├── bodyfat_by_age.png # 年龄组体脂率箱线图
├── bodyfat_by_bmi.png # BMI组体脂率箱线图
├── prediction_vs_actual.png # 预测值与实际值对比图
├── prediction_errors.png # 预测误差分布图
├── bodyfat_abdomen_scatter.html # Echarts散点图
├── bodyfat_by_age_bar.html # Echarts柱状图
├── correlation_heatmap.html # Echarts热力图
└── prediction_vs_actual.html # Echarts预测对比图
8.2 核心代码实现
8.2.1 数据加载与清洗
def load_data(self):
"""加载数据并进行初步探索"""
self.df = pd.read_csv(self.data_path)
# 数据基本信息检查
def clean_data(self):
"""数据清洗和预处理"""
# 异常值检测与处理
# 创建新特征:BMI、WHR、WHtR
8.2.2 探索性分析与可视化
def exploratory_analysis(self):
"""探索性数据分析"""
# 目标变量分布
# 相关性分析
# 体脂率与各特征的散点图
# 年龄分组分析
# BMI分组分析
def visualize_with_echarts(self):
"""使用Echarts生成高分辨率可视化图表"""
# 体脂率与腹围的散点图
# 不同年龄组的平均体脂率柱状图
# 相关性热力图
8.2.3 模型训练与评估
def train_models(self):
"""训练多个回归模型并评估性能"""
# 定义模型:线性回归、岭回归、Lasso回归、随机森林、梯度提升
# 训练模型并计算评估指标
# 选择最佳模型
# 分析特征重要性
def evaluate_best_model(self):
"""评估最佳模型并生成详细的评估报告"""
# 预测值与实际值对比
# 计算评估指标:RMSE、MAE、R²
# 绘制预测误差分布图
8.2.4 模型保存
def save_model(self, model_path=None):
"""保存最佳模型"""
if model_path is None:
model_path = os.path.join(self.output_dir, 'best_model.pkl')
joblib.dump(self.best_model, model_path)
8.3 运行方法
在命令行中执行以下命令运行分析脚本:
python bodyfat_analysis.py
脚本将自动执行完整的分析流程,包括数据加载、清洗、探索性分析、模型训练、评估和可视化,并将结果保存到output目录。

















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









