







1.项目背景
随着健康意识的提升和健身文化的普及,人们对科学健身和个性化训练的需求日益增长,健身房会员的锻炼模式和健康管理需求呈现出新的特点,本项目使用基于真实健身模式生成的973位会员数据进行深入分析,探索不同会员群体的训练特征和健康风险,了解影响会员训练效果的关键因素,这不仅有助于理解会员的锻炼习惯,还可以为健身房优化服务体系、制定更科学的训练计划提供数据支持,同时,通过建立健康风险预测模型,可以更好地识别潜在的健康隐患,为提供安全、高效的个性化训练指导奠定基础。
2.数据说明
| 字段 | 说明 |
|---|---|
| Index | 每条记录的唯一标识号 |
| Age | 会员年龄 |
| Gender | 会员性别(男性或女性) |
| Weight (kg) | 会员体重(单位:公斤) |
| Height (m) | 会员身高(单位:米) |
| Max_BPM | 运动时最大心率 |
| Avg_BPM | 运动时平均心率 |
| Resting_BPM | 静息心率 |
| Session_Duration (hours) | 每次锻炼持续时间(单位:小时) |
| Calories_Burned | 每次锻炼消耗的卡路里 |
| Workout_Type | 锻炼类型(包括:瑜伽、HIIT、有氧、力量训练) |
| Fat_Percentage | 体脂率(百分比) |
| Water_Intake (liters) | 饮水量(单位:升) |
| Workout_Frequency (days/week) | 每周锻炼频率(单位:天/周) |
| Experience_Level | 训练经验水平(1 至 3级) |
| BMI | 身体质量指数 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from scipy.stats import spearmanr,f_oneway
from imblearn.over_sampling import RandomOverSampler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import classification_report,mean_squared_error, r2_score,mean_absolute_error
data = pd.read_csv("/home/mw/input/11011446/gym_members_data.csv")
4.数据预览

查看重复值:0

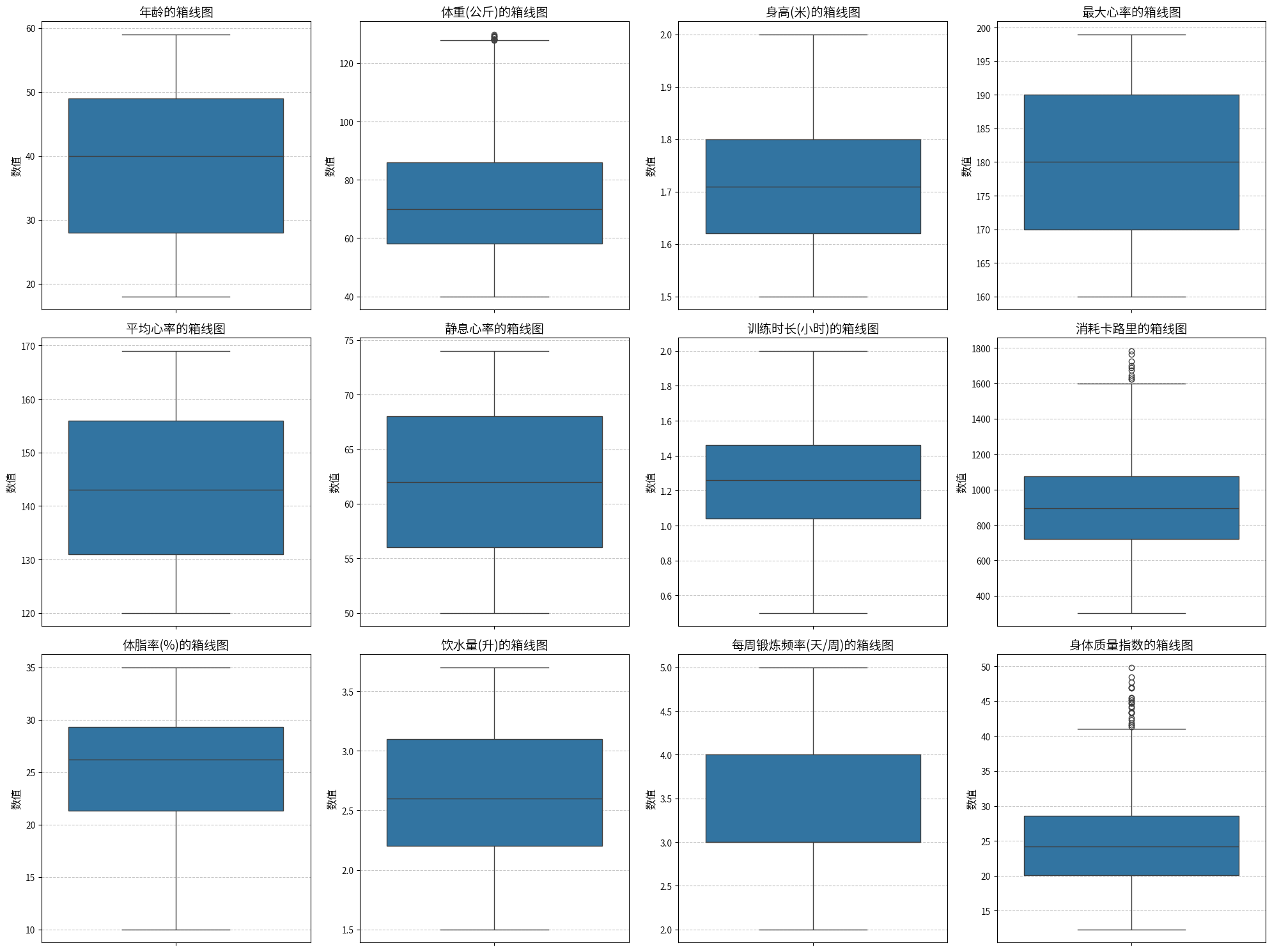
数据不存在缺失值、重复值,虽然体重、BMI、卡路里消耗存在少量异常值,但是也是符合一些大体重、运动时间较长的用户,故不处理这些值。
5.用户画像分析
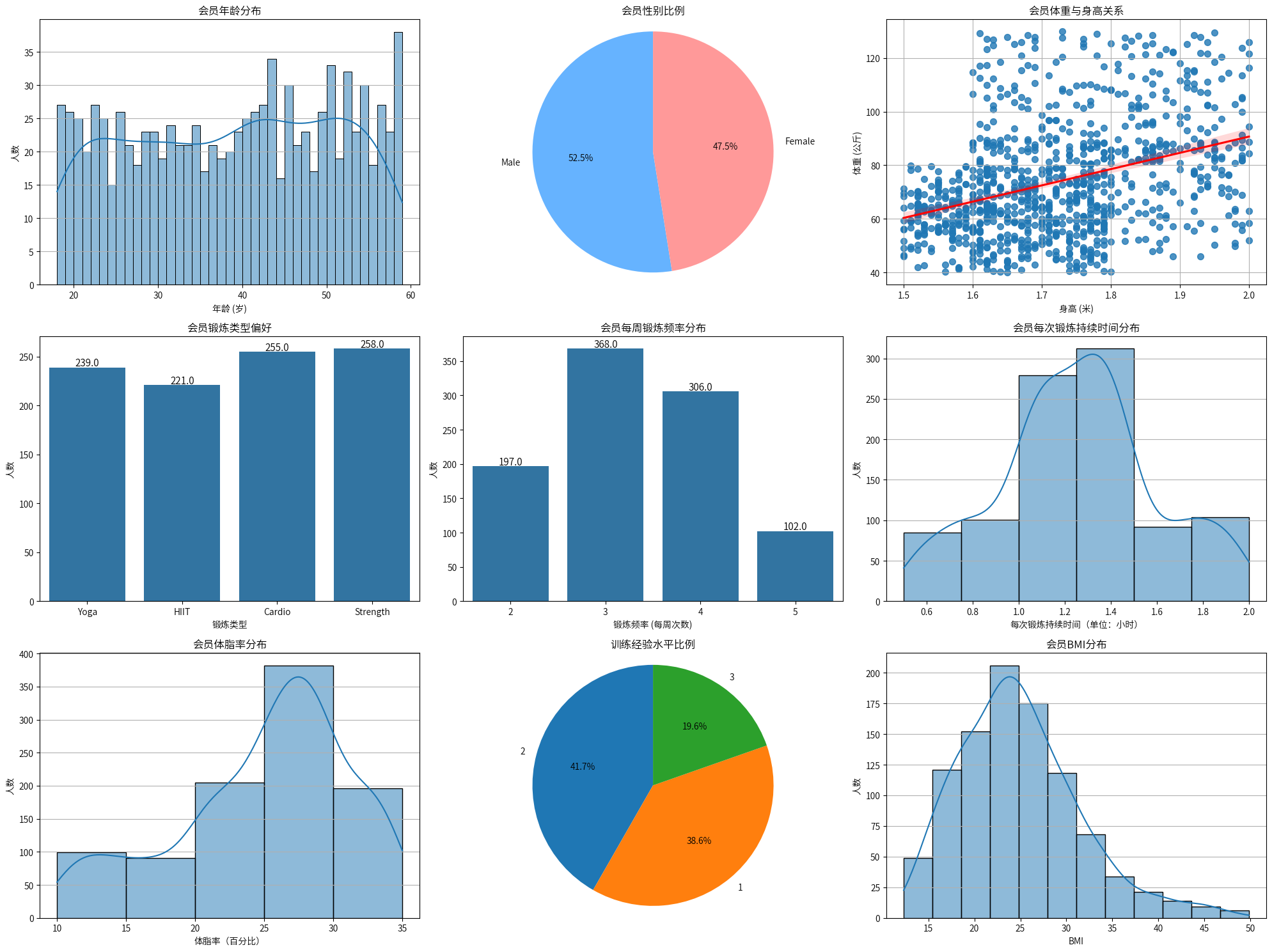
-
基础人口统计特征:
-
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









