







公开的数据集
利用网络爬虫抓取数据
- 网络爬虫(Web Crawler)
用于搜索引擎:获得网页网址及对应内容,用来匹配用户搜索结果。
用作数据获取工具:自动访问网页并记录网页对应的内容。
网络爬虫需要面临运行时间长、失败率高、不可控因素多 - 爬取网页的基本步骤
a) 找到目标URL 或者 API数据源(例如:百度地图API、新浪微博API、哔哩哔哩API)
b) 取回并分析网页源代码
c) 存储数据 - 保存网络爬虫数据的建议
a) 使用数据库(MySQL / MongoDB)来存储,比csv更稳定,且支持查询
b) 记录原始页面的地址以及访问时间,以便校验及增量爬取
c) 保留原始html文本,以便日后增添字段
d) 使用UTF-8编码
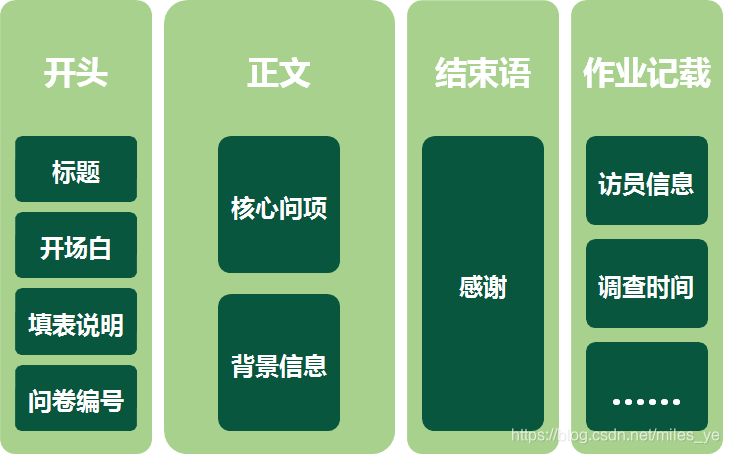
设计调查问卷收集数据
- 问卷设计流程
搭建框架 >> 确定问题形式 >> 选措辞、排结构 >> 评估、预测试















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











