






很久没有写过 Python 爬虫了,最近不是在拧螺丝,就是在拧螺丝的路上,手生的很了,很多代码用法也早已经殊生,因此也花了一点时间来梳理,写的比较渣,见谅!
话说,这种类型的网站其实没有什么搞头,有手就行,毕竟没有爬取限制,唯一限制就是外网,访问速度存在问题,比如视频爬取下载存在链接问题。
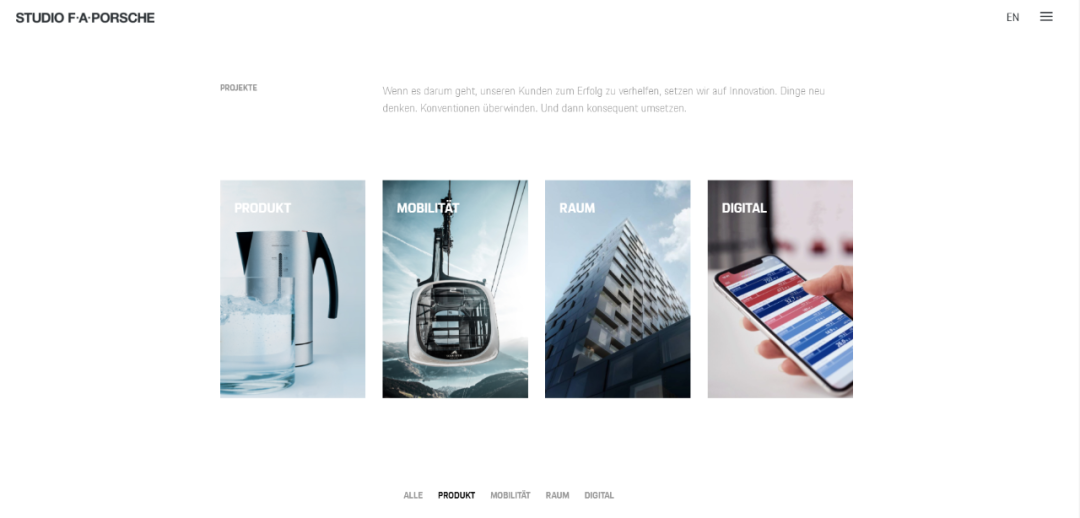
几个要点
抓取源接口
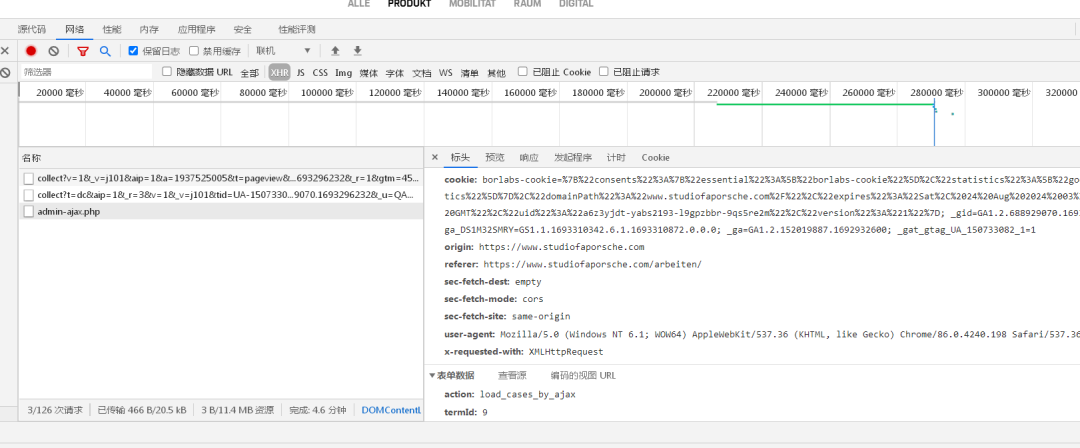
post方式获取数据!
def get_list():
url="https://www.studiofaporsche.com/wp-admin/admin-ajax.php"
headers={
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
data={
"action": "load_cases_by_ajax",
"termId": 18
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
hrefs=tree.xpath('//div[@class="row"]/div/a/@href')
print(hrefs)
i=1
for href in hrefs:
get_detail(href, i)
i=i+1
time.sleep(2)timeout 设置
由于是外网,存在访问速度过慢,易卡死的状态,所以需要设置 timeout 时间稍长,不然爬取会卡死,如需对数据完整抓取,须提前设置好备份状态,访问超时、报错的处理。
timeout=8附网站爬取完整源码:
#studiofaporsche.com 作品采集
# -*- coding: UTF-8 -*-
#@author:huguo00289
import requests
import time
from lxml import etree
import os
def get_list():
url="https://www.studiofaporsche.com/wp-admin/admin-ajax.php"
headers={
"cookie": "borlabs-cookie=%7B%22consents%22%3A%7B%22essential%22%3A%5B%22borlabs-cookie%22%5D%2C%22statistics%22%3A%5B%22google-analytics%22%5D%7D%2C%22domainPath%22%3A%22www.studiofaporsche.com%2F%22%2C%22expires%22%3A%22Sat%2C%2024%20Aug%202024%2003%3A03%3A19%20GMT%22%2C%22uid%22%3A%22a6z3yjdt-yabs2193-l9gpzbbr-9qs5re2m%22%2C%22version%22%3A%221%22%7D; _gid=GA1.2.1858239460.1692932600; _gat_gtag_UA_150733082_1=1; _ga_DS1M32SMRY=GS1.1.1692932599.1.1.1692933185.0.0.0; _ga=GA1.2.152019887.1692932600",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
data={
"action": "load_cases_by_ajax",
"termId": 18
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
hrefs=tree.xpath('//div[@class="row"]/div/a/@href')
print(hrefs)
i=1
for href in hrefs:
get_detail(href, i)
i=i+1
time.sleep(2)
def get_detail(url,i):
headers = {
#"cookie": "borlabs-cookie=%7B%22consents%22%3A%7B%22essential%22%3A%5B%22borlabs-cookie%22%5D%2C%22statistics%22%3A%5B%22google-analytics%22%5D%7D%2C%22domainPath%22%3A%22www.studiofaporsche.com%2F%22%2C%22expires%22%3A%22Sat%2C%2024%20Aug%202024%2003%3A03%3A19%20GMT%22%2C%22uid%22%3A%22a6z3yjdt-yabs2193-l9gpzbbr-9qs5re2m%22%2C%22version%22%3A%221%22%7D; _gid=GA1.2.1858239460.1692932600; _gat_gtag_UA_150733082_1=1; _ga_DS1M32SMRY=GS1.1.1692932599.1.1.1692933185.0.0.0; _ga=GA1.2.152019887.1692932600",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
response = requests.get(url=url,headers=headers,timeout=8)
html = response.content.decode('utf-8')
tree = etree.HTML(html)
title=tree.xpath('//title/text()')[0]
title=title.split('-')[0]
title=title.strip()
print(title)
try:
path=f'{i}_{title}/'
os.makedirs(path,exist_ok=True)
except:
print("创建标题文件夹出错!")
path = f'{i}_/'
os.makedirs(path, exist_ok=True)
backimg=tree.xpath('//div[@class="singlePost singleCase"]/section/@data-src')[0]
print(backimg)
down_img(backimg, path)
p=tree.xpath('//div[@class="row textRow"]/div/p/text()')
p='\n'.join(p)
p=f'{title}\n{p}'
print(p)
with open(f'{path}{i}.txt','w',encoding='utf-8') as f:
f.write(p)
imgs=tree.xpath('//div[@class="imageWrap imageDimension"]/img/@data-src')
print(imgs)
j=1
for img in imgs:
down_imgs(img, path,j)
j=j+1
time.sleep(2)
video=tree.xpath('//div[@class="col-12 videoCol"]/video/source/@src')[0]
print(video)
down_video(video, path)
def down_img(img,path):
headers = {
"referer": "https://www.studiofaporsche.com/case/klafs-sauna-sauna-s11/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
imgurl = img
imgname = img.split('/')[-1]
imgname = imgname.split('-')[-1]
r = requests.get(url=imgurl, headers=headers, timeout=10)
time.sleep(2)
with open(f'{path}{imgname}', 'wb') as f:
f.write(r.content)
print(f'下载图片 {imgname} 成功!')
def down_imgs(img,path,j):
headers = {
"referer": "https://www.studiofaporsche.com/case/klafs-sauna-sauna-s11/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
imgurl = img
imgname = img.split('/')[-1]
imgname = imgname.split('-')[-1]
r = requests.get(url=imgurl, headers=headers, timeout=10)
time.sleep(2)
with open(f'{path}{j}_{imgname}', 'wb') as f:
f.write(r.content)
print(f'下载图片 {imgname} 成功!')
def down_video(video,path):
headers = {
"referer": "https://www.studiofaporsche.com/case/klafs-sauna-sauna-s11/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
videourl = video
videoname = video.split('/')[-1]
r = requests.get(url=videourl, headers=headers, timeout=10)
time.sleep(2)
with open(f'{path}{videoname}', 'wb') as f:
f.write(r.content)
print(f'下载视频 {videoname} 成功!')
def main():
get_list()
if __name__=="__main__":
main()·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









