







统计学习知识点整理——极大似然估计(MLE)与最大后验概率(MAP)
似然函数与概率函数
似然(likelihood)这个词其实和概率(probability)是差不多的意思,对于下面的式子:
P ( x ∣ θ )
输入有两个:x表示某一个具体的数据;θ 表示模型的参数。
如果θ 是已知确定的,x 是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
如果x 是已知确定的,θ 是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
极大似然估计
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。
特点:简单适用;在训练样本增多时通常收敛得很好;基于所有的采样都是独立同分布的假设;
对于样本的概率:
目标就是要求一个θ,使得上面的概率最大,为了计算简化,对式子取对数:
要最大化L,对L求导数并令导数为0即可求解。
最大后验概率
最大后验估计(MAP-Maxaposterior):求p(D|θ )*p(θ)取最大值的那个参数向量θ,最大似然估计可以理解为当先验概率p(θ)为均匀分布时的MAP估计器。(MAP缺点:如果对参数空间进行某些任意非线性变换,如旋转变换,那么概率密度p(θ)就会发生变化,其估计结果就不再有效了。)根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中,可看做是规则化的最大似然估计
由贝叶斯公式:
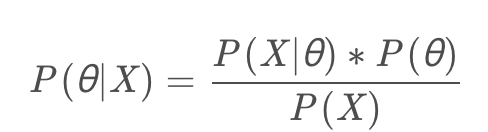
P(X)是已经发生的事情,为固定值,所以最大化后验概率P(θ|X)就是最大化P(X|θ)P(θ)
至于上面目标函数的求解,也和极大似然估计是一样的,对目标函数求导并令导数为0来求解。
MAP与MLP的区别
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说,MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。MAP允许我们把先验知识加入到估计模型中,这在样本很少的时候是很有用的,因为样本很少的时候我们的观测结果很可能出现偏差,此时先验知识会把估计的结果“拉”向先验,实际的预估结果将会在先验结果的两侧形成一个顶峰。通过调节先验分布的参数,比如beta分布的,我们还可以调节把估计的结果“拉”向先验的幅度,越大,这个顶峰越尖锐。这样的参数,我们叫做预估模型的“超参数”。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









