







 本文介绍了极大似然估计(MLE)的概念,并通过贝叶斯分类决策理论进行阐述。MLE是一种参数估计方法,用于估计概率密度函数的参数值。在语音识别等场景中,MLE有助于根据有限样本估计后验概率。文中详细讲解了如何求解最大似然估计量,包括单参数和多参数的情况,并给出了正态分布和均匀分布的示例。最后,总结了MLE的特点,强调了其在假设模型正确时的有效性。
本文介绍了极大似然估计(MLE)的概念,并通过贝叶斯分类决策理论进行阐述。MLE是一种参数估计方法,用于估计概率密度函数的参数值。在语音识别等场景中,MLE有助于根据有限样本估计后验概率。文中详细讲解了如何求解最大似然估计量,包括单参数和多参数的情况,并给出了正态分布和均匀分布的示例。最后,总结了MLE的特点,强调了其在假设模型正确时的有效性。
在研究语音识别中的算法之前,需要做一些基础理论的介绍,以便更好地进行后面的算法学习!~~~本文主要研究极大似然估计的理论。
下面由经典的贝叶斯分类决策来引入极大似然估计:
贝叶斯公式:
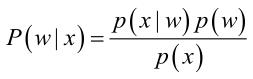
其中:p(w):为先验概率,表示每种类别分布的概率;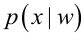
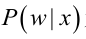
已知,狗蛋儿在下雨天去幼儿园的概率是1/2,在晴天去幼儿园的概率是2/3,下雨天与晴天的比例是2:1,那么问题来了,狗蛋儿今天去幼儿园了,问今天是下雨还是晴天?
从问题可以看出, 事件发生了,我们要求出后验概率,根据贝叶斯公式求解步骤如下:
设: W1:下雨;W2 :晴天; X:去幼儿园;
由已知条件可知:
狗蛋下雨天或者晴天去幼儿园是相互独立的,由此可以算出
继而由贝叶斯公式可以求得后验概率,也就是狗蛋去去幼儿园的条件下,当天天气是下雨天和晴天的概率:
那么问题又来了:如果我们不知道先验概率和类条件概率
,我们只有狗蛋儿以前去幼儿园的一些样本,如何根据仅有的样本来识别以后狗蛋去幼儿园的天气情况(后验概率)呢,最直接的方法就是找到(估计)
 和
和 ,根据估计值,再套用贝叶斯公式进行计算。
,根据估计值,再套用贝叶斯公式进行计算。
先验概率的估计比较容易:1,根据已知知识和经验;2,根据样本进行统计(样本要足够的全)
类条件概率就比较难了:概率密度函数包含了一个随机变量的全部信息;样本数据可能不多;特征向量x的维度可能很大等等。总之要直接估计类条件概率的密度函数很难。解决的办法就是,把估计完全未知的概率密度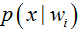
最终,最大似然估计的目的就是根据样本,来估计出概率密度函数的参数值。
Maximum Likehood Estimation
原理:最大似然估计是建立在最大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“ 模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为最大似然估计。在估计开始前时,我们对样本有一个重要的要求:训练样本的分布能代表样本的真实分布。每个样本集中的样本都是所谓独立同分布的随机变量 (iid条件),且有充分的训练样本。
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4411
4411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











