







深度典型相关分析总结
典型相关分析(Canonical Correlation Analysis,CCA)
基础知识https://www.cnblogs.com/pinard/p/6288716.html
对于上面这篇文章对于降维是降到1维,即假设X,Y都有n个样本
X
=
[
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
]
x
i
∈
R
n
1
,
y
=
[
y
1
,
y
2
,
y
3
,
.
.
.
.
y
n
]
y
i
∈
R
n
2
X = [x_1, x_2, x_3, ..., x_n] x_i \in R^{n_1}, y = [y_1, y_2, y_3, .... y_n] y_i\in R^{n_2}
X=[x1,x2,x3,...,xn]xi∈Rn1,y=[y1,y2,y3,....yn]yi∈Rn2 通过投影向量a,b投影到1维即
X
′
=
[
x
1
′
,
x
2
′
,
x
3
′
,
.
.
.
.
x
n
′
]
,
x
i
′
∈
R
1
,
Y
′
=
[
y
1
′
,
y
2
′
,
y
3
′
,
.
.
.
.
y
n
′
]
,
y
i
′
∈
R
1
X' = [x'_1, x'_2, x'_3, ....x'_n], x'_i\in R^1, Y' = [y'_1, y'_2, y'_3, ....y'_n], y'_i\in R^1
X′=[x1′,x2′,x3′,....xn′],xi′∈R1,Y′=[y1′,y2′,y3′,....yn′],yi′∈R1此时可以通过奇异值分解或者特征值分解去求最大的相关性系数,此时如果投影到o维,
A
=
[
a
1
,
a
2
,
.
.
.
.
a
o
]
T
,
a
i
∈
R
n
A = [a_1, a_2,....a_o]^T, a_i \in R^n
A=[a1,a2,....ao]T,ai∈Rn,B也同理。此时该目标函数就可以写为
m
a
x
i
m
i
z
e
:
t
r
(
A
T
S
x
y
B
)
s
u
b
j
e
c
t
t
o
:
A
T
S
x
x
A
=
B
T
S
y
y
B
=
I
maximize: tr(A^T S_{xy}B)\\subjectto: A^TS_{xx}A=B^TS_{yy}B=I
maximize:tr(ATSxyB)subjectto:ATSxxA=BTSyyB=I
这里沿用了上面文章的符号即S代表协方差,同时计算相关性系数的时候就选取top-o个奇异值的和
深度典型相关分析(Deep Canonical Correlation Analysis, DCCA)
深度典型相关分析呢是采用神经网络来代替投影过程,(这里采用的图片和说法都来自论文Deep Canonical Correlation Analysis)
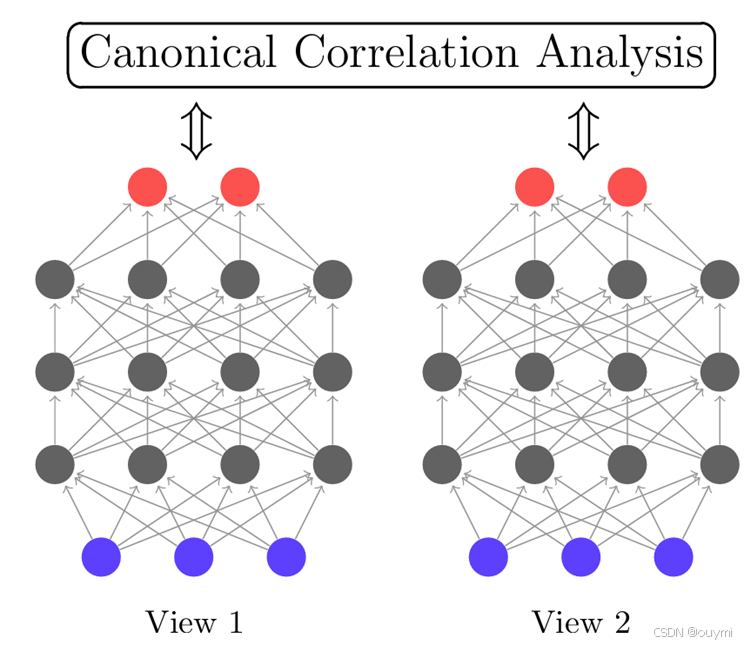
当输入的数据
X
∈
R
n
∗
d
1
X \in R^{n*d1}
X∈Rn∗d1输出为o维即
X
′
∈
R
n
∗
o
X' \in R^{n*o}
X′∈Rn∗o,Y也同理。此时在去计算CCA得到的值就是top-o个奇异值的和这里的目标函数使用的是
(
θ
1
,
θ
2
)
=
a
r
g
m
a
x
(
θ
1
,
θ
2
)
c
o
r
r
(
f
1
(
X
;
θ
1
)
,
f
2
(
Y
;
θ
2
)
)
( \theta_1, \theta_2)=argmax_{ ( \theta_1, \theta_2)} corr(f_1(X;\theta_1), f_2(Y; \theta_2))
(θ1,θ2)=argmax(θ1,θ2)corr(f1(X;θ1),f2(Y;θ2))
θ
\theta
θ是指网络模型的参数,论文采取奇异值解法令
T
=
S
x
x
−
1
/
2
S
x
y
S
y
y
−
1
/
2
T = S^{-1/2}_{xx}S_{xy}S^{-1/2}_{yy}
T=Sxx−1/2SxySyy−1/2
c
o
r
r
(
X
′
,
Y
′
)
=
∣
∣
T
∣
∣
t
r
=
t
r
(
T
′
T
)
−
1
/
2
corr(X', Y') = ||T||_{tr} = tr(T'T)^{-1/2}
corr(X′,Y′)=∣∣T∣∣tr=tr(T′T)−1/2
为什么求T的奇异值要这么算因为,A’A 的迹等于A 的奇异值的平方和。详见https://zhuanlan.zhihu.com/p/29846048

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









