






目录
6. PhotoMaker 速度慢,150秒,和训Lora比没有显著优势
6. 无需Lora炼丹也能保持同一人物?ControlNet新功能Refrece Only测评
AIGC真实人像写真,也即输入一些图片,生成图片里对应人物在不同场景和风格下的图片。妙鸭相机作为AIGC领域一款成功的收费产品为大家展示了如何使用AIGC技术只需要少量的人脸图片建模,即可快速提供真/像/美的个人写真,在极短的时间拥有了大量的付费客户. 目前面临很多的挑战: 超长的训练微调时间、大的存储需求、需要输入多张图(落地时期望只输入一张)、在保持ID和风格可编辑间进退维谷、此消彼长.快手、字节“妙鸭化”,AI图像应用还能再度出圈吗?
其实C端用户只关心产品能否提供令人惊叹的效果,SOTA(最新技术)没有任何意义。用户编辑完成的图片可以分享到内容社区,和他人进行互动交流,着手建立内容社区,成为了大厂们保证产品留存的尝试。而不断开发新模版,也成了提高产品使用率的可行办法。比如,契合特殊节日、热点,推出“红钻贵族”“黏土”等使用模版,无一不是“拉新促活”(吸引新用户、促进现有用户活跃度)的实践。无论是搭建内容社区,还是上线新模版,关键都是让用户有命题、有方向,来了解可以用AI来做什么。只不过,就像不少开发者提到,AI生图目前处于中间阶段,普通用户大多还停留在自己浏览,甚至不会对外发的阶段,实际渗透率较低。如何使AI生图成为用户的持续需求,依然是值得不断探讨的命题。
妙鸭相机是图像生成式AI在国内的首款现象级应用,由阿里和优酷内部孵化而来。团队对妙鸭相机的定位是「每个人的AI摄影师」,希望可以帮助用户「便宜、快捷、安全地追求美」。而社交媒体上的晒图热情也体现了大众对妙鸭生成效果的肯定。「表情自然」「像自己又比自己美一点」是常见的对其的评价.
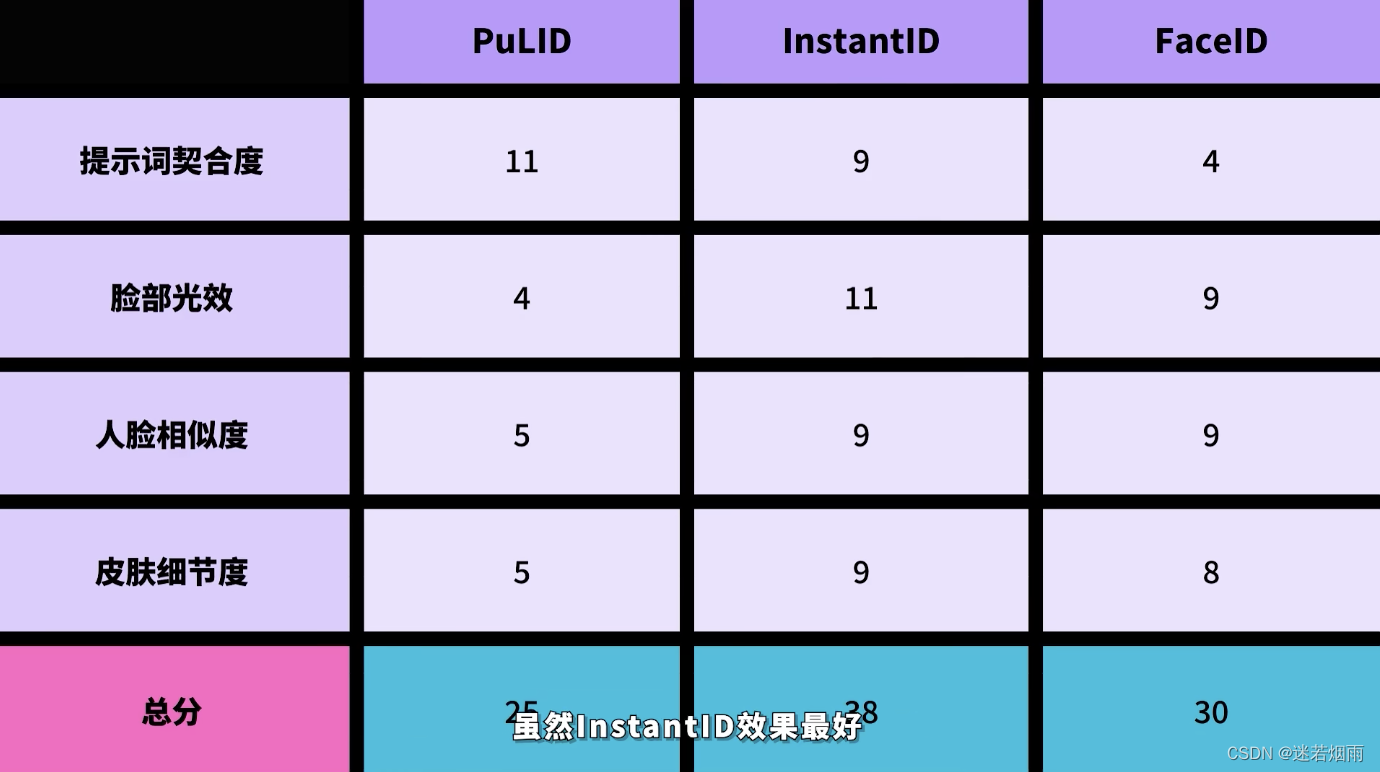
目前大致可分为训Lora绑定ID和免训练通过解耦交叉注意力注入两大路线,训Lora的优点是相似度高,可控性好,但普遍耗时较长,在数分钟到半小时不等;免训练的有点是速度快,仅需要5-10秒即可拿到结果,但相似度较训Lora要差些。

免训练
免训练最大优势就是速度快,用户体验好,但是和输入图片相似的程度有待提升,涌现了一系列方法
1. Face Adapter
代码 细粒度人脸ID和属性控制!浙大联合腾讯提出Face Adapter!
即插即用!“一模型双任务” | Face-Adapter:超越基于GAN和Diffusion的最新方法
2. IP-Adapter
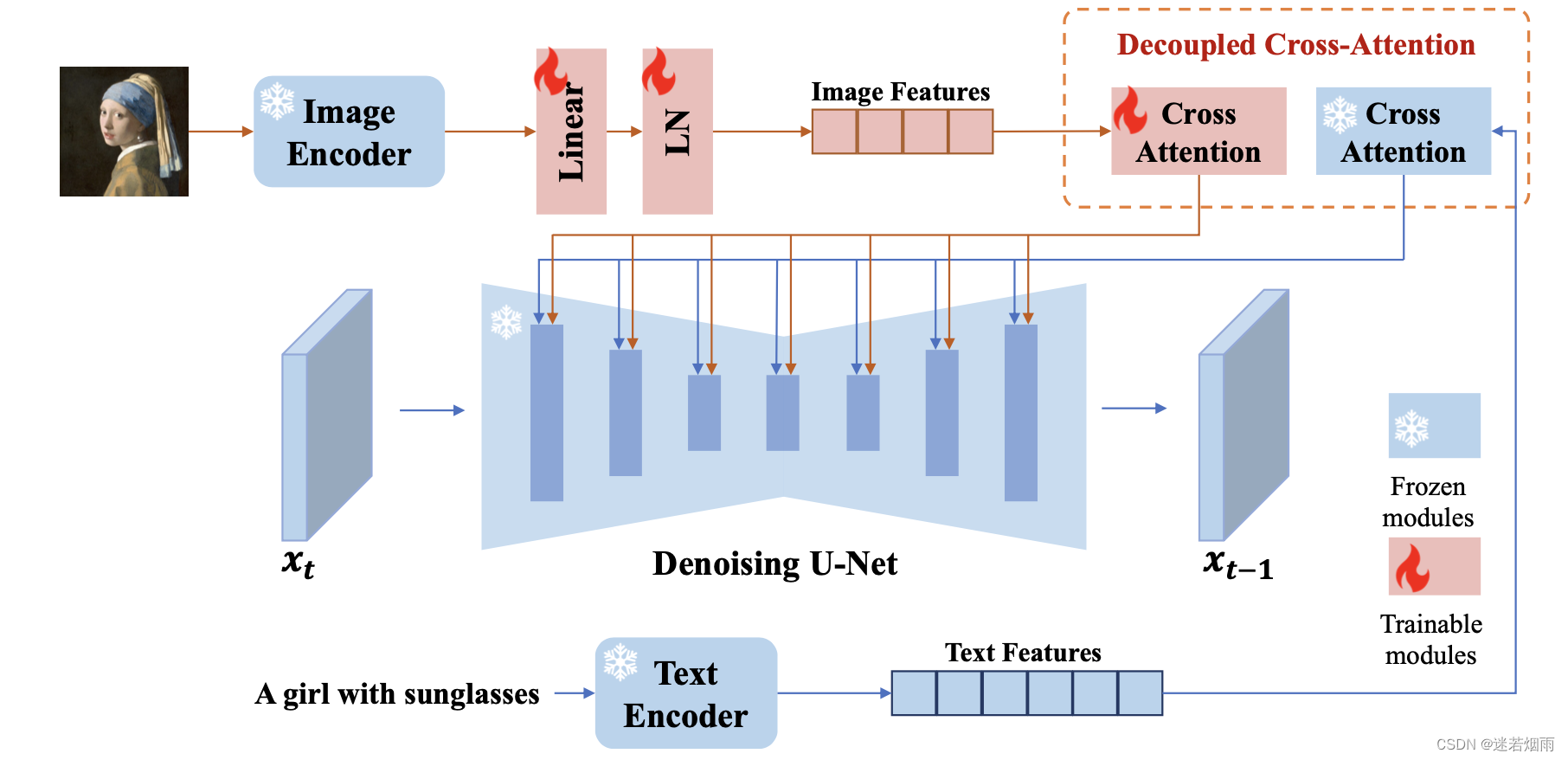
IP-Adapter到底是个什么呢,我理解的话它就是一个将图像token转变为和文字prompt一样,以此去调整原来文生图,达到他最后想要的结果。比如,有一段文字叫“带墨镜”,如果用文生图最后会随机给你一个带墨镜的男人或者女人或者其他,这个和当初训练文生图的数据集分布有关。那么我现在就想是个男人带墨镜,那么我用一个男人的照片送到这段文字前面,变成图像token+文字合起来的prompt,最后不就可以变成男人图像了吗。但是问题就在于你这个男人的照片过去的文生图模型不认识啊,所以你的微调应该是希望这个图像token变为“男人”这个文字的编码。
那么如何训练呢?这里可没有一张真正带墨镜的男人图片。实际上这里并不是一个有监督,如果我们对这个男人的图片加噪, 就是加噪后的图像,然后通过unet预测噪声,在预测的同时注入这个男人的图像token信息以及带墨镜的信息(图中cross attention)。因为除了对图像token进行学习以外,其余网络均固定。所以带墨镜这个信息是一直有的,出来的结果也是XX带墨镜的图像,只是谁带就不知道了。注入图像信息就是让文生图模型自我调节出一张图像,这个图像就是XX,同时也是输入的这个男人。在最初的噪声推理时,原本是不带男人的信息的,因为男人的照片加噪了很多步,信息已经没了。但是这个图像token(要和文字合并的)带了这个男人的信息,所以可以诱导扩散模型一步步生成一个像他的照片。这样最终就可以生成一张男人带墨镜的照片了,笔者最开始学的时候,这里还挺疑惑的,因为损失是和男人原图对比,而原图没有墨镜。实际上笔者想法是没有错的,要想男人带墨镜还需调节一个融合的参数,也就是图像和文字的合并。
AI重磅更新!一张图就能实现画风迁移!腾讯团队出品IP-Adapter支持ControlNet
京东|【羚珑AI智绘营】IP-Adapter,新一代“垫图”神器 · 语雀
IP-Adapter的核心优势,只画你关心的事
IP-Adapter和img2img虽然在操作上都是“垫图”,但它们的底层实现可以说是毫无关系
img2img相当于直接盖在参考图上开始临摹,虽然知道要画个男人,但会在老虎的基础上去修改,始终会很别扭,中间不免出现老虎和男人混淆的情况,画出一些强行混合不知所谓的图来。因为在这个流程中,参考图更为重要,一切是在它基础上画出来的,结果也更倾向于参考图。IP-Adapter则不是临摹,而是真正的自己去画,它始终记得prompt知道自己要画个男人,中间更像请来了徐悲鸿这样的艺术大师,将怎么把老虎和人的特点融为一体,讲解得偏僻入里,所以过程中一直在给“男人”加上“老虎”的元素,比如金黄的瞳仁、王字型的抬头纹、虎纹的须发等等。此时,prompt更为重要,因为这才是它的始终目标。
当然这些都是在一定的参数范围内,超过了阈值,那必然是要走极端的,照着参考图去copy了。但即便这样也可以看到img2img只是1:1的复制,而IP-Adapter有更多prompt的影子。当我们拥有这些特征,几乎就得到一个“即时lora”,而需要付出的成本只是去找几张符合预期的参考图
聊点硬核的: IPAdapter算法理论及在Stable Diffusion中的使用方法(一)
IP-Adapter:用于文本到图像扩散模型的文本兼容图像提示适配器

可以适配Stable Diffusion的任何基底模型
还可以和ControlNet或者T2I-Adapter结合在一起实现结构控制
可以用于图生图以及图像inpainting
还可以同时使用图像提示词和文本提示词
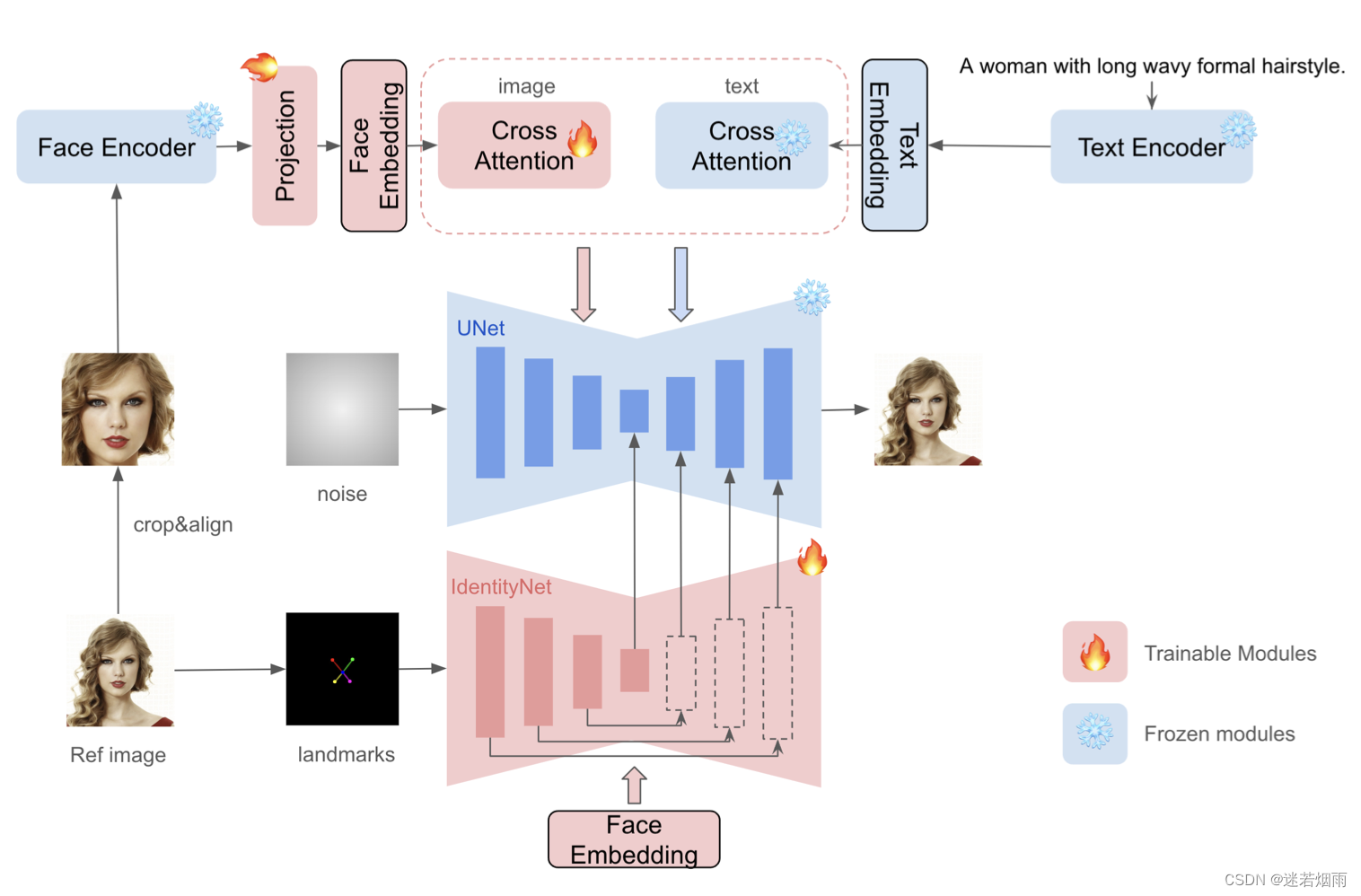
3. InstantID 小红书
InstantID彻底火了!来自中国的开源项目,图灵奖得主Yann LeCun点赞(附论文及源码)
一个基于扩散模型的图像生成解决方案,能实现从单一参考图像到多样化风格化写真的快速生成。用户只需上传一张自拍,20 秒就能得到定制版 AI 写真. 无论是古典油画中的贵族,或是未来都市中的赛博朋克英雄,多种风格,切换自如.
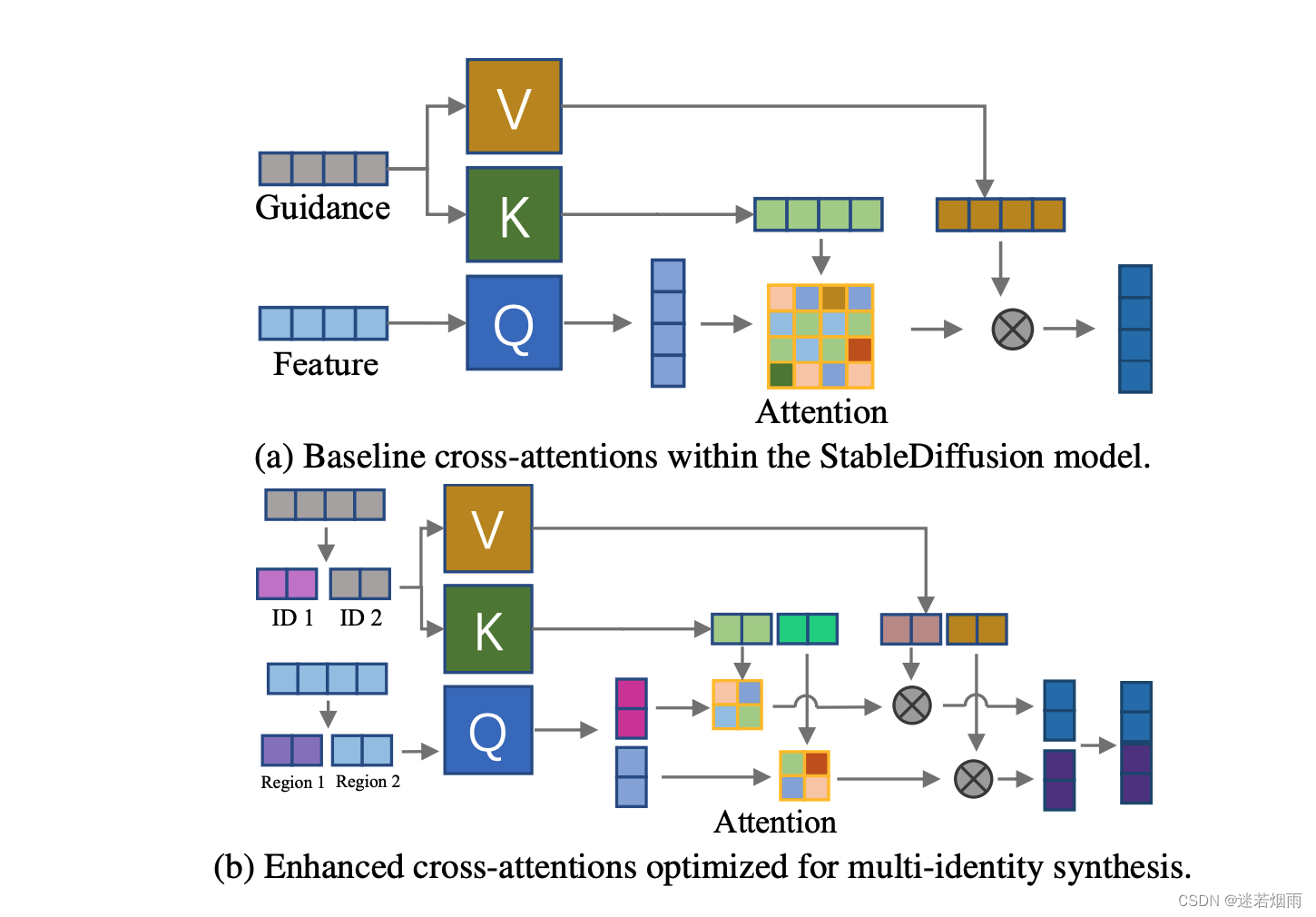
作为一个高效、轻量级、可插拔的适配器,它为预训练的文本到图像扩散模型赋予了强大的身份信息保留能力.InstantID 不训练文生图模型的 UNet 部分,仅训练可插拔模块,在推理过程中无需 test-time tuning,在几乎不影响文本控制能力的情况下,实现高保真 ID 保持

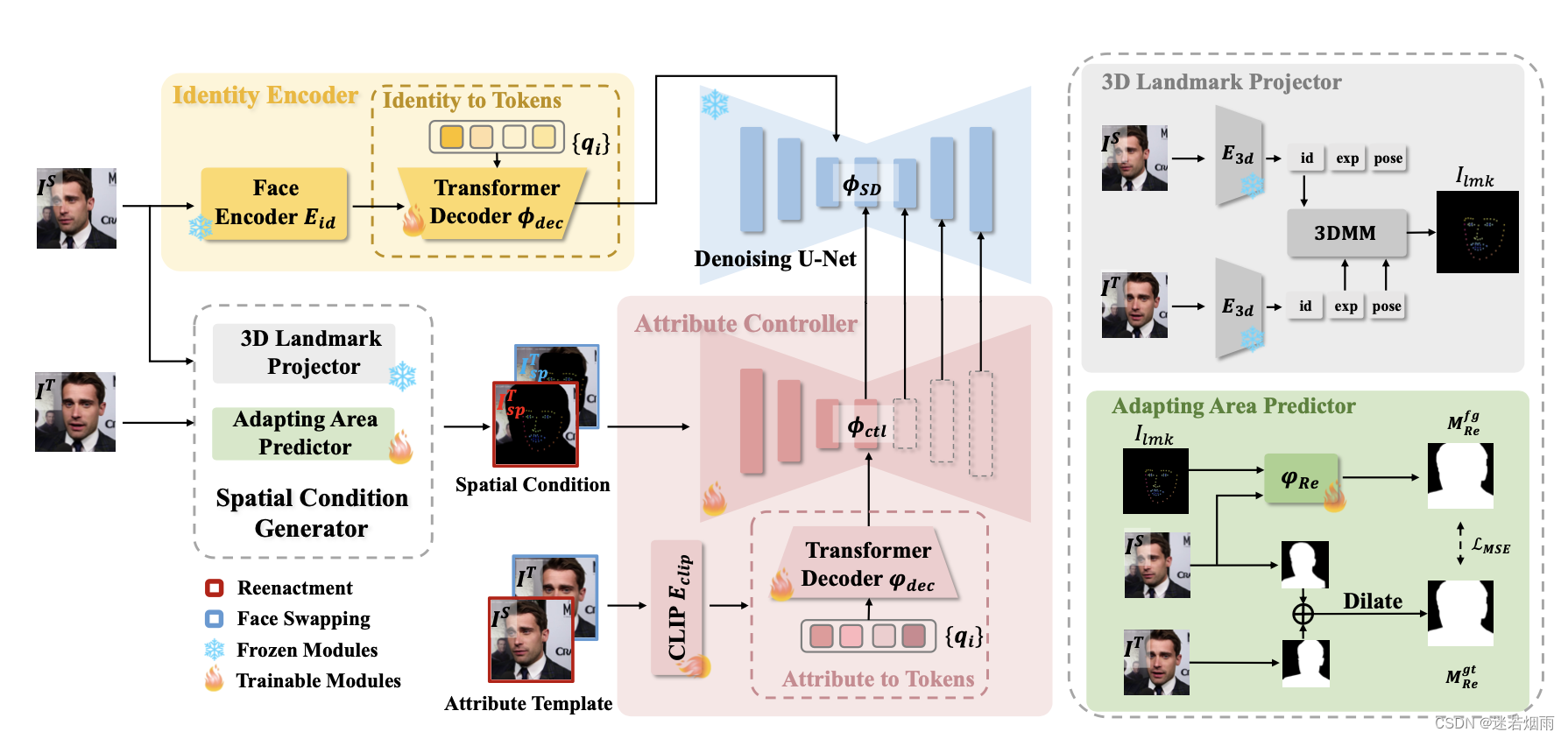
4. PuLID
Pure and Lightning ID Customization via Contrastive Alignment
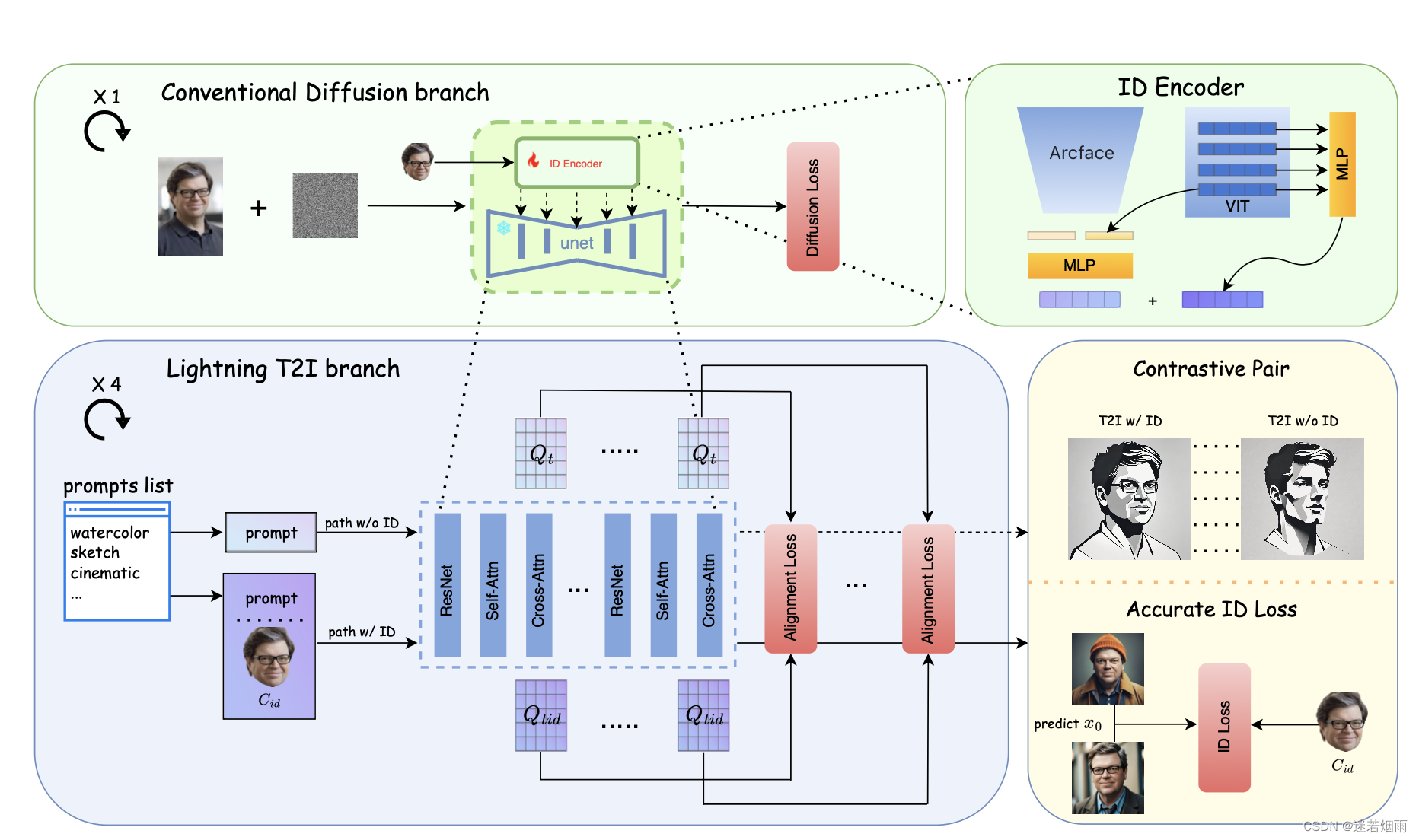
5. FlashFace
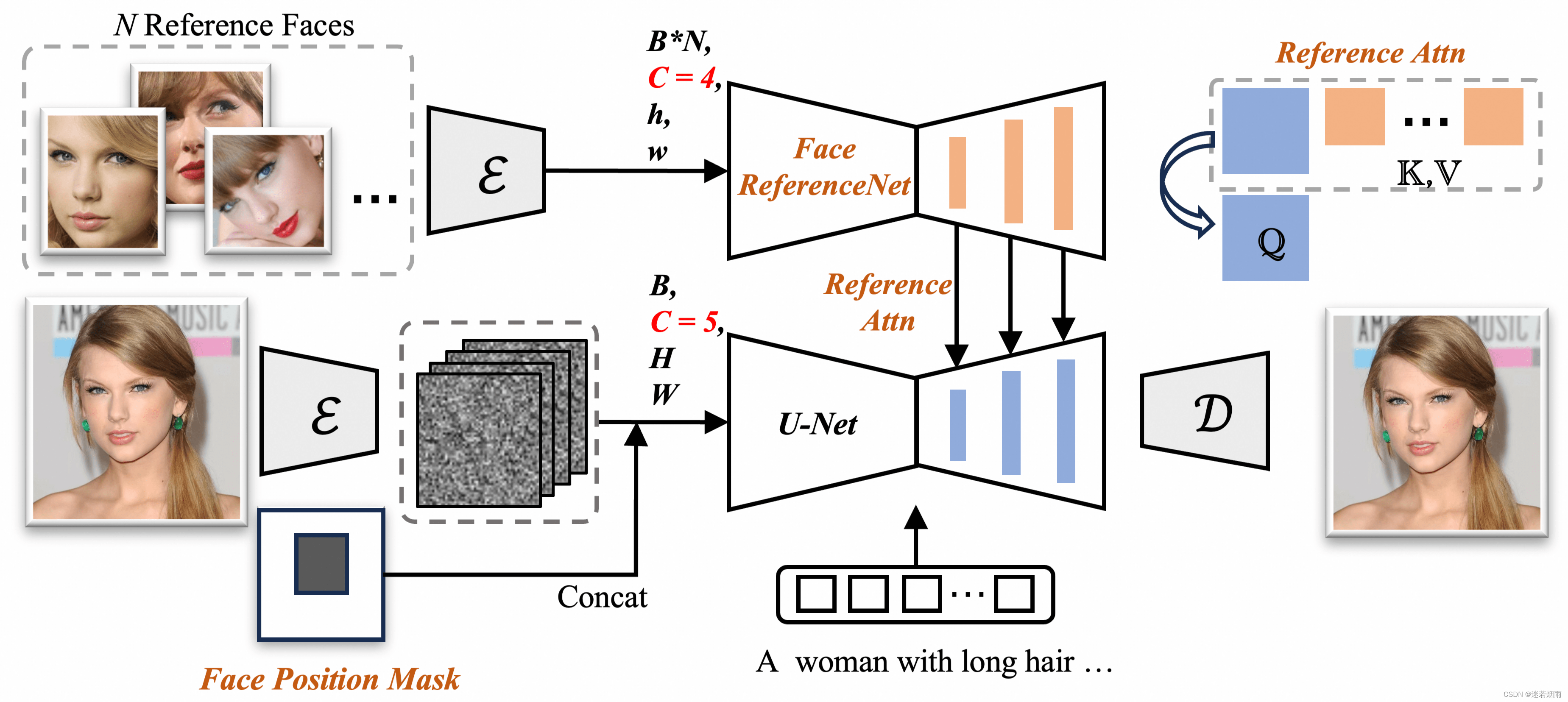
6. PhotoMaker 速度慢,150秒,和训Lora比没有显著优势
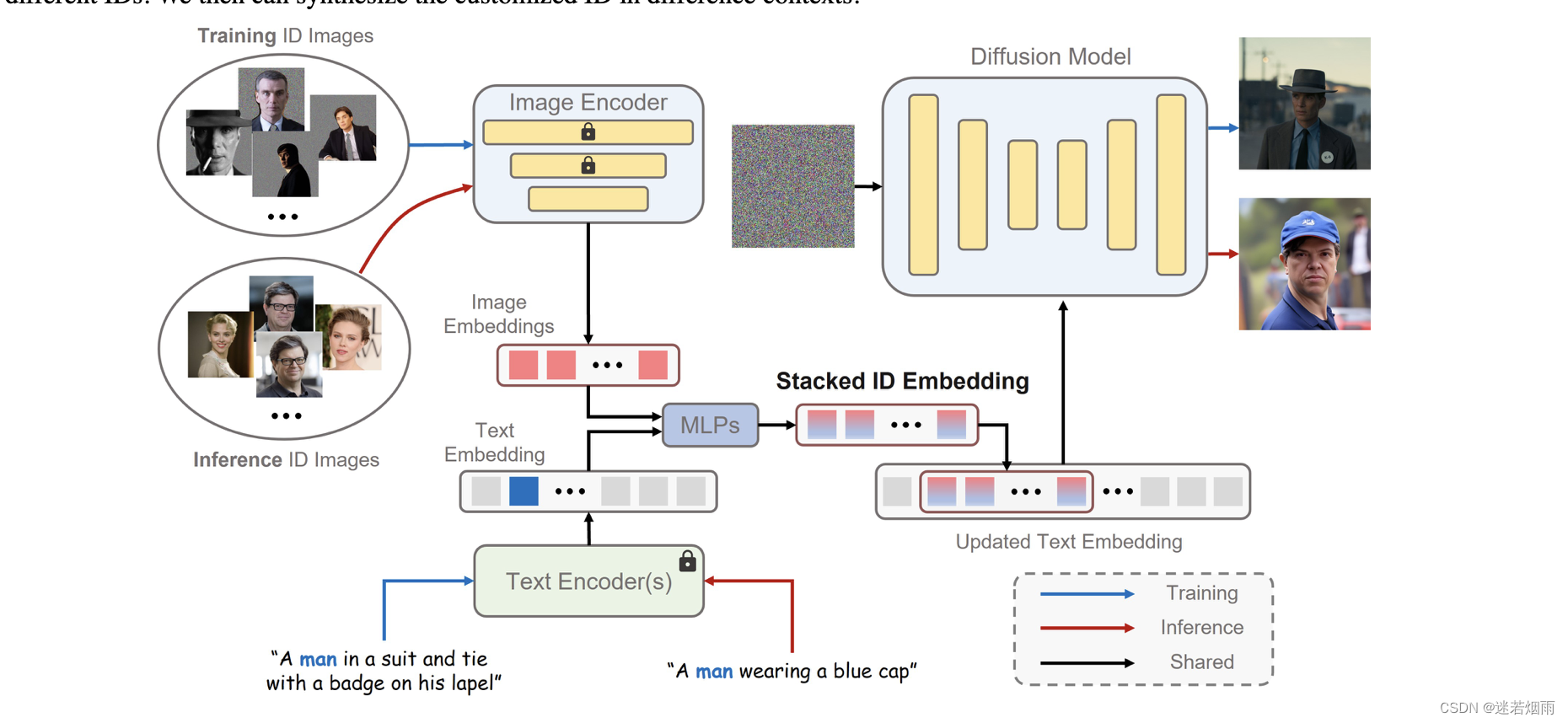
code、爆火!腾讯开源PhotoMaker:高效地定制化生成任意风格的逼真人类照片!
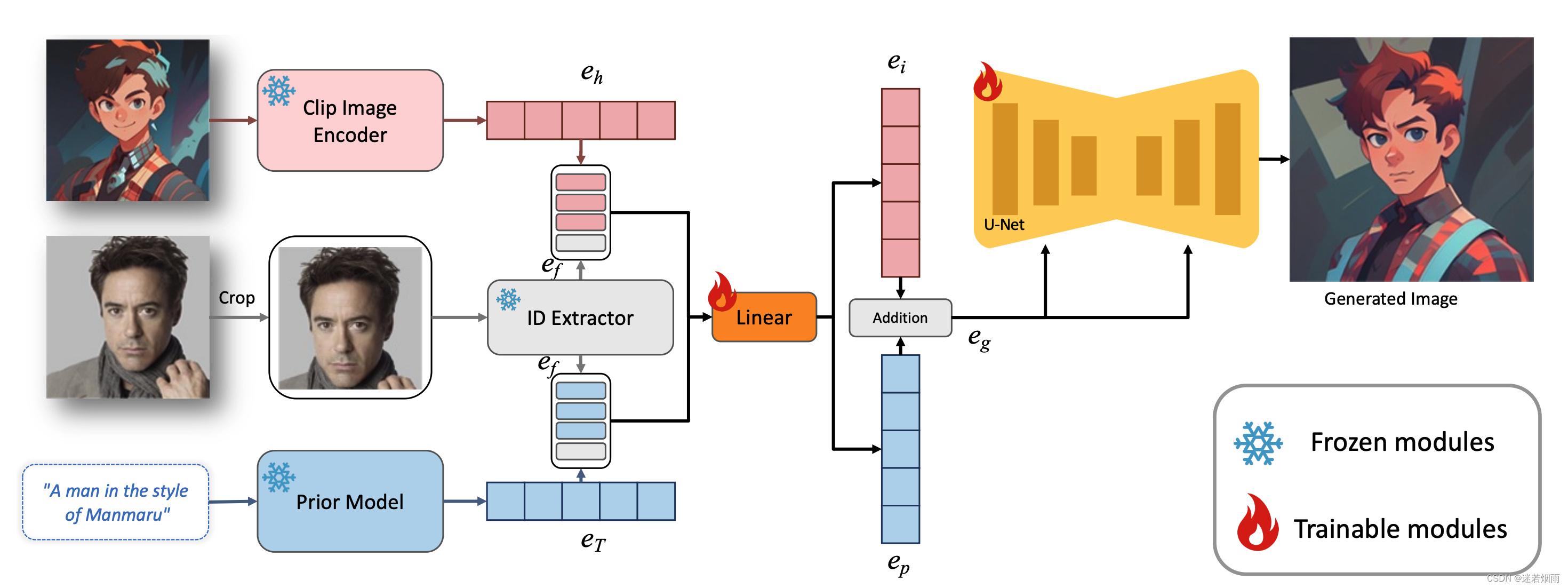
首先分别从文本编码器和图像编码器中获得文本嵌入和图像嵌入。然后,通过合并相应的类嵌入(如男人和女人)和每个图像嵌入来提取融合嵌入。接下来,沿着长度维度将所有融合嵌入连接起来,形成堆叠ID嵌入。最后,将堆叠的ID嵌入馈送到所有跨注意层,以自适应地合并扩散模型中的ID内容。需要注意的是,虽然在训练过程中使用的是相同ID,背景masked的图像,但是我们可以在推理过程中直接输入不需要背景失真的不同ID的图像,从而创建一个新的ID
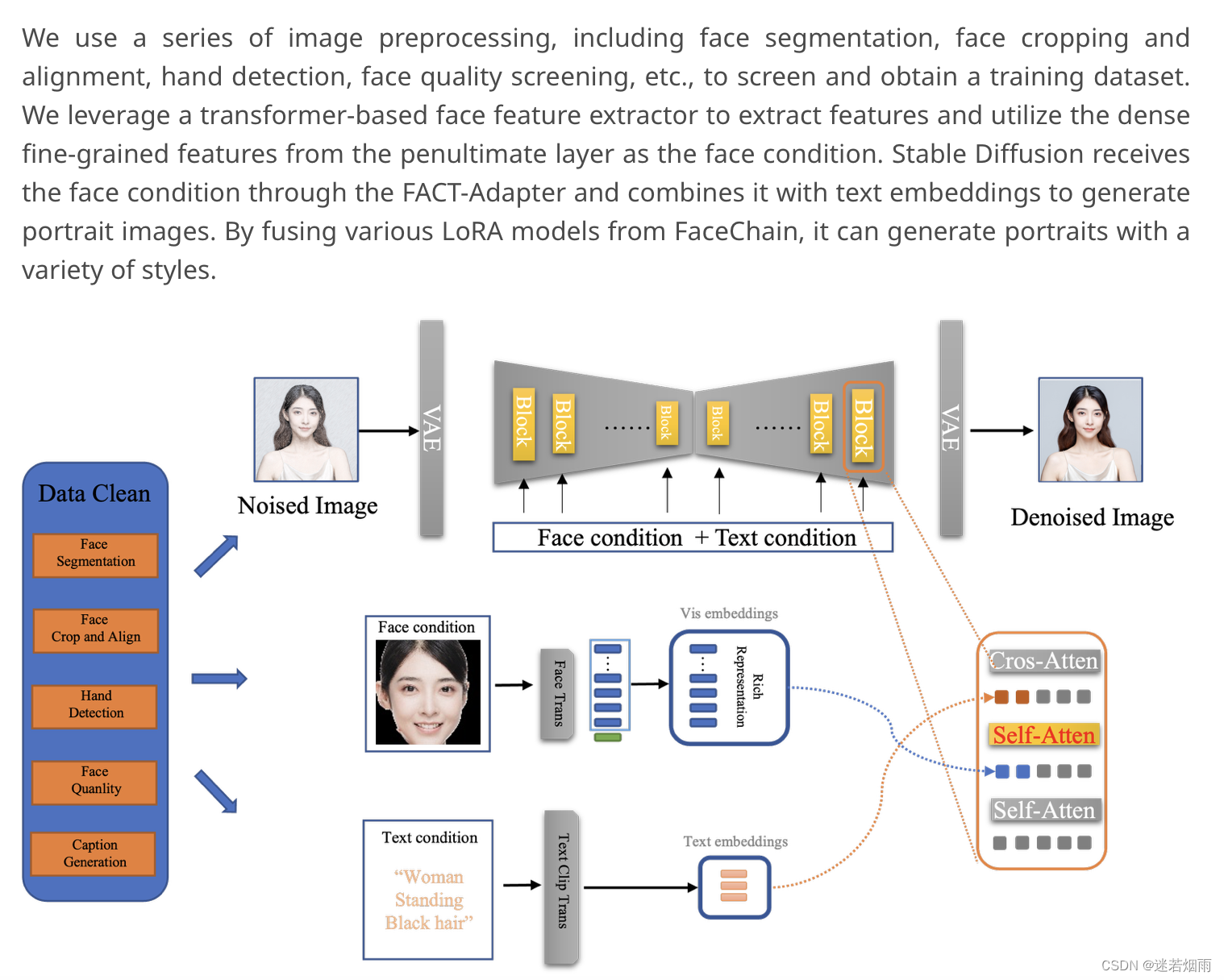
7. FaceChain-FACT 阿里开源
实测显存16G,速度15秒(全流程) ,纯推理6秒 @V100
FaceChain-FACT:开源10秒写真生成,复用海量LoRa风格,基模友好型写真应用
相比原版FaceChain,FaceChain FACT的人像生成体验有了质的飞跃
1.)在生成速度方面,FaceChain FACT成功摆脱了冗长繁琐的训练阶段,将定制人像的生成时间由5分钟大幅缩短到10s左右,为用户带来无比流畅的使用体验。
2.) 在生成效果方面,FaceChain FACT进一步提升了人脸ID保持的细腻程度,使其兼具真实的人像效果以及高质量的写真质感。同时,FaceChain FACT对FaceChain海量的精美风格以及姿态控制等功能具有丝滑的兼容能力,对于输入人脸图像光照不理想、表情夸张等情况也能准确从质量欠佳的图像中解耦出人物ID信息,保证生成写真图片具有高超的艺术表现力。
FaceChain-fact:Face Adapter for Human AIGC
训练lora
1. FaceStudio
FaceStudio: Put Your Face Everywhere in Seconds

2. 妙鸭相机 不开源
对话「妙鸭」产品负责人:AIGC 的产品第一天不收钱,就可能收不到钱
无论在哪里对于美和摄影的需求是存在的,因为人们总是希望为自己留下值得纪念的照片
妙鸭为什么会走红?最重要的因素是团队成员的坚定和努力。团队氛围简单、直接,目标清晰,追求极致的风格。我们花了三个月以上的时间打磨一个效果,以获得更好的用户体验和效果。第二是公司对创新的鼓励、支持、包容,以及看到一些阶段性成果之后,进一步的支援
怎么平衡出片的真实和美? 七八分像,两三分美。我们在定写实人像的业务方向时,提到真、像、美,这三个方向,一个是无 AI 感,然后能够尽可能像我,但要比我美。不管是美颜相机,还是每一代的拍摄产品,这算是常识
3. facechain
功能近似“秒鸭相机”?从代码层面一探究竟阿里达摩院 FaceChain
阿里出品,优点: 分成两个Lora,离线训练的风格Lora和需要在线训练ID Lora模型。生成的照片与原始照片非常相似,可以轻松分辨出同一张脸。这款应用实际上是一个换脸软件,它将原始人物的脸换成了指定的面孔。与其他换脸软件不同的是,它可以生成指定风格的图片。
缺点 训练时间长(数十分钟级)、推理时间长(数分钟级)、显存要求高(20G+)、GPU利用率有待提升,界面复杂,同时依赖翻墙和国内网络,下载体验差;不能处理风格图片,只能用于写真
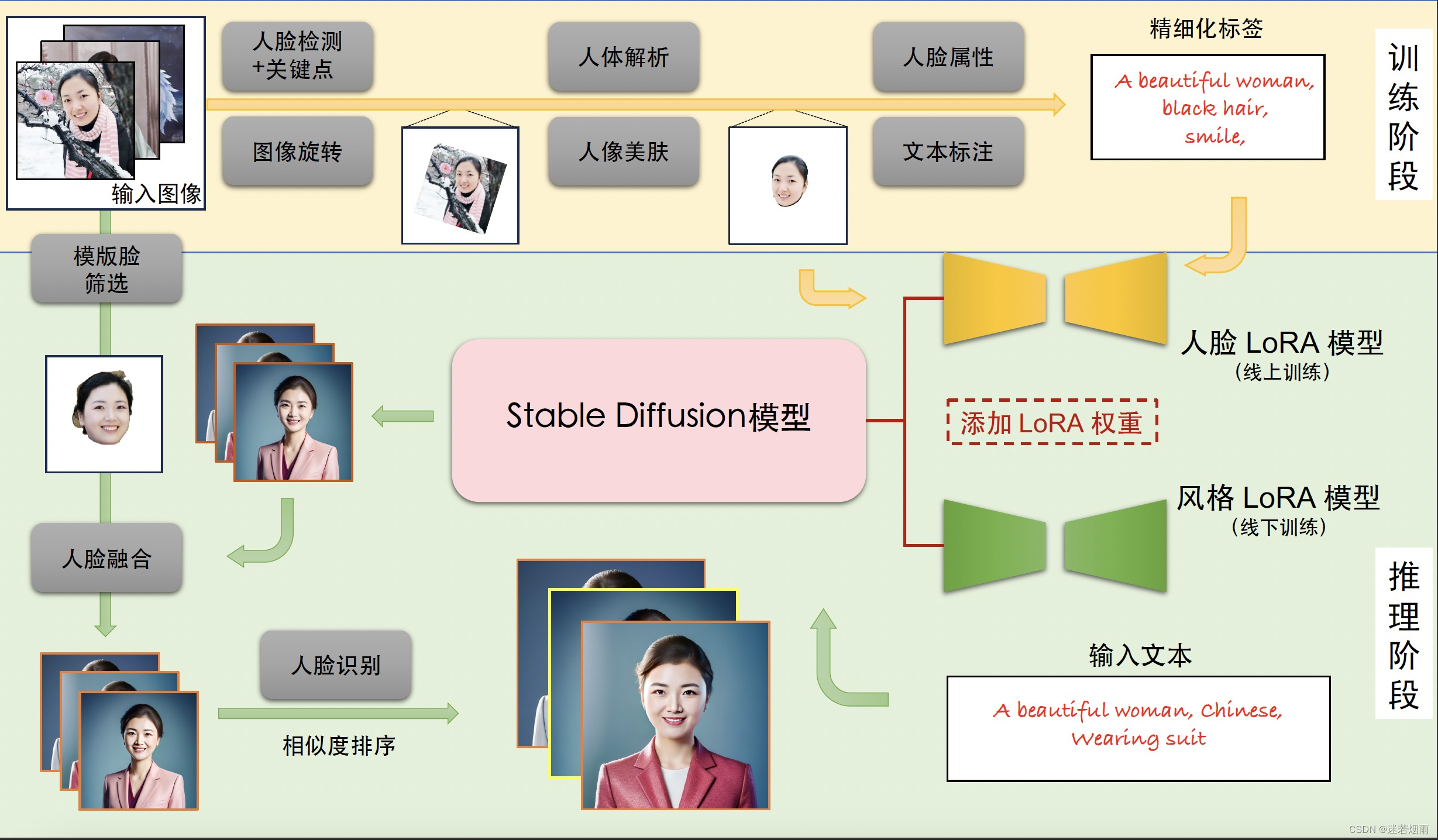
个人写真模型的能力来源于Stable Diffusion模型的文生图功能,输入一段文本或一系列提示词,输出对应的图像。考虑影响个人写真生成效果的主要因素:写真风格信息,以及用户人物信息。为此分别使用线下训练的风格LoRA模型和线上训练的人脸LoRA模型以学习上述信息。个人写真模型的能力分为训练与推断两个阶段,训练阶段生成用于微调Stable Diffusion模型的图像与文本标签数据,得到人脸LoRA模型;推断阶段基于人脸LoRA模型和风格LoRA模型生成个人写真图像
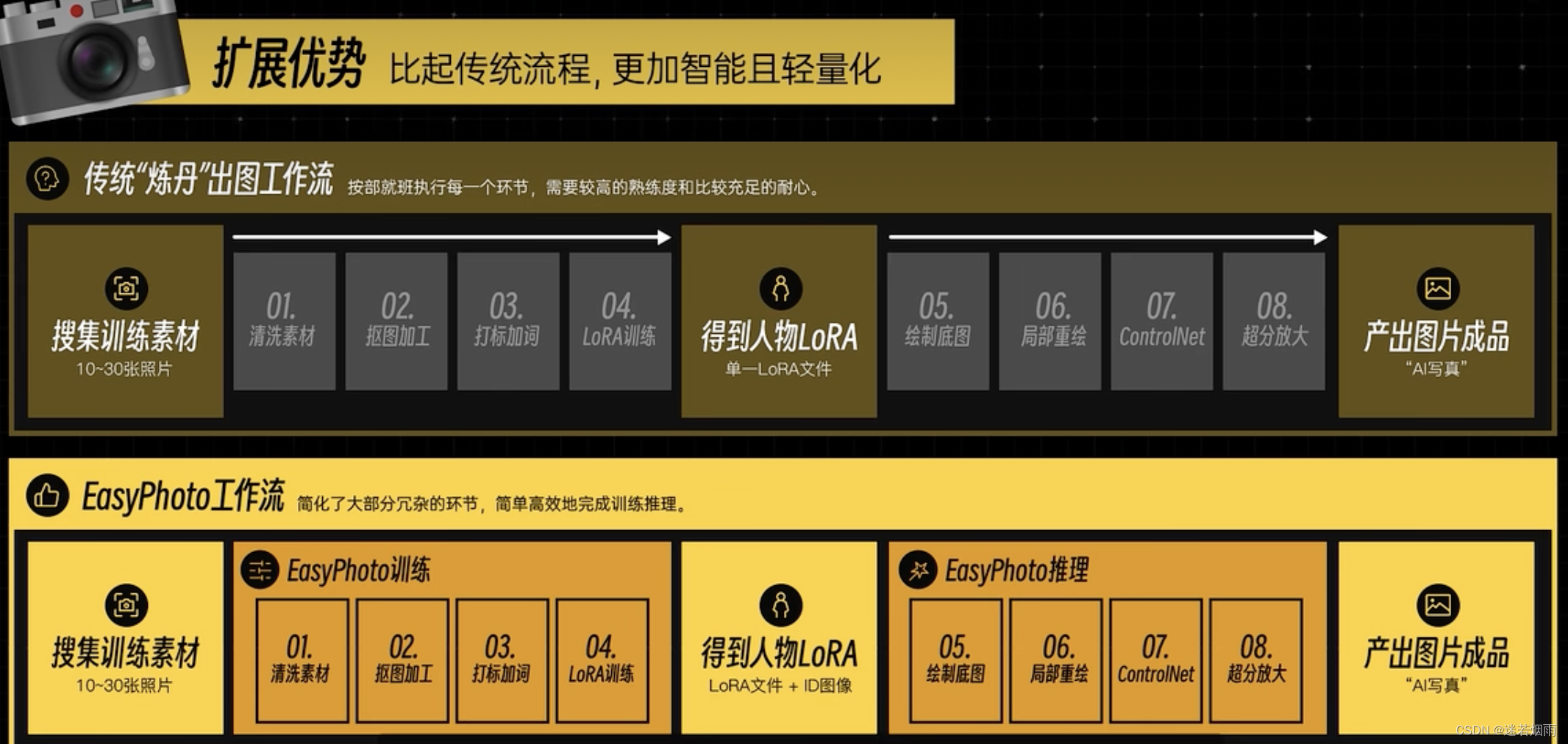
4. EasyPhoto:高质量SDWebui艺术照插件
视频教程: 8张照片训练个人LoRA,一分钱不花打造“AI写真”
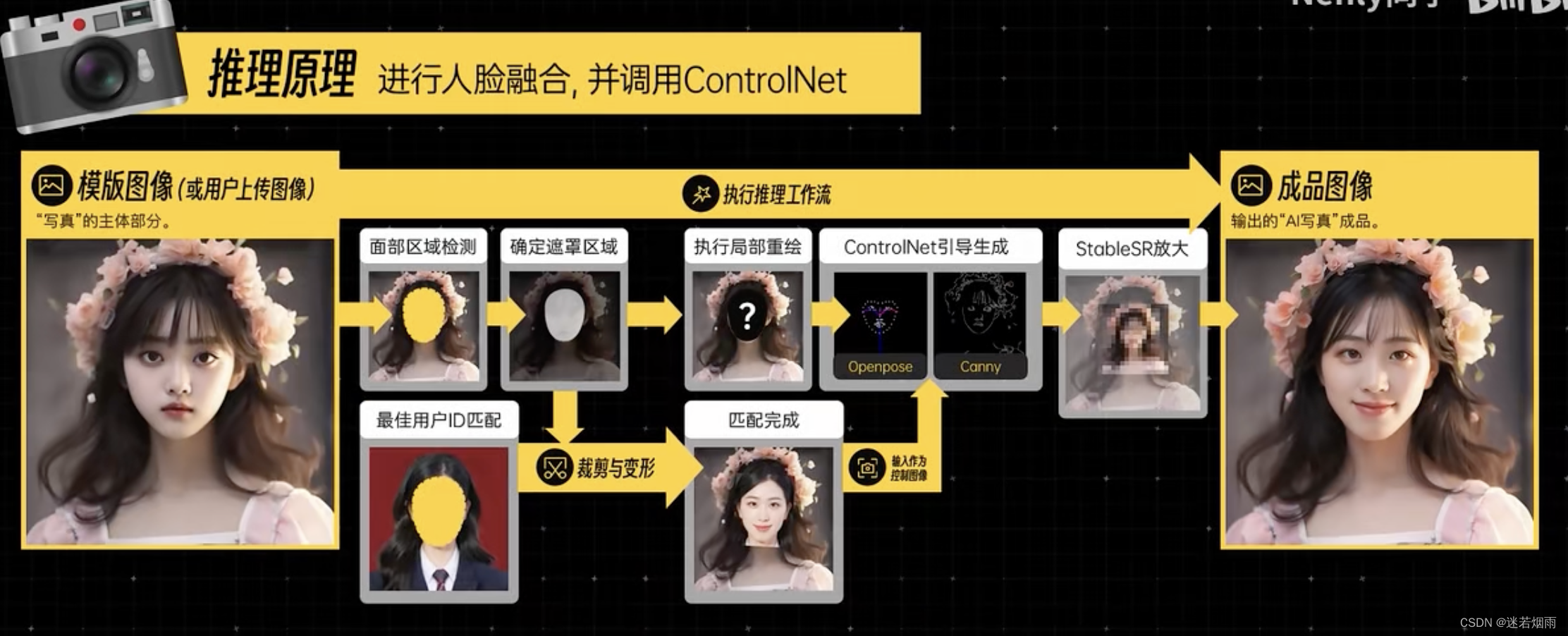
EasyPhoto 人像训练与生成原理详解

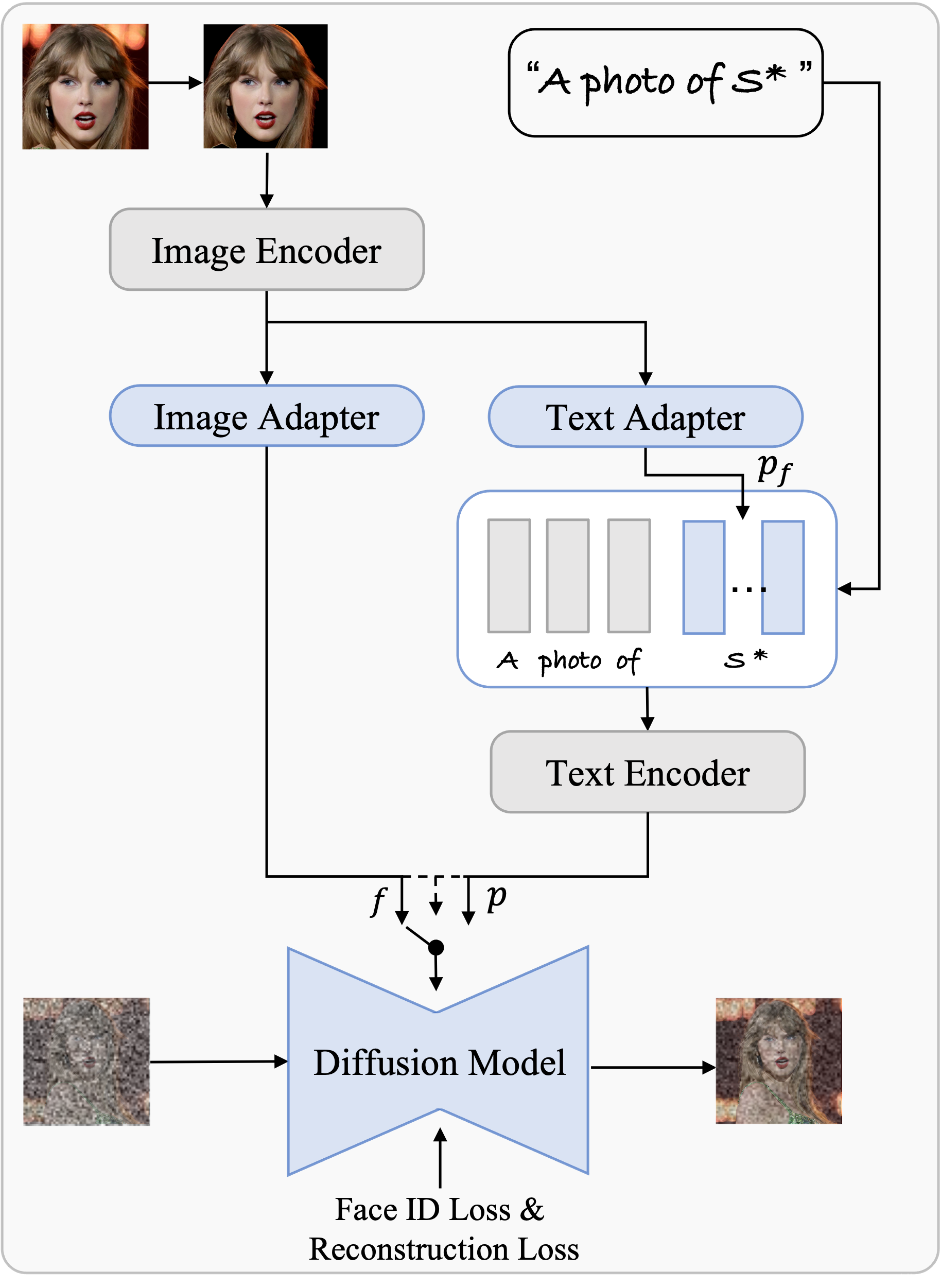
5. PhotoVerse
6. 无需Lora炼丹也能保持同一人物?ControlNet新功能Refrece Only测评
参考模式这项新功能需要我们将插件更新到1.1.153版本及以上
只在controlnet中上传一张狗狗的图片,引导词也非常简练,仅仅是 "a dog running on grassland, best quality, ...",然后就得到了主体相似、风格也相似,但是动作符合引导描述的图像,效果可以说非常惊艳
如果能够省去lora训练的成本确实很有诱惑,毕竟训练lora需要很好的显卡还要大量时间处理图片
- 参考模式可以将给定的一张图作为生成图的参照物,通过相对简单的引导词即可用参考图的内容生成到新图中
- 相比controlnet草稿模式,参考模式拥有很多的随机发挥的灵活性
- 参考模式可以大大减轻编写引导词的工作量
- 结合open pose或者多次迭代修正,可以实现类似lora的效果
- 参考模式能够比重绘更轻易的实现2d,2.5d,3d的转换



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









