






摘要
由于视频内容在互联网上的普及,视频与文本之间的信息检索引起了研究者的广泛兴趣,这是一项具有挑战性的跨模式检索任务。一种常见的解决方案是学习一个联合嵌入空间来度量跨模态相似性。然而,许多现有的方法或者更多地关注文本信息、视频信息或跨模态匹配方法,而较少关注这三种方法。我们认为,一个好的视频文本检索系统应该考虑这三点,充分利用两种模式的语义信息,并考虑全面匹配。在本文中,我们提出了一种用于视频文本检索任务的分层跨模式图一致性学习网络(HCGC), 该网络考虑了多级图一致性对视频文本匹配的影响。具体地说,我们首先为视频构造一个层次图表示,它包括从全局到局部的三个层次:视频、剪辑和对象。同样,根据句子、动作和实体之间的语义关系构建相应的文本图。然后,为了更好地学习视频图和文本图之间的匹配,我们设计了三种类型的图一致性(直接和间接):图间并行一致性、图间交叉一致性和图内交叉一致性。在不同的视频-文本数据集上的大量实验结果证明了该方法在文本-视频和视频-文本检索方面的有效性。
介绍
视频文本检索可以分为两种类型:一种是根据用户的需求在自然语言中检索视频(text-to-video),另一种是检索最匹配视频内容的文本(video-to-text)。
为了弥合这两种模式之间的差距,早期的方法[2,6,16,49]将视频内容转换为一组预定义的文本描述,称为视觉概念。文本也被转换成一组概念,然后,视觉和文本概念之间可以使用单模态匹配。然而,有两个问题。一是准确概念的选择可能具有挑战性。即使对概念进行了准确分类,它们也可能无法充分表示视频的时间上下文和文本的复杂语义。由于概念的局限性,使用单词嵌入[30]和视觉特征[21]方法来学习更好的信息表示,并使用联合嵌入空间来测量跨模态相似性
许多现有的方法要么更多地关注文本信息、视频信息,要么关注跨模态匹配方法,但对这三种方法全部包含的关注较少。一种常见的解决方案是视频和文本向量视为全局表示映射到联合嵌入空间,并计算它们之间的语义相似度,如图1(a)所示。当遇到复句时,一个简单的全局向量可能无法充分表示信息。Lin等人[25]基于句法注释,使用结构化语义形式来表示句子(其特点是按程序语言的语法结构来定义语义)。(最近,Chen等人[4]将文本分解为包含事件、动作、实体三个层次的分层语义图也就是分段),并通过基于注意的图推理生成分层文本嵌入。除全局级匹配外,它们还添加了本地级视频文本匹配,如图1(b)所示。
虽然这些方法在不同方面都取得了性能上的提高,但学习文本和视频之间的语义对齐仍然是一个具有挑战性的问题。
我们认为一个好的视频-文本检索系统应该兼顾这三点,在考虑综合匹配的同时,充分利用视频和文本的语义信息。针对这一目标,本文提出了一种基于细粒度结构化视频文本图表示的多级图一致性学习网络(Hierarchical CrossModal Graph Consistency Learning Network, HCGC)。
HCGC
具体地说,我们首先为视频构造一个层次图表示,它包括从全局到局部的三个层次:视频、剪辑和对象。通过时间聚合模块提取视频的全局级表示。首先,利用时序分割算法[34]根据镜头边界和语义边界对视频片段进行分割。然后,将视频片段紧密连接,利用图卷积网络学习不同视频片段之间的潜在语义关系。对于每个片段,通过从帧区域中基于注意的聚合获得对象级表示。同样,根据句子、动作和实体层之间的语义关系构建相应的文本图。然后,为了学习视频图和文本图的不同层之间更好的匹配,我们设计了三种类型的图一致性(直接和间接):图间并行一致性(学习不同模态图对应层之间的直接一致性),图间交叉一致性(学习不同模态图的不同层之间的间接一致性)和图内交叉一致性(学习同一模态图的不同层之间的间接一致性),如图1©所示。

贡献总结:
我们提出了一种用于视频文本检索任务的层次化跨模式图一致性学习网络(HCGC),该网络为视频和文本构造层次化的图表示,并利用多级图一致性帮助进行跨模式匹配。
我们在视频和文本图的不同层之间设计了三种类型的图一致性(直接和间接):图间并行一致性、图间交叉一致性和图内交叉一致性,以学习更好的跨模式匹配。
我们在不同的数据集上进行了大量的实验,以证明我们的方法可以在文本到视频和视频到文本检索方面取得更好的性能。
方法
图2给出了用于视频文本检索的分层跨模式图一致性学习网络(HCGC)的概述,该网络由三个主要部分组成:1)分层文本图模块;2) 分层视频图形模块;3)多级跨模态图一致性学习模块。

层次文本图
将文本转换为语义图已经得到了广泛的探索,在这里,我们只需遵循将视频描述分解为三个层次语义级别的工作[4],分别捕获全局事件、局部动作和实体。
具体来说,给定一个包含单词{s1,···,sm}的视频描述,我们首先使用一个双向GRU5来生成相应的上下文感知单词嵌入{w1,…,wm}。层次文本图的第一级是s的全局句子表示,它捕获视频描述的事件级别信息。我们利用注意机制来聚合词语嵌入,从而关注句子中的重要事件
全局句子表示
S
g
S_g
Sg:

为了获得更细粒度的语义信息,利用语义角色解析工具包(这是个啥? 再看看吧)[36]提取句子中的动词、名词短语及其语义角色关系,
for instance, <girl>-<putsback>-<product>.
由于事件由不同的动作组成,所以文本图的第二级是动作级别,其节点是动词短语。那么剩下的第三个层次自然就是实体层次,它的节点是名词短语。
对于动作节点和实体节点,我们对每个节点中的单词应用最大池,作为动作节点表示Sa={sa,1, …,sa,na},和实体节点表示Se={se,1, …,se,ne},对于边缘连接,动作节点通过直接边缘连接到句子节点。
由于句子节点包含全局信息,在图形推理过程中,动作节点之间的上下文关系可以从句子节点隐式学习。实体节点和动作节点之间的边界由实体相对于动作的语义角色决定。在图2中,我们给出了一个构建的层次文本图的示例。(其实就是看情况而定,但是这个是程序定的 吗,好像是上面的那个语义角色解析工具包)
在构建文本图之后,使用图注意网络来学习不同层次节点之间的语义交互。图形注意网络用于从相邻节点选择上下文信息,以增强每个节点的表示:(看不懂系列)
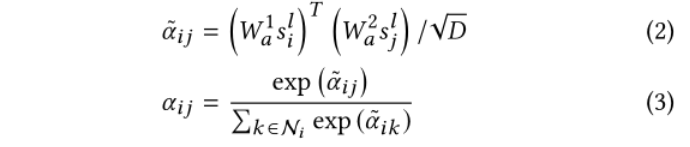
然后,利用共享转换矩阵wt将上下文信息从参与的邻居节点传播到具有剩余连接的节点: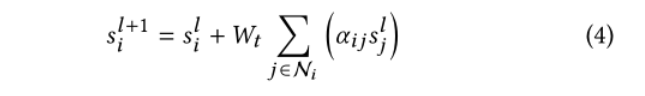
在基于注意的图推理过程之后,我们可以得到分层文本图的最终节点表示,用于我们的跨模态图一致性学习。
分层视频图
与文本不同,将视频直接解析为层次结构可能具有挑战性。我们提出了一种真正分层的视频图表示方法,它还包括三个层次:全局视频层、剪辑层和对象层,对应于文本图的三个层次。
具体地说,给定一个输入视频序列,我们首先提取帧特征,用f={f1,····,fn}表示。对于全局视频级别,我们利用注意感知聚合机制将重要的帧特征聚合为一个全局向量表示vη,类似于方程1。
我们的分层视频图的第二级由视频剪辑组成,其中包含单个摄像机镜头或连续动作片段。为了获得这些视频片段,我们使用了一种时间分割算法(这又是啥)[34],用新的帧特征相似度替换相似度矩阵。它利用动态规划来最小化段内核方差,目标函数如下所示:
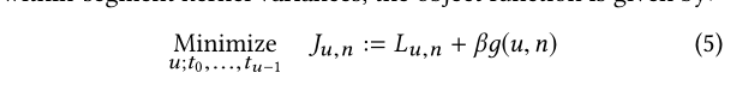
(看不懂了)
跨模态图一致性
如图2所示,我们的跨模式图一致性匹配包括三种类型:图间并行一致性、图间交叉一致性和图内交叉一致性。
图间并行一致性类似于[4]中介绍的匹配方案,其目的是匹配视频和文本图的相应级别之间的信息。对于全局到全局的层次,我们使用余弦相似性来度量全局视频和文本表示的相似性。然后归一化,
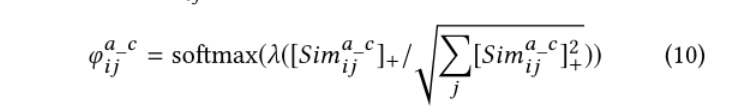
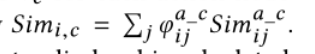
通过汇总所有聚合的相似性,计算动作与剪辑级别的最终匹配相似性,表示为
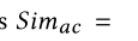
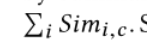
同样,我们可以获得实体与对象级别的匹配相似度
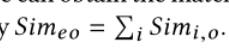
通过平均上述三个平行水平的跨模态相似性,我们可以获得图间平行相似性
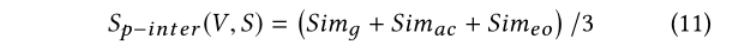
我们利用对比排序损失作为训练目标来学习图间并行一致性
三重损失那一套,图间并行一致性作为一种基本匹配方案,只考虑视频图与文本图同一层之间的信息匹配。而且直接利用上面描述的相似度来学习不同层之间的一致性可能不是一个好选择,因为我们希望不同级别的图为细粒度匹配提供不同的信息。因此,我们提出另外两种类型的图一致性来提供间接的跨层一致性约束。
图间交叉一致性
旨在学习视频和文本图形不同层之间的间接一致性。
=我们计算
v
g
i
v^i_g
vgi和
s
a
s_a
sa之间的相似性。然后,我们将相似性标准化(归一化)如下:

(这一块的公式看的也挺懵懵的)
图内交叉一致性旨在学习视频和文本图形中不同层之间的间接一致性。因为除了相应的级别之外,它几乎与图间交叉一致性相同。
结论
在这项工作中,我们提出了一种用于视频文本检索任务的分层跨模式图一致性学习网络(HCGC),该网络考虑了视频文本匹配的多级图一致性。具体来说,我们首先为视频构建一个层次图表示,它包括从全局到局部的三个层次:视频、剪辑和对象。同样,根据句子、动作和实体之间的语义关系构建相应的文本图。然后,为了更好地学习视频和文本图之间的匹配,我们设计了三种类型的图一致性(直接和间接):图间并行一致性、图间交叉一致性和图内交叉一致性。在不同视频文本检索数据集上的大量实验结果证明了我们的方法在文本到视频和视频到文本检索上的有效性。在未来,我们将通过探索视频(如音频)中的更多模式和更复杂的交叉模式图结构来改进我们的方法。















 1462
1462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









