







 VFDB是一个专注于收集和更新细菌病原体毒性因子信息的综合数据库,自2004年起致力于提供详尽的已知病原体毒性因子,包括结构特征、功能和机制。它通过统一命名和分类系统,解决不同菌株同源性VF命名带来的混乱,便于深入研究和泛细菌数据分析。
VFDB是一个专注于收集和更新细菌病原体毒性因子信息的综合数据库,自2004年起致力于提供详尽的已知病原体毒性因子,包括结构特征、功能和机制。它通过统一命名和分类系统,解决不同菌株同源性VF命名带来的混乱,便于深入研究和泛细菌数据分析。
VFDB数据库介绍
官网:VFDB: Virulence Factors of Bacterial Pathogens (mgc.ac.cn)
About VFDB
The virulence factor database (VFDB) is an integrated and comprehensive online resource for curating information about virulence factors of bacterial pathogens. Since its inception in 2004, VFDB has been dedicated to providing up-to-date knowledge of VFs from various medically significant bacterial pathogens.
The motivation for constructing VFDB was twofold:First, to provide in-depth coverage major virulence factors of the best-characterized bacterial pathogens, with the structure features, functions and mechanisms used by these pathogens to allow them to conquer new niches and to circumvent host defense mechanisms, and cause disease. Second, to provide current knowledge of the wide variety of mechanisms used by bacterial pathogens for researchers to elucidate pathogenic mechanisms in bacterial diseases that are not yet well characterized and to develop new rational approaches to the treatment and prevention of infectious diseases.Definitions
A bacterial pathogen is usually defined as any bacterium that has the capacity to cause disease. Its ability to cause disease is called pathogenicity.
Virulence provides a quantitative measure of the pathogenicity or the likelihood of causing disease.
Virulence factors refer to the properties (i.e., gene products) that enable a microorganism to establish itself on or within a host of a particular species and enhance its potential to cause disease. Virulence factors include bacterial toxins, cell surface proteins that mediate bacterial attachment, cell surface carbohydrates and proteins that protect a bacterium, and hydrolytic enzymes that may contribute to the pathogenicity of the bacterium.About VF category
Traditional microbiological studies generally rely on laboratory bacterium isolation and cultivation, while recent NGS-based metagenomic analyses have revealed a large number of unculturable bacteria, the majority of which are yet uncharacterized. Thus, the in-depth mining of the panbacterial microbiome data in terms of pathogenesis requires a well-organized reference category of all established bacterial VFs from various known pathogens. However, the independent naming of homologous VFs in different bacteria leads to considerable confusion and hampers follow-up panbacterial analyses. Therefore, a well-defined classification scheme with a unified nomenclature is essential for future efficient data mining of bacterial VFs.
To better organize and present bacterial VFs in the database, the VFDB proposed an individual simplified classification scheme for each bacterial genus based on field conventions since inception in 2004. Nevertheless, the previous classification schemes of different bacteria are generally independent of each other, although they share certain similarities. Since the release of 2021, we introduced a general VF category applicable to various bacterial pathogens in the database and reorganized the VFDB dataset accordingly to make it readily applicable for future panbacterial data mining.
Since the majority of the current classifications of various bacterial VFs have proven very useful and durable for phylogenetic analyses, we have tried to maximally follow the existing conventions based on extensive literature mining. Thus, the newly proposed general classification scheme would be instantly familiar to and readily acceptable by traditional bacteriologists. However, unlike the previous scheme proposed in the 2012 release, which contains only four major bacterial VF categories (i.e., adhesion and invasion, secretion system, toxin, and iron acquisition), the newly established general classification scheme was designed to be a comprehensive system capable of covering all known bacterial VFs.
数据准备
-
获取vfdb数据库:Protein sequences of core dataset(VFDB_setA_protein.fas)
-
获取基因组序列:(示例数据:GenBank: CP002956.1),进行比对的数据需要为编码蛋白质的氨基酸序列,这里下载的是已经完成开放阅读框预测的氨基酸序列。
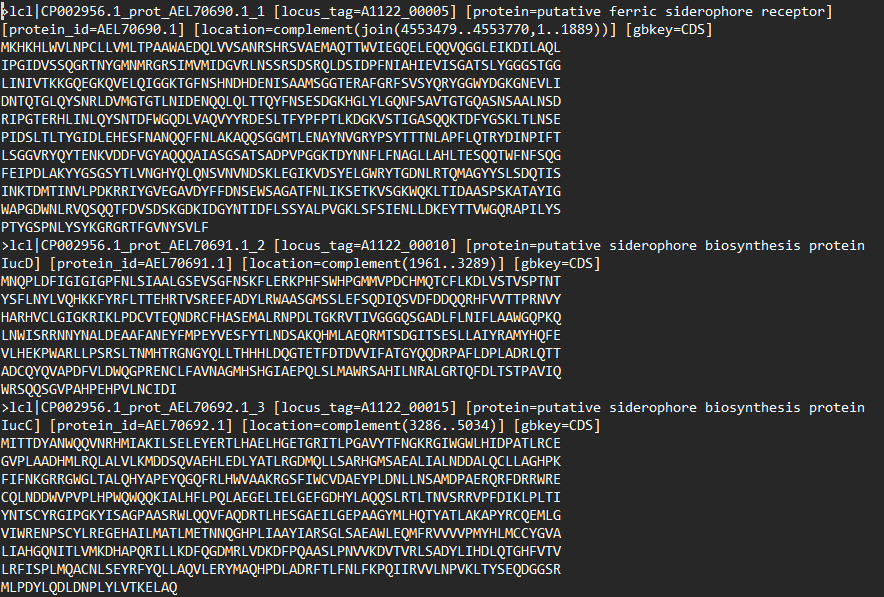
实现毒力因子的预测
软件版本:
Linux 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
conda 23.10.0
diamond version 2.1.8
-
构建数据库
conda activate diamond diamond makedb --in VFDB_setA_pro.fas --db VFDB_setA_pro -
进行比对注释
diamond blastp --db VFDB_setA_pro.dmnd --query sequence.txt --evalue 1e-5 --query-cover 90 --subject-cover 90 --range-cover 90 --id 60 --out vf.txt注释结果:各列含义qseqid sseqid pident length mismatch gapopen qstart qend sstart send evalue bitscore
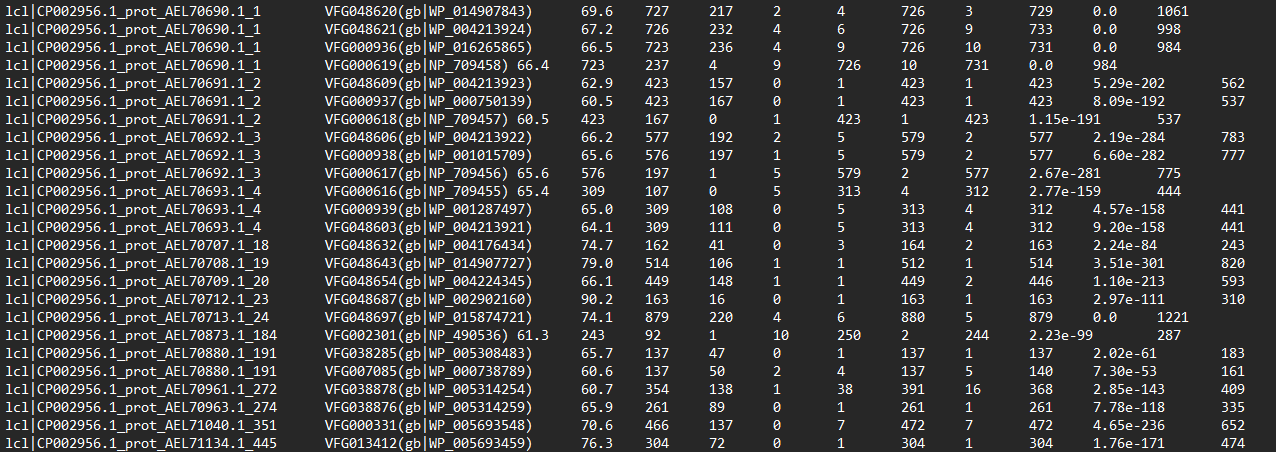
-
在注释结果中加入毒力因子信息:查看注释结果发现只显示毒力因子id,没有详细的名称类别等信息,我们可以通过把注释结果文件与
VFDB_setA_pro.fas进行比对来添加毒力因子的详细信息。grep "^>" VFDB_setA_pro.fas | sed 's/^>//g' > VFDB_setA_id.txt awk '{print $2}' vf.txt | while read -r line do grep -F "$line" VFDB_setA_id.txt >> matches.txt done paste vf.txt matches.txt > vf_detail.txt查看添加毒力因子信息后的数据:
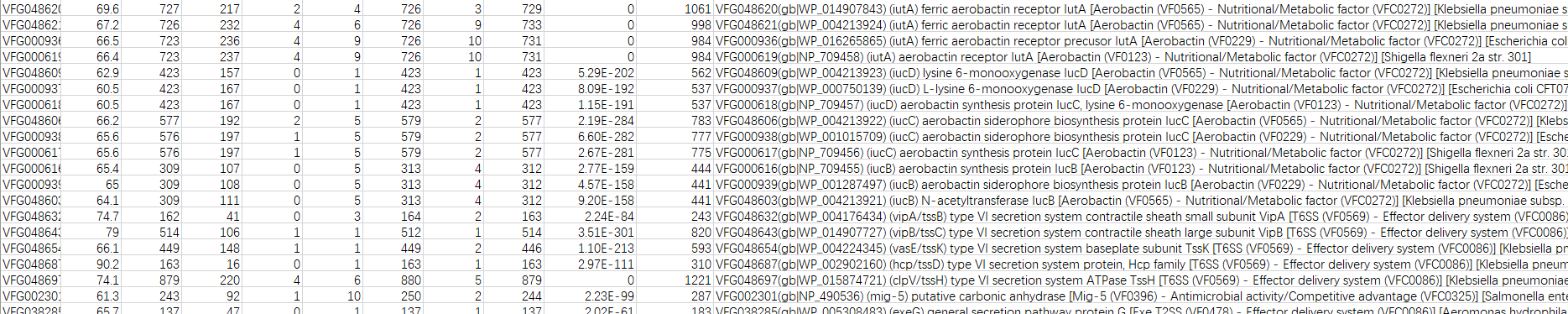
-
分割毒力因子信息列(原始信息太长,不方便查看)
主要目的是获取毒力因子VF开头的VFid,比如VF0394,可以通过这个id在VFDB官网上查找关于该毒力因子的详细信息。
awk -F'\t' '{match($NF, /\[([^\]]+)\]/, a); print $0 FS a[1]}' vf_detail.txt > output.txt mv output.txt vf_detail.txt awk -F'\t' '{match($NF, /\(([^\)]+)\) -/, a); match($NF, /- ([^-\n]*)$/, b); print $0 FS a[1] FS b[1]}' vf_detail.txt > output.txt mv output.txt vf_detail.txt最终数据:
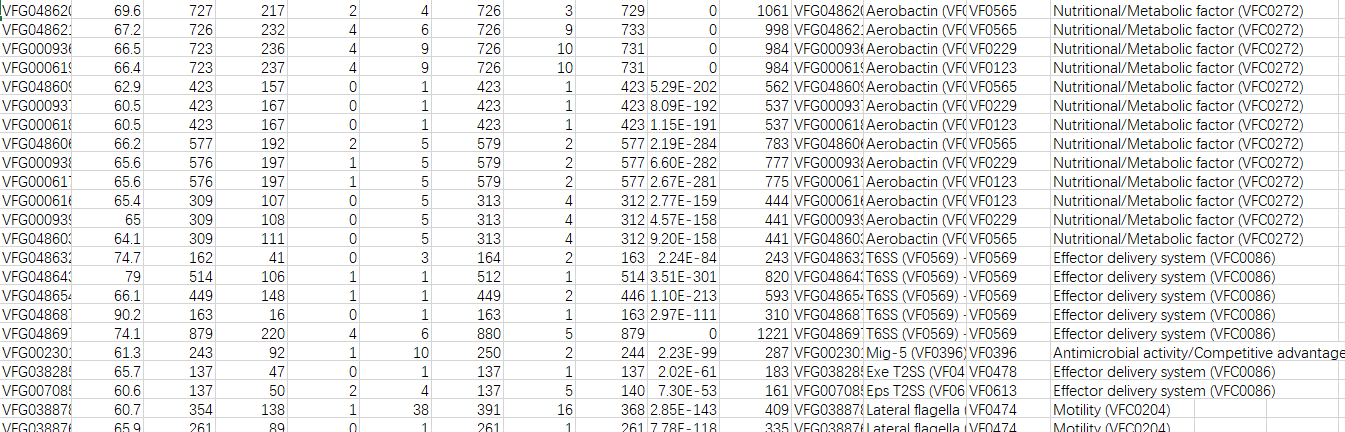
-
利用最终数据进行后续的统计分析。


















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









