- 博客(35)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 Android Studio导入外部数据库(使用Sqlite expert pro创建外部数据库)
在各个博客网站查询了很多方法,虽然能够导入,但是表是空的,个人判断是外部数据库类型(如后缀为db,sql)的原因,改为sqlite类型的数据库就可以正常导入所有外部数据库的信息了,以下是导入的几个步骤:方法一是使用虚拟机的目录的upload方法直接导入,具体步骤去查其他博主的吧,这里主要讲使用代码来写入外部的数据库: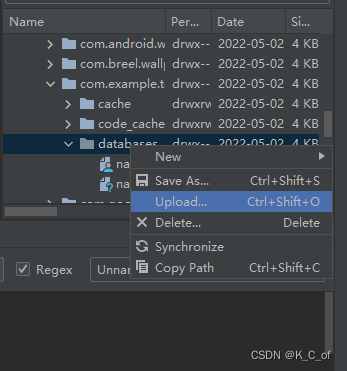方法二,代码导入: 1.
2022-05-03 00:20:36
 3720
3720
原创 56个民族的sql、excel等资源
链接:https://pan.baidu.com/s/1ye-WXAkAiOIQaq60SoQFnw提取码:jcls文档好像不能放在博客上面吧
2022-04-29 00:40:28
1454
原创 使用Android-PickerView 出些问题的可能解决方案
Android-PickerView 主要是个级联选择器,很好用的插件:GitHub下载地址1.无法下载导入插件Android-PickerView在项目根目录settings.gradle中更换仓库(注意,一些教程里边的url没有使用https协议,可能会导致不成功,所以要使用https):pluginManagement { repositories {/* gradlePluginPortal() google() mavenCentr
2022-04-28 22:24:20
2821
原创 Linux 安装flash
使用命令行:sudo apt install flashplugin-installersudo apt install browser-plugin-freshplayer-pepperflash
2022-03-09 17:13:12
2649
 2
2
原创 Python实验数据集:垃圾邮件数据集(http://archive.ics.uci.edu/ml/datasets/Spambase)。请从spambase.csv读入数据。 数据集基本信息如下:样
实验数据集:垃圾邮件数据集(http://archive.ics.uci.edu/ml/datasets/Spambase)。请从spambase.csv读入数据。数据集基本信息如下:样本数: 4601,特征数量: 57, 类别:1为垃圾邮件,0为非垃圾邮件。将样本集划分为70%的训练集,30%作为测试集。分别完成以下内容。决策树(1)分别取节点分裂标准为“gini”或“entropy”,分别建立决策树模型,计算训练误差和测试误差;画出对应的决策树。(2)设置树高,由3到30,分别建模,计算训
2021-12-12 20:56:06
20711
18
原创 Python 数据集:乳腺癌数据集(from sklearn.datasets import load_breast_cancer)。
数据集:乳腺癌数据集(from sklearn.datasets import load_breast_cancer)。(1)将样本集划分为70%的训练集,30%作为测试集,分别用逻辑回归算法和KNN算法(需要先对数据进行标准化)建模(不指定参数),输出其测试结果的混淆矩阵,计算其准确率、查全率和假正率。(2)利用搜索网格,分别确定逻辑回归及KNN模型的最优参数。KNN算法的主要参数提示:①n_neighbors(最近邻个数)取值一般为奇数。②algorithm(用于计算最近邻的算法)取值有‘
2021-12-04 20:58:24
28401
1
原创 Python 垃圾邮件的逻辑回归分类
加载垃圾邮件数据集spambase.csv(数据集基本信息:样本数: 4601,特征数量: 57, 类别:1 为垃圾邮件,0 为非垃圾邮件),阅读并理解数据。按以下要求处理数据集(1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。(2)将数据集拆分成训练集和测试集(70%和 30%)。建立逻辑回归模型分别用 LogisticRegression 建模。结果比对(1)输出测试集前 5 个样本的预测结果。(2)计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
2021-11-27 13:08:58
3340
原创 Python线性回归:加载共享自行车租赁数据集 BikeSharing.csv。 1. 按以下要求处理数据集 (1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。
加载共享自行车租赁数据集 BikeSharing.csv。按以下要求处理数据集(1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。(2)将数据集拆分成训练集和测试集(70%和 30%)。(3)对数据进行标准化处理建立回归模型分别用 LinearRegression 和 SGDRegression 两种方法建模。结果比对(1)分别对比两种模型在测试集上的预测性能(计算 score)。(2)分别测试学习率(参数 eta0)取 0.005, 0.01, 0.015, 0.02,
2021-11-18 23:32:35
3088
3
原创 Python数据预处理:使用 PCA 进行降维 读入 heart.csv 文件,用 PCA 方法进行降维,要求输出特征向量、维度压缩的数量(依 据是什么)以及降维后的结果。
使用 PCA 进行降维读入 heart.csv 文件,用 PCA 方法进行降维,要求输出特征向量、维度压缩的数量(依据是什么)以及降维后的结果。附上源代码:import pandas as pdimport numpy as npfrom sklearn.decomposition import PCAdata = pd.read_csv(r'heart.csv',header=None,delimiter=' ')pca = PCA()pca.fit(data)print('特征.
2021-11-07 14:53:44
3370
3
原创 Python数据预处理:2.处理缺失值 下载 UCI 数据集中的“匹兹堡的桥” (https://archive.ics.uci.edu/ml/datasets/Pittsburgh+Bridges,
2.处理缺失值下载 UCI 数据集中的“匹兹堡的桥”(https://archive.ics.uci.edu/ml/datasets/Pittsburgh+Bridges, 选择其中的bridges.data.version1 部分)。对该数据集中出现的缺失值(用?表示),选择一个数值列,用平均值填充;选择一个离散列(离散型取值),用众数填充。说明:(1)建议放入数据集的特征名。(2)建议将缺失值用 np.nan 代替。(3)建议使用 sklearn.impute.SimpleImputer
2021-11-07 14:45:41
1978
1
原创 Python数据预处理:1.异常值检测 加载 sklearn 自带红酒数据集(wine)。检测其中的异常值(判断标准:与平均值的偏差 超过 3 倍标准差的数值)。提示:用数据生成 pandas 的 D
1.异常值检测加载 sklearn 自带红酒数据集(wine)。检测其中的异常值(判断标准:与平均值的偏差超过 3 倍标准差的数值)。提示:用数据生成 pandas 的 DataFrame 对象(建议放入数据集本身的特征名),以便用 pandas 的相关函数来实现。附上源代码:from sklearn.datasets import load_wineimport pandas as pdlw = load_wine()data = pd.DataFrame(lw.data,index=l
2021-11-07 14:35:07
4373
原创 Maven项目管理:尝试使用依赖的传递性出现The pom for XXX is missing,no dependency information available
尝试使用本地自己编写的资源,使用依赖的传递性:出现无法找到资源:原因可能是由于maven无法从本地仓库找到自己编写的资源,虽然看起来idea并没有报错;但是编译运行是由maven环境下来执行的,所以应该先上传自己编写的资源到本地仓库mvn install编写资源的路径下;我已经将java01的资源打包上传到本地仓库,再在java03项目中使用依赖的传递性来测试junit是否成功传递依赖,下图为成功执行...
2021-10-24 22:00:12
723
原创 Python 【问题描述】根据一组学生成绩,找出5个最高的总分。
【问题描述】根据csv文件中记录的各科成绩,统计大学英语成绩在80-90分之间的学生人数。【输入形式】csv文件【输出形式】txt文件【样例输入】【样例输出】直接使用二维数组的转置和.sum()函数对列的统计,再使用sorted函数对数组元素排序和切片再套娃写入文件,注意write是不允许写入列表等非字符串的数据类型吧,我并没有使用pandas的写入函数,只用了读取,用pandas 的写入应该也是可以的import pandas as pdif __name__ == '__
2021-10-22 10:17:15
1526
原创 Python 【问题描述】根据csv文件中记录的各科成绩,统计大学英语成绩在80-90分之间的学生人数。
【问题描述】根据csv文件中记录的各科成绩,统计大学英语成绩在80-90分之间的学生人数。【输入形式】csv文件【输出形式】txt文件【样例输入】【样例说明】【评分标准】题意主要是判断英语成绩是否在range(80,90)这个范围,对Dataframe二维数组切片判断统计即可import pandas as pdif __name__ == '__main__': open('summary.txt','w').write(str(len([x for x in pd.r
2021-10-22 10:02:54
2922
原创 Python 【问题描述】将形如n*m的矩阵,扩展为2n*2m的形式
【问题描述】将形如nm的矩阵,扩展为2n2m的形式,如下图所示。【输入形式】元素均为整型的矩阵,保存在文本文件中。【输出形式】扩展后的矩阵,保存在文本文件中。【样例输入】1,2,34,5,6【样例输出】1,2,3,1,2,34,5,6,4,5,61,2,3,1,2,34,5,6,4,5,6【样例说明】23的矩阵,扩展成46的矩阵。依据题意,意思是要将读取的矩阵沿X、Y轴复制(扩展)两次应当使用np.tile()函数,可以以整个数组的形式复制,注意:重塑可能比较繁琐,np的repe
2021-10-21 22:02:02
615
原创 Python 【问题描述】按照世卫组织的标准: 男性:(身高cm-80)×70%=标准体重 女性:(身高cm-70)×60%=标准体重 标准体重正负10%为正常体重(含10%) 标准体重正负1
【问题描述】按照世卫组织的标准:男性:(身高cm-80)×70%=标准体重女性:(身高cm-70)×60%=标准体重标准体重正负10%为正常体重(含10%)标准体重正负10%~20%为体重过重或过轻(含20%)标准体重正负20%以上为肥胖或体重不足 请分别计算输出男性和女性正常体重、体重过重、体重过轻、肥胖和体重不足的人数。【输入形式】csv文件格式,文件名为whdata.csv。【输出形式】标准输出。输出代码测试中我感觉出现了些小问题,因为测试结果与本编程下的测试结果出现相反
2021-10-16 11:11:16
1909
原创 对One列求最大值、最小值和平均值,结果分别保存保存到变量x,y, z。
对One列求最大值、最小值和平均值,结果分别保存保存到变量x,y, z。import pandas as pdarr1 = range(10)obj1 = pd.Series(arr1,index = ['one','two','three','four','five','six','seven','eight','nine','ten'])num = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]obj2 = pd.DataFrame(num,index=list
2021-10-15 13:38:25
148
原创 Python 【问题描述】从arrfile.txt文件读入矩阵元素,矩阵行列为n*2n形式(n>=2), 将其拆分成两个n*n的子矩阵,计算两个子矩阵的乘积,结果写入result.txt文件。
【问题描述】从arrfile.txt文件读入矩阵元素,矩阵行列为n2n形式(n>=2), 将其拆分成两个nn的子矩阵,计算两个子矩阵的乘积,结果写入result.txt文件。【输入形式】逗号分隔的文本文件arrfile.txt【输出形式】逗号分隔的文本文件result.txt我们需要用到矩阵拆分函数:np.hsplit(X,N),N为拆分对等的子矩阵的数量,使用savetxt和loadtxt读写,且使用分割符即可实现如上图import numpy as npif __name__
2021-10-15 13:33:33
221
原创 Python:【问题描述】自定义队列类,队列元素要么全为整型,要么全为字符串,也可以是空队列。并实现入队、出队操作(入队元素必须与队列中已有元素类型相同,如为空队列,则无此要求)。
【问题描述】自定义队列类,队列元素要么全为整型,要么全为字符串,也可以是空队列。并实现入队、出队操作(入队元素必须与队列中已有元素类型相同,如为空队列,则无此要求)。【输入形式】见程序。【输出形式】入队或出队的结果。【样例说明1】创建队列时,若元素不符合要求,给出以下提示信息。【样例输出1】All elements must be integer or string.【样例说明2】若入队列操作成功,则给出以下提示信息,并输出队列内容。【样例输出2】Success to joined a new
2021-10-09 21:32:16
440
原创 Python:【问题描述】读出带逗号分隔的数据文件,将数据间的逗号去掉,返回列表,其中每个元素是文件中的一行数据。
问题描述】读出带逗号分隔的数据文件,将数据间的逗号去掉,返回列表,其中每个元素是文件中的一行数据。要求计算每一列的最大值,最小值和平均值,写入结果文件中。【输入形式】文本文件。【输出形式】文本文件。【样例输入】if __name__ == '__main__': with open('data.txt','r+',encoding='utf-8') as f,open('result.txt','w+',encoding='utf-8') as r: [r.write(
2021-10-09 18:43:24
1800
1
原创 【问题描述】定义函数test(lst)来测试列表各元素的各位数上是否含有数字2。返回一个列表,该列表只包含lst中带有数字2的正整数。
【问题描述】定义函数test(lst)来测试列表各元素的各位数上是否含有数字2。返回一个列表,该列表只包含lst中带有数字2的正整数。【输入形式】一组正整数,以空格隔开。【输出形式】带有2的正整数列表【样例输入】38 90 290 32 102 15 221【样例输出】[290,32, 102, 221]【样例输入】38 90 31 19 56【样例输出】None【样例说明】如果没有带2的正整数,则输出Nonedef f(p=[]): print('None' if len([x f
2021-09-30 15:12:29
233
原创 【问题描述】编写函数trans:接受一个字符串列表,将列表元素长度大于2且含全为字母的字符串转换成大写字母并输出,。如无符合条件的字符串,输出“No Result”
【问题描述】编写函数trans:接受一个字符串列表,将列表元素长度大于2且含全为字母的字符串转换成大写字母并输出,。如无符合条件的字符串,输出“No Result”【输入形式】若干组字符串, 用空格隔开。【输出形式】大写字母形式、且长度大于2且全为字母的字符串,空格隔开。【样例输入】uue oae aa iu str 98yg llx9【样例输出】UUE OAE STR【样例输入】99idj 90 aa iu 23 88gty【样例输出】No Result`def f(p=[]):
2021-09-30 14:51:30
477
原创 【问题描述】编写函数qmark:接受一个列表,检测列表元素是否包含’?’。如有’?’,则将问号替换为该列表其它数的平均数(保留四舍五入的整数部分)并输出新列表内容。如没有’?’,则输出“No Ques
【问题描述】编写函数qmark:接受一个列表,检测列表元素是否包含’?’。如有’?’,则将问号替换为该列表其它数的平均数(保留四舍五入的整数部分)并输出新列表内容。如没有’?’,则输出“No Question Mark!”。【输入形式】一组整数,可能带有’?’, 用空格隔开。【输出形式】据题意。【样例输入】23 54 67 12 ? 31 45 55 ?【样例输出】[23, 54, 67, 12, 41, 31, 45, 55, 41]【样例输入】[23, 54, 67, 12, 2
2021-09-30 14:51:11
137
原创 【问题描述】根据用户输入的一系列整数(个数不确定),判断它们是否为奇数(判断用函数来实现)。
【问题描述】根据用户输入的一系列整数(个数不确定),判断它们是否为奇数(判断用函数来实现)。【输入形式】若干整数,空格隔开【输出形式】每个数对应的布尔值【样例输入】20 11 9 16【样例输出】False True True False【样例说明】【评分标准】def f(p=[]): [print('True',end=' ') if int(x)%2!=0 else print('False',end=' ') for x in p] input_data =
2021-09-30 14:29:49
180
原创 Python:模拟评委打分过程:输入一组分数(0-100之间,至少3个分数), 分别去掉一个最高分和一个最低分,然后计算输出平均分,保留两位小数。若出现不满足[0,100]的分值,则不计算平均分,输出
【问题描述】输入一组分数(0-100之间,至少3个分数), 分别去掉一个最高分和一个最低分,然后计算输出平均分,保留两位小数。若出现不满足[0,100]的分值,则不计算平均分,输出“error”字样。【输入形式】若干个0-100之间的分数。【输出形式】带两位小数的平均值。【样例输入】89 90 80 81【样例输出】85.00【样例输入】-9 90 80 81【样例输出】error【样例说明】输入的分数用空格隔开,如有两个相同的最高分或最低分,只去掉一个即可。使用列表推导式再用string模
2021-09-24 10:53:40
5974
2
原创 Python:输出数字,用户在键盘输入任意字符串,程序将其中的数字输出。
输出数字【问题描述】用户在键盘输入任意字符串,程序将其中的数字输出。【输入形式】任意键盘符号串【输出形式】数字【样例输入】d,lb904igj5n/=2【样例输出】90452【样例说明】【评分标准】用正则表达式和join函数:import re print(''.join(re.findall(r'[0-9]',input())))...
2021-09-24 10:47:30
4150
原创 Python:用户在键盘输入任意字符串,将其中的字母转为大写输出。
【问题描述】用户在键盘输入任意字符串,将其中的字母转为大写输出。【输入形式】【输出形式】【样例输入】d,lbhh904igj5n/=2【样例输出】DLBHHIGJN【样例说明】【评分标准】利用upper()函数和正则表达式import re print(''.join(x.upper() for x in re.findall(r'[a-z]',input())))...
2021-09-24 10:45:52
4058
原创 Python:用户在键盘输入任意字符串,统计不重复的字符个数。
【问题描述】用户在键盘输入任意字符串,统计不重复的字符个数。【输入形式】键盘字符【输出形式】数字【样例输入】aaaekkkhaadddeeed【样例输出】5【样例说明】输入任意个字符【评分标准】统计结果正确得满分。利用集合的元素唯一的性质,再求集合的长度print(len(set(input()))) ...
2021-09-24 10:44:03
2870
原创 用户从键盘输入整数,程序输出n行*号,呈金字塔形式排列,各行星号数量分别是1,3,5,7,....
【问题描述】用户从键盘输入整数,程序输出n行*号,呈金字塔形式排列,各行星号数量分别是1,3,5,7,…【输入形式】整数【输出形式】n行*号【样例输入】2【样例输出】 * ***【样例说明】【评分标准】利用列表推导式求解l = int(input()) [print('{0:^{1}}'.format('*'*(x),2*l-1)) if x%2!=0 else print() for x in range(2*l) if x!=0]...
2021-09-24 10:42:02
1369
原创 1. 字符串检测:检测用户输入的字符串是否符合以下条件: (a)长度大于6; (b)包含大写字母; (c)包含小写字母 (d)包含数字; (e)包含标点符号( : , . ? ; ‘ “ !
字符串检测【问题描述】检测用户输入的字符串是否符合以下条件:(a)长度大于6;(b)包含大写字母;(c)包含小写字母(d)包含数字;(e)包含标点符号( : , . ? ; ’ " ! )。若全部满足条件请输出“correct”,否则输出“wrong”。【输入形式】字符串【输出形式】correct / wrong【样例输入】abc895【样例输出】wrong【样例说明】任意字符串。【评分标准】使用正则表达式可解:import res=input()print('corr.
2021-09-24 10:38:08
783
原创 Python: 输入任意大的自然数,输出各位数字的降序排列结果
初学Python,初识其趣!一般的解决方法:x=input()i = 0y = int(x)x = str(y)x = sorted(x,key=str,reverse=True)while i < len(x): print(x[i],end='') i+=1极简主义:print(''.join(sorted(input()[::1].lstrip('0'),reverse=True)))输出结果:...
2021-09-17 09:59:42
4469
原创 关于Onclick传递参数,接收时缺失
js中引用函数,出现传递参数被截断,如一个字符串(有命名空间的)值=“2021/01/01"接收过来的值为”2021“ ,则是因为里面的斜杠问题,应该用单引号把字符串名字引用起来,这样就完好无损传参过去了,如下例:...
2021-08-03 00:41:21
476
原创 2020-10-18
Exception in thread "main" java.util.NoSuchElementExceptionException in thread "main" java.lang.ArrayIndexOutOfBoundsException: 3 at Java_as.Scanner_a.Scanner_information(Test_wrong.java:56) at Java_as.Test_wrong.main(Test_wrong.java:70)//这是在用其他...
2020-10-18 11:39:05
196
1
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人