







加载垃圾邮件数据集spambase.csv(数据集基本信息:样本数: 4601,特征数量: 57, 类别:
1 为垃圾邮件,0 为非垃圾邮件),阅读并理解数据。
- 按以下要求处理数据集
(1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。
(2)将数据集拆分成训练集和测试集(70%和 30%)。 - 建立逻辑回归模型
分别用 LogisticRegression 建模。 - 结果比对
(1)输出测试集前 5 个样本的预测结果。
(2)计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
(3)从测试集中找出模型不能正确预测的样本。
(4)对参数 penalty 分别取‘l1’, ‘l2’, ‘elasticnet’, ‘none’,对比它们在测试集上的预测性
能(计算 score)。
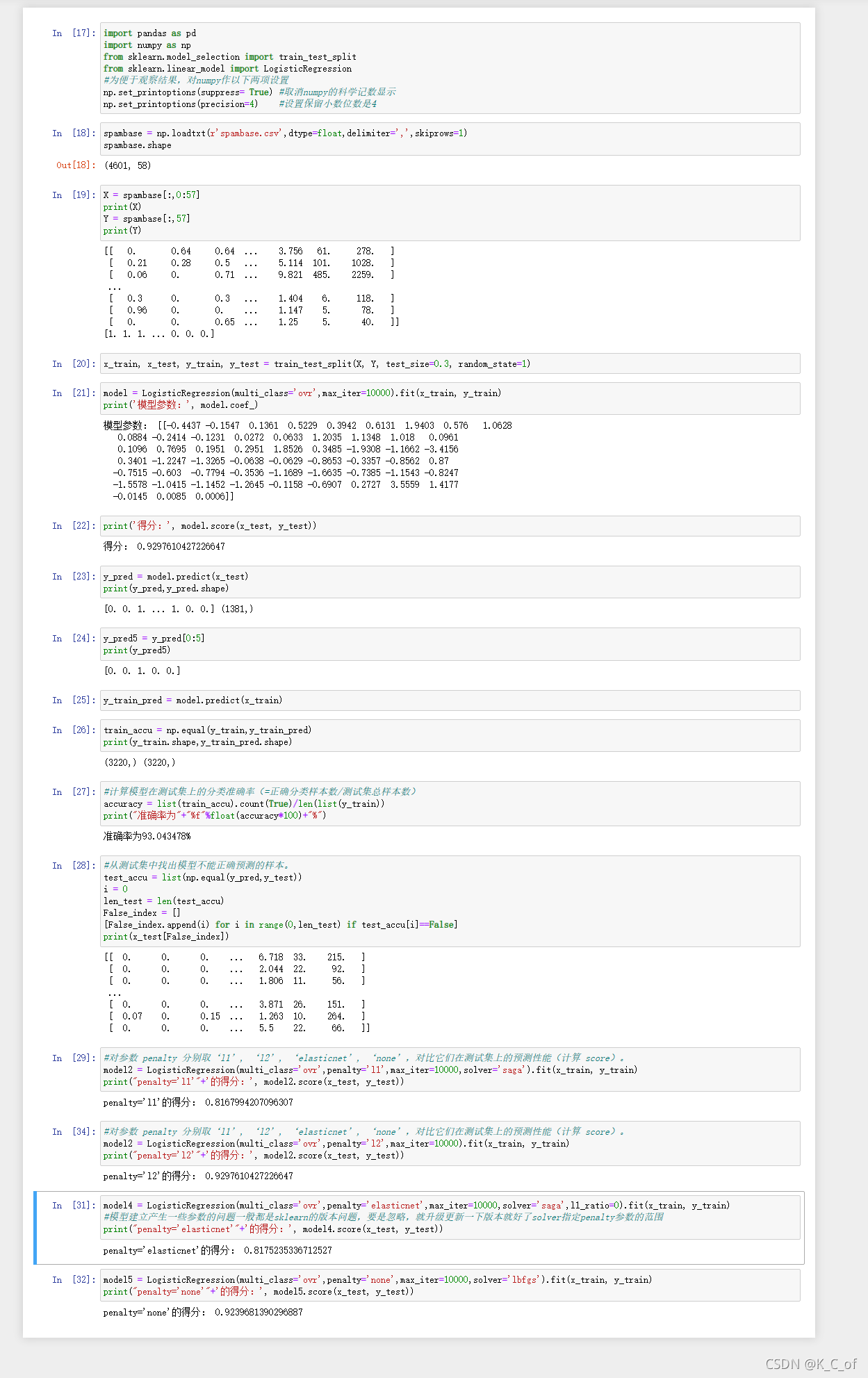
拆分特征值和目标数据前面已经可知,预测和模型得分结果也是直接使用模型的方法,下面主要是要测试准确率和找出不能正确预测的样本,以及不同的惩罚下的模型得分,主要运用到Numpy模块和列表list的函数,代码如下:
y_train_pred = model.predict(x_train)
# In[26]:
train_accu = np.equal(y_train,y_train_pred)
print(y_train.shape,y_train_pred.shape)
# In[27]:
#计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
accuracy = list(train_accu).count(True)/len(list(y_train))
print("准确率为"+"%f"%float(accuracy*100)+"%")
# In[28]:
#从测试集中找出模型不能正确预测的样本。
test_accu = list(np.equal(y_pred,y_test))
i = 0
len_test = len(test_accu)
False_index = []
[False_index.append(i) for i in range(0,len_test) if test_accu[i]==False]
print(x_test[False_index])
# In[29]:
#对参数 penalty 分别取‘l1’, ‘l2’, ‘elasticnet’, ‘none’,对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l1',max_iter=10000,solver='saga').fit(x_train, y_train)
print("penalty='l1'"+'的得分:', model2.score(x_test, y_test))
# In[33]:
#对参数 penalty 分别取‘l1’, ‘l2’, ‘elasticnet’, ‘none’,对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l2',max_iter=10000).fit(x_train, y_train)
print("penalty='l2'"+'的得分:', model2.score(x_test, y_test))
# In[31]:
model4 = LogisticRegression(multi_class='ovr',penalty='elasticnet',max_iter=10000,solver='saga',l1_ratio=0).fit(x_train, y_train)
#模型建立产生一些参数的问题一般都是sklearn的版本问题,要是忽略,就升级更新一下版本就好了solver指定penalty参数的范围
print("penalty='elasticnet'"+'的得分:', model4.score(x_test, y_test))
# In[32]:
model5 = LogisticRegression(multi_class='ovr',penalty='none',max_iter=10000,solver='lbfgs').fit(x_train, y_train)
print("penalty='none'"+'的得分:', model5.score(x_test, y_test))















 3967
3967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









