






在机器学习领域,有一条人尽皆知的”潜规则“:Garbage in, garbage out。他就是在说特征的工程的重要性,其决定了模型的上限,而我们训练模型就是不断地逼近这个天花板而已。
影响特征工程质量的因素有很多种,如数据质量本身参差不齐、特征字段区分度不高,还有选择不到位、不合理等因素。
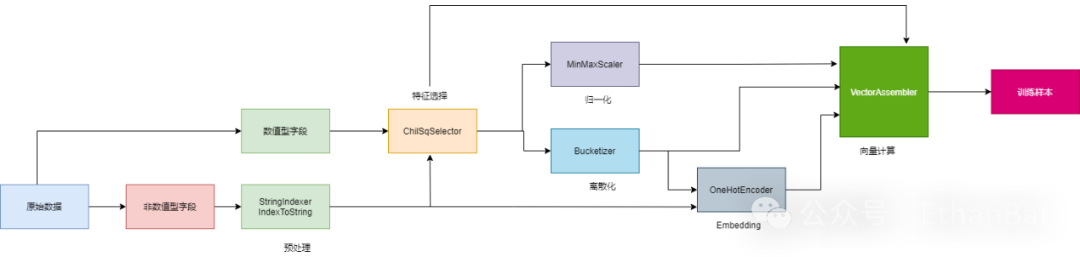
特征工程处理步骤
对于原始数据中的字段,由于字段类型不同,处理方式也不同,可以分为数值类型(Numeric)和非数值型(Categorical)。
1. 预处理
由于大多数的数据模型都是不能直接”消费“的非数值型数据,因此需要把非数值类型的转为数值类型。处理方法有:
StringIndexer:将标签字符串编码为标签索引列,可以对多列进行编码,索引再[0, numLabels]。

Imputer:主要是用来补全列缺失的值,一般是使用缺失值所在列的平均值、中位数等来填充。
IndexToString:IndexToString将标签索引列映射回包含原始标签字符串的列。一个常见的用例是使用StringIndexer从标签生成索引,使用这些索引训练模型,并使用IndexToString从预测索引列中检索原始标签。

2. 特征选择
筛选参与模型训练的特征值,这主要依赖业务经验来选择。与此同时,也会使用一些统计方法,去计算候选特征与预测标的的关联型,从而以量化的方式,去衡量不同的特征值权重。主要方法有:
ChiSqSelector:这是卡方检验与卡方分布的统计方法。
UnivariateFeatureSelector:单变量特征选择,是一种特征选择方法,用于选择数据集中与目标变量(label)关系最强的特征。该方法通过单独评估每个特征与目标变量之间的关系,选择出与目标变量关系最强的前k个特征。
VarianceThresholdSelector:主要用于移除低方差特征。具体来说,如果一个特征的样本方差不大于设定的阈值(varianceThreshold),那么这个特征就会被移除。
3. 归一化
是把一组数值,统一映射到同一个值域,而这个值域通常是[0,1]。那么为什么需要归一化?由于原始数据之间的量纲差异性较大时,在模型训练过程中,梯度下降不稳定,抖动比较大,模型不容易收敛,从而导致训练效率较差。主要方法有:
MinMaxScaler: 是一种特征缩放方法,用于将数据特征缩放到给定的最小值和最大值之间(通常是 0 到 1)。这种方法是通过线性变换将原始数据按比例缩放,使得数据范围落在 [0, 1] 或其他指定的最小值和最大值之间。
Normalizer:主要用于将数据缩放到相同的数据区间和范围,以减少规模、特征、分布差异等对模型的影响。
还有MaxAbsScaler、RobusScaler和StandardScaler等。
4. 离散化
与归一化一样,离散化也是用来处理数值型字段的,离散是把原本连续的数值打散,从而降低原始数据的多样性。主要是为了提升数据的区分度与内聚性,从而与预测标的产生更强的关联。主要方法有:
Bucketizer:用于将连续型数据转化为各自对应的分段区间内的离散类别特征。具体来说,Bucketizer能够根据用户指定的分段规则,将一列连续特征转换为一列特征存储桶,其中每个存储桶代表一个特定的数值范围。
Binarizer:是一种数据预处理方法,用于将连续型数据转化为二值数据。具体来说,Binarizer会根据设定的阈值,将大于阈值的数据二值化为1,小于等于阈值的数据二值化为0。
QuantileDiscretizer:可以将一列连续特征值转换为具有离散级别的特征值,使得原本连续的数值数据被划分到不同的箱子(bucket)中,每个箱子代表一个数值范围。
5. Embedding
Embedding是一个非常大的话题,有人曾说”万物皆可Embedding“。Embedding是将数据集合映射到向量空间的过程。主要方法有:
OneHotEncoder:是一种数据预处理方法,主要用于将离散型变量转换为连续型变量,以便于机器学习模型的应用。
PCA(Principal Component Analysis):即主成分分析,PCA的主要思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征也被称为“主成分”,是在原有n维特征的基础上重新构造出来的k维特征。
此外还有MinHash、FeatureHasher等。
6. 向量计算
主要是构建训练样本中的特征向量(Feature Vectors),主要方法有:
VectorAssembler:是一个数据转换器,它将多个列组合成一个向量列,以供机器学习算法使用。
此外还有VectorIndexer、VectorSlicer和ElementwiseProduct等。
以上就是机器学习特征工程的六大步骤,每一步的里面的方法有很多种,需要更具具体使用的机器学习库去选择合适的特征处理函数。
公众号@EthanBai















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









