






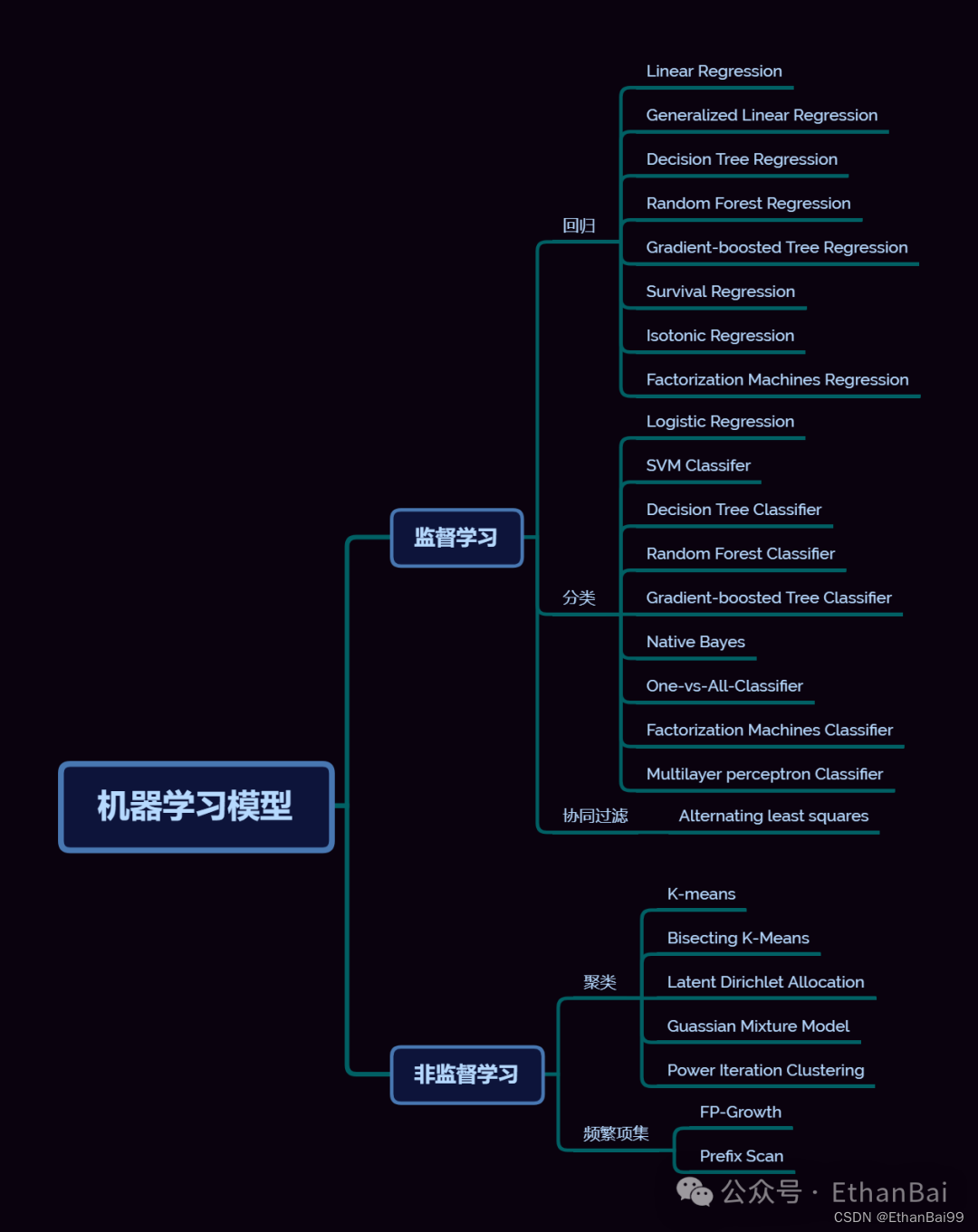
与监督学习相比,非监督学习,泛指那些数据样本中没有Label的机器学习问题。主要的模型如下图:
1 K-Mean
结合数据样本的特征向量,根据向量之间的相对距离,K-means算法可以把所有的样本划分为K个类别,这也是算法命名中“K”的由来。最终结果随着K值的不同结果不同划分出来的结果也不同。
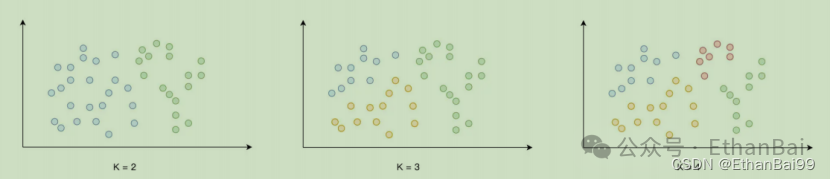
K-means的设计思想是“物以类聚”,那么可以得出,同一个类别中的向量应该足够的接近,而不同的类别向量之间的距离应该越远越好。因此,对于k-means的模型效果可以使用距离类的指标来度量,如欧式距离。
K-means的结果没有真实意义,但是它以量化的形式,刻画了房屋之间的相似性与差异性,这个新生成的特性往往与预测标的有着更强的关联性,所以使用这个新特征参与监督学习,就有可能优化和提升模型的效果。
2 协同过滤
从字面上可以看出其目标就是过滤出符合条件的子集,协同是方式,是指利用群体行为(全部用户与全部物品的交互历史)来实现过滤,而过滤是目的。核心思想是“相似的人倾向于喜好相似的物品集”。所以此模型一般是用来做推荐的。
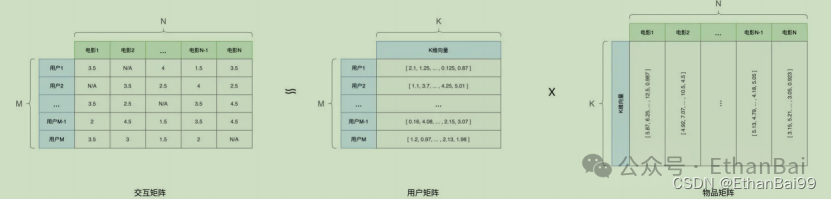
那这种相似度是如何量化的?是通过矩阵分解。给的维度是(M,N)的交互矩阵C,可以分解为U与I,U称为用户矩阵,其维度是(M,K);而I可以看作是物品矩阵,维度为(K,N)。其中K是超参数,它是由开发人员设定的。U中的每一行可以看作是用户的embedding,刻画了用户的特征,物品中的每一列刻画了物品的特征。当他们处于同一向量空间,我们就可以使用欧式距离或者余弦夹角等方法,来计算他们向量之间的相似度。基于相似度就可以进行推荐。
3 频繁项集
频繁项集是一种经典的数据挖掘算法,我们可以把它归类到非监督学习的范畴。频繁项集可以挖掘数据集中那些经常“成群结队”出现的数据项,并尝试在他们之间建立关联规则(Association Rules),从而为决策提供支持。
比方说,电影(“八佰”、“金刚川”、“长津湖”)是频繁项,而(“八佰”、“金刚川”->“长津湖”)之间存在着关联关系。那么,对于看过“八佰”和“金刚川”的人,我们更倾向于判断他 / 她大概率也会喜欢“长津湖”,进而把这部电影推荐给他 / 她。















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









