









在机器学习领域,如果按照“样本是否存在预测标的(Label)”为标准,机器学习问题可以分为(Superviced Learning)与非监督学习(Unsupervised Learning)。如果在按照使用场景不同,监督学习又被分为回归(Regression)、分类(Classification)和协同过滤(Collaborative Filter);非监督学习又可分为聚类(Clustering)与频繁项集(Frequency Patterns)。
模型算法种类复杂且多样,我们不可能全部学一遍,且不说有多复杂,光是工作量就足以让人望而生畏,所以我们只需要学些基础的模型算法,等到实际使用的时候再根据场景选择,之后再做深入研究。
今天主要看下分类与回归相关的模型算法。
1、决策树
见名知意,决策树肯定是一个树,树的化常见的二叉树大家都熟悉。决策树是一种根据样本特征向量而构建的树形结构,由节点和有向边构成,其中节点又分为两类,一类是内部节点,一类是叶子节点。内部节点表示的是样本特征,而叶子节点代表分类。
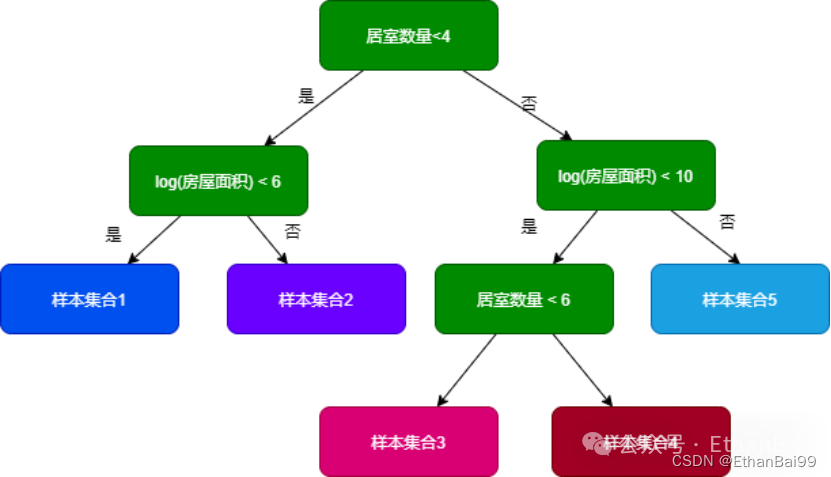
这个决策树的过程和人的思维过程非常的相似,相当于将原来的数据样本进行拆分,拆分成了1到5,集合1到5就构成了原来的样本。人的决策取决于自己的认知,那么模型是如何决策的?依靠的是数据样本的纯度,可以理解为标签的多样性,如果样本标签都一样,那么标签的多样性为1,那么纯度就很高。
接下来需要遍历每个特征,考察每个特征的提纯能力,所谓提纯就是:把原始样本使用特征进行区分,如果区分后的子集纯度有所提高,那么区分后的子集也就纯度越高,该特征的提纯能力越高。然后模型选取纯度比较高的特征并按照纯度自上而下的逐级构建决策树。
当然我们也可以人为的干预,如设置纯度阈值和设置树的深度来进行限制。
2、Random Forest
又叫“随机森林”,该算法是决策的加强版,基本思想就是“三个臭皮匠,顶一个诸葛亮”。也就是使用多颗决策树共同决策,根据少数服从多数的原则进行决策。每颗决策树的特征是随机选取其中部分特征,这也是“随机“一词的来源。
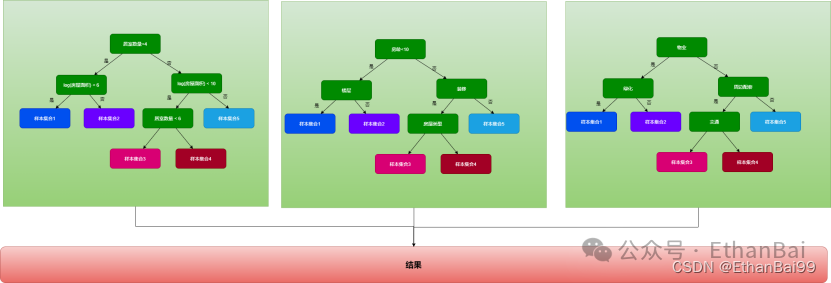
3、GBDT
GBDT(Gradient-boosted Decision Trees)。和随机森林类似,它也是用多棵树来拟合数据样本。但是,树与树之间是有依赖关系的,每一棵树的构建,都是基于前一颗树的训练结果。其基本思想是”站在前人的肩膀上看的更远“。

在训练过程中,每一棵树是基于前一颗树的”样本残差“。样本残差就是预测值与真实值之间的差值。也就说每次都在缩短与真实值之间的差距,理论上一直下去肯定可以和真实值一样。但是现实是很难实现的,GBDT的拟合能力很强,所以得防止过拟合,所以需要认为干预,如限制决策树的数量以及深度来防止过拟合。
决策树既可以应用在回归,也可以用在分类。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









