







一、transformer 架构
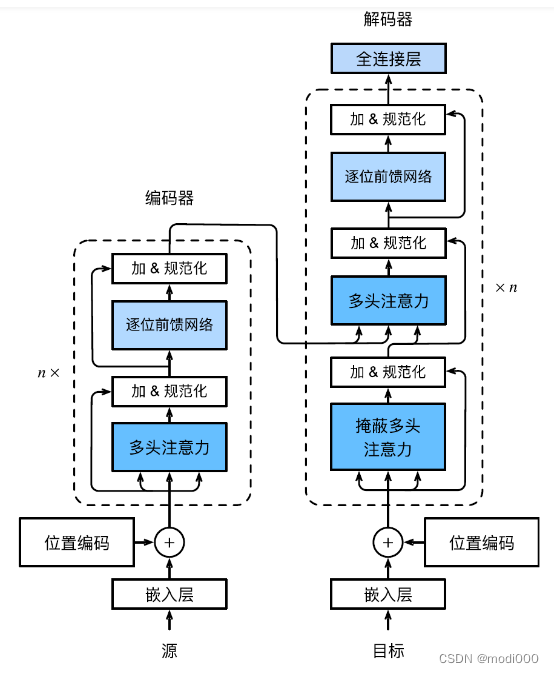
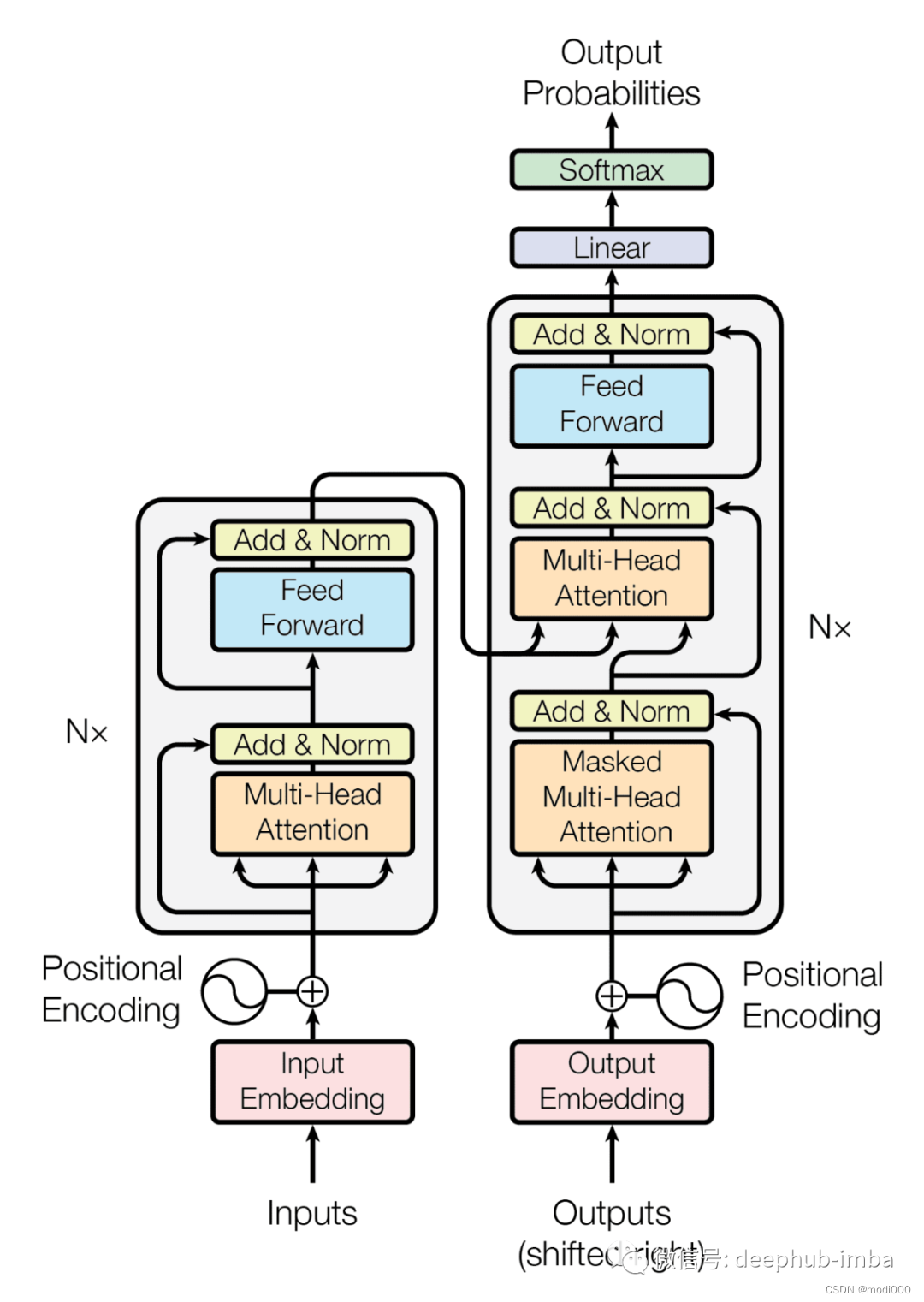
如上图所示,transformer(形状像变压器?或者翻译成变形金刚,由不同模块拼装而成)的架构左边是n个结构体相同的编码器(例如,原论文是6个编码器的串联),右边是n个结构相同的解码器原(原论文是6个解码器的串联)。

编码器有多头注意力机制模块和前馈网络两部分组成;解码器是由掩码的多头注意力、多头注意力、前馈网络三部分组成,编码器的输出作为解码器输入的一部分。
----------------------------------------
在Transformer模型中,编码器(Encoder)和解码器(Decoder)各自有独立的输入。通常,在有监督学习的场景下,编码器负责处理输入样本,而解码器处理与之对应的标签。这些标签在进入解码器之前同样需要经过适当的预处理。这样的设置允许模型在特定任务上进行有针对性的训练。
通过一个简单的机器翻译任务来说明这个概念。假设有以下的英语到法语的翻译对:
- 英语(输入样本): "Hello, world"
- 法语(标签): "Bonjour, monde"
在这个示例中,编码器(Encoder)会接收"Hello, world"这个句子作为输入。这个句子首先会被转换成一组词向量或者字符向量,然后进入编码器进行处理。
与此同时,解码器(Decoder)会接收与"Bonjour, monde"对应的标签作为输入。同样地,这些标签首先会被转换成一种机器可理解的表示(比如词向量或字符向量),然后进入解码器。
编码器处理完输入样本后,它的输出会与解码器的输入进行某种形式的结合,以生成最终的翻译输出。通过这个机制,模型可以在有监督的学习环境中进行训练,以完成特定的任务,如机器翻译。
如何理解Encoder(编码器部分)
Transformer中的编码器部分,作用是学习输入序列的表示,位置如下图所示:

-----
作者:木羽Cheney
链接:https://www.zhihu.com/question/445556653/answer/3197136641
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何理解Encoder(编码器部分)
在Transformer模型的编码器(红色虚线框)部分,数据处理流程如下:
首先,输入数据(比如一段文字)会被送入注意力(Attention)机制进行处理,这里会给数据里的每一个元素(比如每一个字或词)打个分数,以决定哪些更重要,在"注意力机制"(Attention)这个步骤之后,会有一些新的数据生成。
接着,一个“Add”操作会被执行,在注意力机制"中产生的新数据会和最开始输入的原始数据合在一起,这个合并其实就是简单的加法。"Add"表示残差连接,这一操作的主要目的是确保数据经过注意力处理后的效果至少不逊于直接输入的原始数据。
随后,数据会经过一个简单的数学处理,叫做“层归一化”(Norm),主要是为了让数据更稳定,便于后续处理。之后,数据将进入一个双层的前馈神经网络。这里的目标是将经过注意力处理的数据映射回其原始的维度,以便于后续处理。这是因为编码器会被多次堆叠,所以需要确保数据的维度在进入下一个编码器前是一致的。简单来说:就是把经过前面所有处理的数据变回原来的形状和大小。
注意看图中编码器左侧的Nx标识,意味着会有多个编码器堆叠。
最后,为了准备数据进入下一个编码器(如果有的话),数据会再次经过“Add”和“Norm”操作,输出一个经过精细计算和重构的词向量表示。
这样的设计确保了模型在多个编码器层之间能够有效地传递和处理信息,同时也为更复杂的计算和解码阶段做好了准备。简单来说,Transformer的编码器就是通过这些步骤来理解和处理输入的数据,然后输出一种新的,更容易理解的数据形式。如图:

1.3 如何理解Decoder(解码器部分)
Transformer中的解码器部分,作用是用于生成输出序列,位置如下图所示:

作者:木羽Cheney
链接:https://www.zhihu.com/question/445556653/answer/3197136641
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在Transformer模型的解码器(紫色虚线框)部分,数据处理流程如下:
在Decoder部分,数据首先进入一个带遮罩(masked)的注意力(Attention)机制,这个遮罩的作用是确保解码器只能关注到它之前已经生成的词,而不能看到未来的词。
然后,这一层输出的信息会与来自Encoder部分的输出进行融合。具体来说,这两部分的信息会再次经历一个注意力机制的处理,从而综合考虑编码与解码的内容。
这个过程之后,解码器的操作与编码器部分大致相同。数据会经过层归一化、前馈神经网络,再次进行层归一化,最终输出一个词向量表示。输出的词向量首先会通过一个线性层(Linear)。这一步的目的是将向量映射到预先定义的词典大小,从而准备进行词预测。
最后,使用softmax函数计算每个词的生成概率。最终,选取概率最高的词作为该时刻的输出。
现在假设有一个很小的词典,只有3个词:“apple”,“banana”,“ cherry”。线性层会将这个3维向量转换成另一个3维向量(对应“词典”大小)。
假设转换后的向量是[2.5, 1.0, -0.5]。
通过softmax函数,这个向量会转换为概率分布,比如[0.8, 0.18, 0.02]。
这就意味着模型认为下一个词是“apple”的概率是80%,是“banana”的概率是18%,是“cherry”的概率是2%。
这样,就能从解码器的高维输出中预测出一个实际的词语了。
这样,Decoder不仅考虑了之前解码生成的词,还综合了Encoder的上下文信息,从而更准确地预测下一个词。
------------
作者:木羽Cheney
链接:https://www.zhihu.com/question/445556653/answer/3197136641
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二、注意力机制
q是输入的信息,k,v成组出现,通常是源语言、原始文本等已有的信息,通过计算q与v之间的相关性,得出不同的k对输出的重要程度,再与对应的v相乘求和,就得到了q的输出。
注意力机制,就是权重,跟query的内容接近的Vlaue权重就高。
以下视频截图来源于:
注意力机制的本质|Self-Attention|Transformer|QKV矩阵_哔哩哔哩_bilibili
一维的情况:注意力机制涉及三个向量,q,k,v
例如:腰围(key)与体重(value)形成一个键值对的映射关系,我们要查询(query,请求)腰围是57kg对应的体重。
q(57)与k中56,58的相关性最大,故56和58的权重相比51就会更大,

二维的情况:

当qkv三个向量都相同,就是self-attention(自注意力)
只关注输入徐磊元素间的关系,将输入转换成qkv,然后进行计算你,捕捉文本的内在联系。

multi-head attention ( 多头注意力机制),在自注意力的基础上,使用多种变换生成的Q、K、v进行运算,再将相关性的结论综合起来,进一步增强self-attention的效果。
还可以参考这个视频。















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









