







一、本文创新点
1、作者注意到重叠核范数对于张量补全的效果比较好,提出了一种用于张量补全的重叠核范数正则化的非凸变体。
2、该正则化自然引起损失函数的非凸,故提出了一个更有效的优化的算法
3、提出的优化算法有三点优势:一:避免了代价昂贵的张量展开和合并;二:在迭代中保持“稀疏加低秩”结构;三:融入适应的动力。
二、相关工作
1、低秩矩阵学习
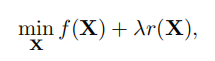
求解方法:第一步: 、
、
第二步:
对于求解方程(3),已经有理论保证,理论如下:

下面来看看具体的例子
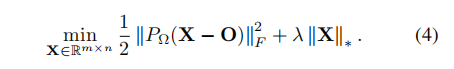
求解方法:第一步: (其实就是代入方程2中)
(其实就是代入方程2中)
第二步:依据上面的步骤,现在应该算的SVD了,但是直接运算代价有点大,所以这里利用了Power method去算
2、非凸的低秩正则化
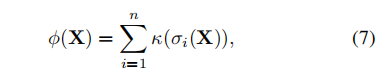
对于非凸正则化,有如下假设

常见的非凸正则化有:(1)![]()
![]()
![]() ,
,
(2)![]()
![]()
类似于Lemma 2.1,对于求解带有非凸问题,也有近端梯度步骤
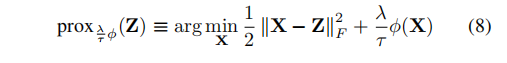
对于求解方程(8),也已有理论保证,理论如下:

三、非凸低秩张量填充(这里才是本文的重点哈,前面都是些铺垫啦啦啦)
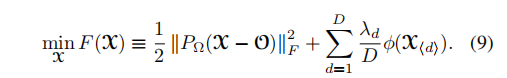
直接利用近端梯度算法来求解并不是很乐观,因为![]() 并不简单。所以这里先利用近端平均算法(PA算法)
并不简单。所以这里先利用近端平均算法(PA算法)
PA算法是解决函数中包含凸但非光滑的函数项,如下:
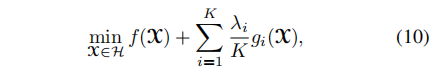
具体迭代步骤为:
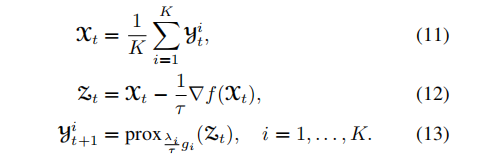
那么对于问题(9),具体的迭代步骤为:

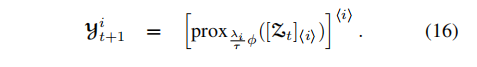
下面利用低秩加稀疏结构,可以避免对张量进行展开和合并操作
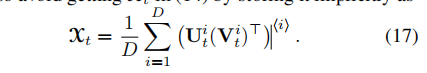
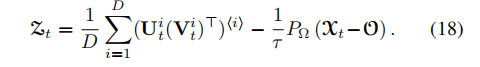

方程(19)和(20)涉及到的计算,下面的定理给出进一步的计算方法



四、结论
本文提出了一个非凸正则化的低秩张量补全模型。提出了一种高效的非凸近似平均算法,该算法在迭代过程中保持了“稀疏加低秩”的结构,并引入了自适应动量。收敛到临界点是有保证的。实验结果表明,该算法比已有的方法更有效、更准确。作为未来的工作,利用自动机器学习(AutoML) (Yao et al., 2018b)自适应调整超参数的建议的方法将是有趣的。















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









