







chinese-ocr自然场景下不定长文字识别(ctpn + densenet)
注:本文中多处使用各位前辈的经验,项目代码不方便提供,可参考:
https://github.com/YCG09/chinese_ocr
实现功能
文字方向检测 0、90、180、270度检测
文字检测 后期将切换到keras版本文本检测 实现keras端到端的文本检测及识别
不定长OCR识别
环境部署
GPU环境
sh setup.sh
CPU环境
sh setup-cpu.sh
CPU python3环境
sh setup-python3.sh
cd ./ctpn/lib/utils
./make-for-cpu.sh
运行demo
将测试图片放入test_images目录,检测结果会保存到test_result中
Python3 demo.py
模型训练
一共分为3个网络
- 文本方向检测网络-Classify(vgg16)
- 文本区域检测网络-CTPN(CNN+RNN)
- DenseNet + CTC
文字方向检测-vgg分类
基于图像分类,在VGG16模型的基础上,训练0、90、180、270度检测的分类模型.
详细代码参考angle/predict.py文件,训练图片8000张,准确率88.23%
模型地址:https://pan.baidu.com/s/1zquQNdO0MUsLMsuwxbgPYg
##文字区域检测CTPN
关于ctpn网络,网上有很多对其进行介绍讲解的,算法是2016年提出的,在印书体识别用的很多,这里有前辈一篇相应的博文http://xiaofengshi.com/2019/01/23/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0-TextDetection/,在文章中结合本repo的代码对ctpn的原理进行了详细的讲解。
CTPN训练
1. 准备数据
首先,下载预先训练的VGG网络模型并将其放在data/pretrain/VGG_imagenet.npy.
其次,准备论文提到的训练数据。或者我们可以放置自己的数据
根据我们的数据集修改prepare_training_data/split_label.py中的path和gt_path路径。并执行下面操作。
cd lib/prepare_training_data
python3 split_label.py
它将在当前文件夹中生成准备好的数据,然后运行下面代码:
Python3 ToVoc.py
将准备好的训练数据转换为voc格式。它将生成一个名为TEXTVOC的文件夹。将此文件夹移动到数据/然后运行
cd …/…/data
ln -s TEXTVOC VOCdevkit2007
2.数据集下载
作者给的数据是预处理过的数据,
我们下载了数据,VOCdevkit2007 只有1.06G,但是此数据可以训练自己的模式,要是想训练自己的数据,那么需要自己标注数据,找自己的数据。
作者使用的icdar17的multi lingual scene text dataset, 没有用voc,只是用了他的数据格式,下面给出的数据是作者实现的源数据地址。
gt_path的数据地址:http://rrc.cvc.uab.es/?com=contestant

进入2017MLT 查看如下:

然后我们可以发送邮件,注册用户,并激活,进入下载页面:


3. 存放数据
作者训练使用的是7200张图片。使用train或者trainval是一样的,因为用的都是这7200张图片。可以检查一下VOCdevkit2007/VOC2007/ImageSets/Main下面的train.txt和trainval.txt是否正确,是否是7200张图片。你在用自己数据训练的时候也要特别注意一点,数据的标注格式是不是和mlt这个数据集一致,因为split_label这个函数是针对mlt的标注格式来写的,所以如果你原始数据标注格式如果和它不同,转换之后可能会是错的,那么得到的用来训练的数据集可能也不对。

对原始gt文件进一步处理的分析(也就是对txt标注数据进行进一步处理),生成对应的xml文件部分内容截图如下:

4.数据集标注
在标注数据的时候采用的是顺时针方向,一次是左上角坐标点,右上角坐标点,右下角坐标点,左下角坐标点(即x1,y1,x2,y2,x3,y3,x4,y4),,这里的标注方式与通用目标检测的目标检测方式一样,这里我标注的数据是生成到txt中,具体格式如下:
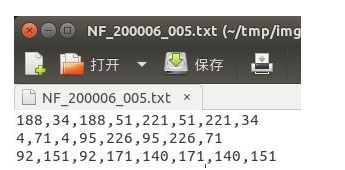
x1,y1,x2,y2,x3,y3,x4,y4 分别是一个框的四个角点的x,y坐标。这是因为作者用的mlt训练的,他的数据就是这么标注的,如果你要用一些水平文本的数据集,标注是x,y,w,h的,也是可以的,修改一下split_label的代码,或者写个小脚本把x,y,w,h转换成x1,y1,x2,y2,x3,y3,x4,y4就行。
图片标注方法
如果想训练自己的数据集,那么我们可以自己去标注图片。本文将推荐一个十分好用的数据标注工具LabelImg。
这款工具是全图形界面,用Python和Qt写的,最牛的是其标注信息可以直接转化成为XML文件,与PASCAL VOC以及ImageNet用的XML是一样的。(具体如何使用,直接参考下面GitHub或者网上百度即可)
它来自下面的项目:https://github.com/tzutalin/labelImg
其中标签存储功能和“Next Image”、“Prev Image”的设计使用起来比较方便。
该软件最后保存的xml文件格式和ImageNet数据集是一样的。
• Labelme 适用于图像分割任务的数据集制作
• labellmg适用于图像检测任务的数据集制作
• yolo_mark适用于图像检测任务的数据集制作
• Vatic适用于图像检测任务的数据集制作
注(标注工具生成的的是xml文件,可直接生成数据集无需执行python3 split_label.py,另外labelimg工具产生的是左上和右下坐标并非四点坐标,有能解决此问题的分享给我,谢谢)
5.训练
简单的运行
你可以在ctpn/text.yml中修改一些参数,或者只使用作者设置的参数
作者提供的模型在GTX1070上训练了50K iters
如果我们正在使用cuda nms ,它每次约需要0.2秒,因此完成50k迭代需要大约2.5小时
当然,我们可以指定在那块显卡上运行,比如我这里指定选择第一块显卡上训练,训练的命令如下:
CUDA_VISIBLE_DEVICES=“0” python ./ctpn/train_net.py
训练完成后 cd 项目/ctpn/ctpn/text.yml 修改模型加载路径

densenet训练
1. 数据准备
数据集:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
共约364万张图片,按照99:1划分成训练集和验证集
数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成
包含汉字、英文字母、数字和标点共5990个字符
每个样本固定10个字符,字符随机截取自语料库中的句子
图片分辨率统一为280x32
图片解压后放置到train/images目录下,描述文件放到train目录下
2. 训练
cd train
python3 train.py
3.数据集制作
1.工具生成数据集
可参考SynthText_Chinese_version,TextRecognitionDataGenerator和text_renderer
2.个人制作数据集
图片可使用opencv处理
标注文本:手工标注文字
标注文件格式转换:百度网盘
链接:https://pan.baidu.com/s/13ja-547KlebHrROZmwLBWQ
提取码:tkq8
</div>















 4287
4287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









