







一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
we are interested – the first is the output probabilities and the
second can be used to derive the bounding box coordinates of text
layerNames = [
“feature_fusion/Conv_7/Sigmoid”,
“feature_fusion/concat_3”]
我们构建了一个 layerNames 列表:
第一层是我们的输出 sigmoid 激活,它为我们提供了一个区域是否包含文本的概率。
第二层是输出特征图,表示图像的“几何”——我们将能够使用这个几何来推导出输入图像中文本的边界框坐标
让我们加载 OpenCV 的 EAST 文本检测器:
load the pre-trained EAST text detector
print(“[INFO] loading EAST text detector…”)
net = cv2.dnn.readNet(args[“east”])
construct a blob from the image and then perform a forward pass of
the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
start = time.time()
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
end = time.time()
show timing information on text prediction
print(“[INFO] text detection took {:.6f} seconds”.format(end - start))
我们使用 cv2.dnn.readNet 将神经网络加载到内存中,方法是将路径传递给 EAST 检测器。
然后,我们通过将其转换为 blob 来准备我们的图像。要阅读有关此步骤的更多信息,请参阅深度学习:OpenCV 的 blobFromImage 工作原理。 为了预测文本,我们可以简单地将 blob 设置为输入并调用 net.forward。 这些行被抓取时间戳包围,以便我们可以打印经过的时间。 通过将 layerNames 作为参数提供给 net.forward,我们指示 OpenCV 返回我们感兴趣的两个特征图:
-
用于导出输入图像中文本的边界框坐标的输出几何图
-
同样,分数图,包含给定区域包含文本的概率
我们需要一个一个地循环这些值中的每一个:
grab the number of rows and columns from the scores volume, then
initialize our set of bounding box rectangles and corresponding
confidence scores
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
loop over the number of rows
for y in range(0, numRows):
extract the scores (probabilities), followed by the geometrical
data used to derive potential bounding box coordinates that
surround text
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
我们首先获取分数卷的维度(,然后初始化两个列表:
-
rects :存储文本区域的边界框 (x, y) 坐标
-
置信度:将与每个边界框关联的概率存储在 rects 中
我们稍后将对这些区域应用非极大值抑制。 循环遍历行。提取当前行 y 的分数和几何数据。 接下来,我们遍历当前选定行的每个列索引:
loop over the number of columns
for x in range(0, numCols):
if our score does not have sufficient probability, ignore it
if scoresData[x] < args[“min_confidence”]:
continue
compute the offset factor as our resulting feature maps will
be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
extract the rotation angle for the prediction and then
compute the sin and cosine
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
use the geometry volume to derive the width and height of
the bounding box
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
compute both the starting and ending (x, y)-coordinates for
the text prediction bounding box
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
add the bounding box coordinates and probability score to
our respective lists
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
对于每一行,我们开始遍历列。 我们需要通过忽略概率不够高的区域来过滤掉弱文本检测。
当图像通过网络时,EAST 文本检测器自然会减小体积大小——我们的体积大小实际上比我们的输入图像小 4 倍,因此我们乘以 4 以将坐标带回原始图像。
提取角度数据。 然后我们分别更新我们的矩形和置信度列表。 我们快完成了! 最后一步是对我们的边界框应用非极大值抑制来抑制弱重叠边界框,然后显示结果文本预测:
apply non-maxima suppression to suppress weak, overlapping bounding
boxes
boxes = non_max_suppression(np.array(rects), probs=confidences)
loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
scale the bounding box coordinates based on the respective
ratios
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
draw the bounding box on the image
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
show the output image
cv2.imshow(“Text Detection”, orig)
cv2.waitKey(0)
正如我在上一节中提到的,我无法在我的 OpenCV 4 安装 (cv2.dnn.NMSBoxes) 中使用非最大值抑制,因为 Python 绑定没有返回值,最终导致 OpenCV 出错。我无法完全在 OpenCV 3.4.2 中进行测试,因此它可以在 v3.4.2 中运行。
相反,我使用了 imutils 包(第 114 行)中提供的非最大值抑制实现。结果看起来还是不错的;但是,我无法将我的输出与 NMSBoxes 函数进行比较以查看它们是否相同。 循环我们的边界框,将坐标缩放回原始图像尺寸,并将输出绘制到我们的原始图像。原始图像会一直显示,直到按下某个键。
作为最后的实现说明,我想提一下,我们用于循环分数和几何体的两个嵌套 for 循环将是一个很好的例子,说明您可以利用 Cython 显着加速您的管道。我已经使用 OpenCV 和 Python 在快速优化的“for”像素循环中展示了 Cython 的强大功能。
========================================================================
您准备好将文本检测应用于图像了吗?
下载frozen_east_text_detection,地址:
oyyd/frozen_east_text_detection.pb (github.com)
。 从那里,您可以在终端中执行以下命令(注意两个命令行参数):
$ python text_detection.py --image images/lebron_james.jpg \
–east frozen_east_text_detection.pb
您的结果应类似于下图:
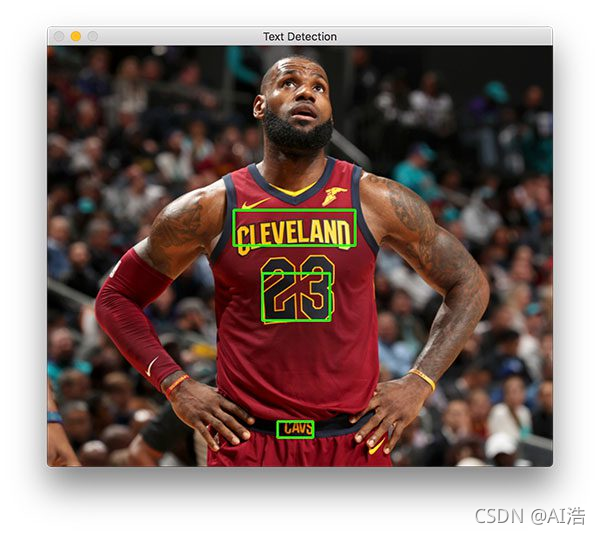
在勒布朗·詹姆斯身上标识了三个文本区域。 现在让我们尝试检测商业标志的文本:
$ python text_detection.py --image images/car_wash.png \
–east frozen_east_text_detection.pb
使用 OpenCV 检测视频中的文本
现在我们已经了解了如何检测图像中的文本,让我们继续使用 OpenCV 检测视频中的文本。 这个解释将非常简短; 请根据需要参阅上一节了解详细信息。 打开 text_detection_video.py 并插入以下代码:
import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import imutils
import time
import cv2
我们首先导入我们的包。 我们将使用 VideoStream 访问网络摄像头和 FPS 来对这个脚本的每秒帧数进行基准测试。 其他一切都与上一节相同。
为方便起见,让我们定义一个新函数来解码我们的预测函数——它将在每一帧中重复使用,并使我们的循环更清晰:
def decode_predictions(scores, geometry):
grab the number of rows and columns from the scores volume, then
initialize our set of bounding box rectangles and corresponding
confidence scores
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
loop over the number of rows
for y in range(0, numRows):
extract the scores (probabilities), followed by the
geometrical data used to derive potential bounding box
coordinates that surround text
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
loop over the number of columns
for x in range(0, numCols):
if our score does not have sufficient probability,
ignore it
if scoresData[x] < args[“min_confidence”]:
continue
compute the offset factor as our resulting feature
maps will be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
extract the rotation angle for the prediction and
then compute the sin and cosine
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
use the geometry volume to derive the width and height
of the bounding box
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
compute both the starting and ending (x, y)-coordinates
for the text prediction bounding box
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
add the bounding box coordinates and probability score
to our respective lists
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
return a tuple of the bounding boxes and associated confidences
return (rects, confidences)
定义了 decode_predictions 函数。
该函数用于提取: 文本区域的边界框坐标 和一个文本区域检测的概率 此专用函数将使代码在此脚本中稍后更易于阅读和管理。 让我们解析我们的命令行参数:
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-east”, “–east”, type=str, required=True,
help=“path to input EAST text detector”)
ap.add_argument(“-v”, “–video”, type=str,
help=“path to optinal input video file”)
ap.add_argument(“-c”, “–min-confidence”, type=float, default=0.5,
help=“minimum probability required to inspect a region”)
ap.add_argument(“-w”, “–width”, type=int, default=320,
help=“resized image width (should be multiple of 32)”)
ap.add_argument(“-e”, “–height”, type=int, default=320,
help=“resized image height (should be multiple of 32)”)
args = vars(ap.parse_args())
命令行参数解析:
–east : EAST 场景文本检测器模型文件路径。
–video :我们输入视频的路径。 可选 — 如果提供了视频路径,则不会使用网络摄像头。
–min-confidence :确定文本的概率阈值。 可选, default=0.5 。
–width :调整后的图像宽度(必须是 32 的倍数)。 可选的 default=320 。
–height :调整后的图像高度(必须是 32 的倍数)。 可选的 default=320 。
与上一节中的纯图像脚本相比(在命令行参数方面)的主要变化是我用 --video 替换了 --image 参数。 重要提示:EAST 文本要求您的输入图像尺寸是 32 的倍数,因此如果您选择调整 --width 和 --height 值,请确保它们是 32 的倍数! 接下来,我们将执行模仿前一个脚本的重要初始化:
initialize the original frame dimensions, new frame dimensions,
and ratio between the dimensions
(W, H) = (None, None)
(newW, newH) = (args[“width”], args[“height”])
(rW, rH) = (None, None)
define the two output layer names for the EAST detector model that
we are interested – the first is the output probabilities and the
second can be used to derive the bounding box coordinates of text
layerNames = [
“feature_fusion/Conv_7/Sigmoid”,
“feature_fusion/concat_3”]
load the pre-trained EAST text detector
print(“[INFO] loading EAST text detector…”)
net = cv2.dnn.readNet(args[“east”])
高度/宽度和比率初始化将允许我们稍后正确缩放边界框。 我们的输出层名称已定义,加载我们预先训练的 EAST 文本检测器。 以下块设置我们的视频流和每秒帧数计数器:
if a video path was not supplied, grab the reference to the web cam
if not args.get(“video”, False):
print(“[INFO] starting video stream…”)
vs = VideoStream(src=0).start()
time.sleep(1.0)
otherwise, grab a reference to the video file
else:
vs = cv2.VideoCapture(args[“video”])
start the FPS throughput estimator
fps = FPS().start()
我们的视频流设置为: 网络摄像头 或视频文件
初始化每秒帧数计数器并开始循环传入帧:
loop over frames from the video stream
while True:
grab the current frame, then handle if we are using a
VideoStream or VideoCapture object
frame = vs.read()
frame = frame[1] if args.get(“video”, False) else frame
check to see if we have reached the end of the stream
if frame is None:
break
resize the frame, maintaining the aspect ratio
frame = imutils.resize(frame, width=1000)
orig = frame.copy()
if our frame dimensions are None, we still need to compute the
ratio of old frame dimensions to new frame dimensions
if W is None or H is None:
(H, W) = frame.shape[:2]
rW = W / float(newW)
rH = H / float(newH)
resize the frame, this time ignoring aspect ratio
frame = cv2.resize(frame, (newW, newH))
遍历视频/网络摄像头帧。 我们的框架被调整大小,保持纵横比。 从那里,我们获取维度并计算缩放比例。 然后我们再次调整框架的大小(必须是 32 的倍数),这次忽略纵横比,因为我们已经存储了安全保存的比率。 推理和绘制文本区域边界框发生在以下几行:
construct a blob from the frame and then perform a forward pass
of the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(frame, 1.0, (newW, newH),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
decode the predictions, then apply non-maxima suppression to
suppress weak, overlapping bounding boxes
(rects, confidences) = decode_predictions(scores, geometry)
boxes = non_max_suppression(np.array(rects), probs=confidences)
loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
scale the bounding box coordinates based on the respective
ratios
startX = int(startX * rW)
startY = int(startY * rH)
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









