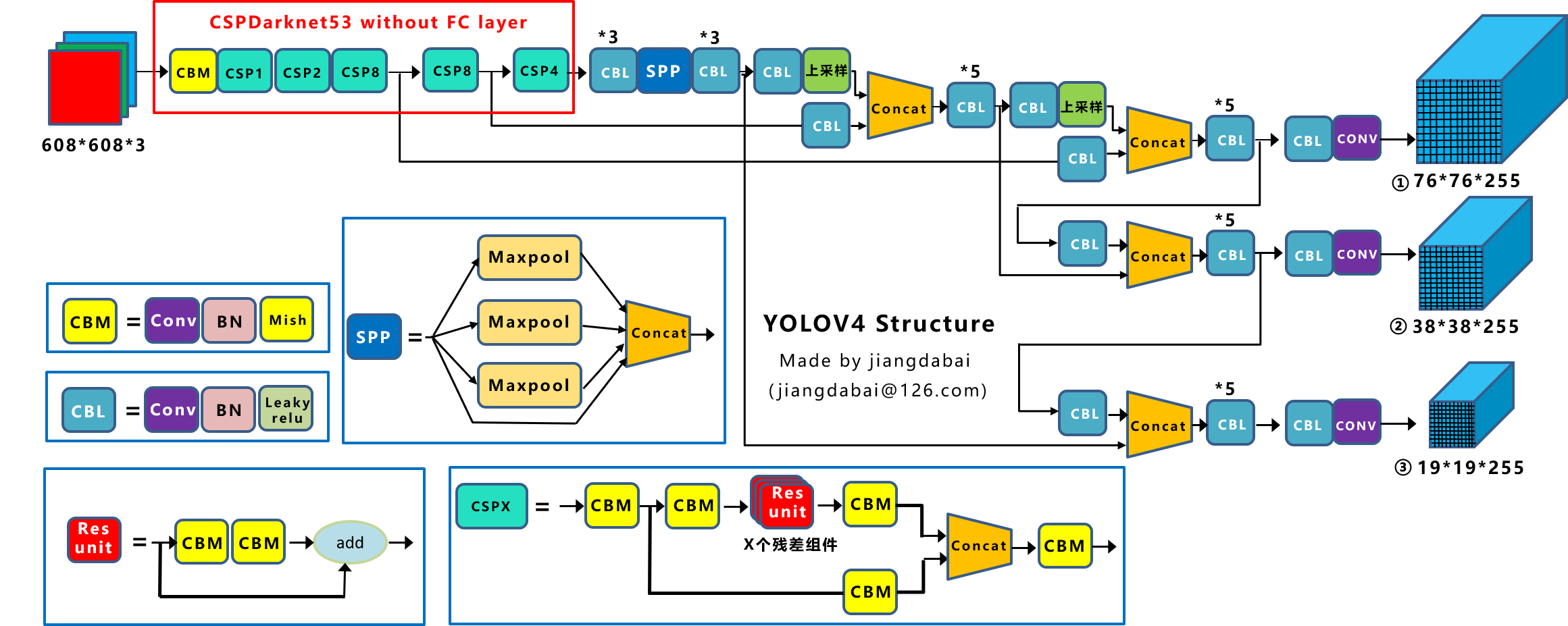
文章目录 总结 改进 输入的改进 BackBone创新 Dropblock Sppnet CBAM conv block attation module PAN 双向特征传播(path aggregation network) 总结 前几篇文章总结了一些1,2,3的特征,基本上v3 也是当前应用最广泛的了。 接下来说说v4 改进 输入的改进 数据的增强: Mosaic数据增强 Mosaic:进行了数据随机缩放、随机裁剪、随机排布的方式进行拼接。 优点: 丰富数据集,减少GPU Sat: 增加噪音点,如0.008 ,增加难度 ** label smothing** : 增加拟合难度,不让网络拟合到100% BackBone创新 改变了darknet-53 ,变成了CSP darknet53 引入5层Csp ,并且激活函数改为了mish,可以很好的降低计算量,








 超级会员免费看
超级会员免费看
 YOLOv4在输入、BackBone、数据增强等方面进行了多项改进,如Mosaic数据增强、CSP Darknet53、Dropblock等。通过Sppnet、CBAM和PAN提升特征提取和注意力机制,优化模型性能。
YOLOv4在输入、BackBone、数据增强等方面进行了多项改进,如Mosaic数据增强、CSP Darknet53、Dropblock等。通过Sppnet、CBAM和PAN提升特征提取和注意力机制,优化模型性能。


 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 4073
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
4073
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








