







 本文作者分享了在Kaggle QBUS6810比赛中使用逻辑回归进行预测的经验,包括数据探索、预处理和模型构建。在数据探索阶段,作者通过EDA分析确定了数据类型,并进行了特征筛选。预处理环节,使用log1p转换连续型变量,对离散型数据进行one-hot编码,并进行了数据归一化。最后,通过GridSearchCV寻找最佳超参数,构建逻辑回归模型。
本文作者分享了在Kaggle QBUS6810比赛中使用逻辑回归进行预测的经验,包括数据探索、预处理和模型构建。在数据探索阶段,作者通过EDA分析确定了数据类型,并进行了特征筛选。预处理环节,使用log1p转换连续型变量,对离散型数据进行one-hot编码,并进行了数据归一化。最后,通过GridSearchCV寻找最佳超参数,构建逻辑回归模型。
前言
目前是小型比赛的public lb第四名,自己对此也比较满意了,从中也学到不少知识。发个图纪念一下,从一开始的0.76,到0.85,再到现在0.86139,每一次的进步都来之不易。之后private lb选了一个比较低的提交,因为是校外的,就不影响他们的成绩了。
这个比赛的目标是给出一些市场的环境,预测消费者会不会在该环境进行消费。接下来简单的复盘一下:
1. EDA(数据探索):
首先是data的overview

检查代码是否有空值
print(data.isnull().sum())
visits 0
total_sales 0
credit_card 0
sales_product_category_1 0
sales_product_category_2 0
......
returns 0
conversion 0
dtype: int64按数据类型初步划分连续还是离散数据,float类型当成是连续的
print(data.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4122 entries, 0 to 4121
Data columns (total 44 columns):
visits 4122 non-null int64
total_sales 4122 non-null float64
credit_card 4122 non-null int64
sales_product_category_1 4122 non-null float64
sales_product_category_2 4122 non-null float64
......
returns 4122 non-null float64
conversion 4122 non-null int64
dtypes: float64(30), int64(13), object(1)这里看到object类型,我们要把它转化成数值型
print(data['phone_on_file'].value_counts()) 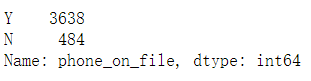
这里把y变成1,n变成0,画出图,可以看到区分度不大,可以删去。代码略过。

打开csv文件,可以发现total_sales是一列汇总数,等于sales_stores_n几列相加,n为1到4。我们可以直接把sales_stores给drop了,减少共线性。
然后查看连续变量的热力图,可以继续删除相关程度高的变量。代码略过。
以下就是variables.csv的分类结果。
drop代表删掉,因为相关度高或者对模型影响不大。
binary是bool型数据,dicrete是离散型,continuous是连续型,
categorical是个人认为的类型,和离散型差不多。response是结果,记录是否消费。(提交要预测概率)
| variable |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









