







本小节示例另一种马尔可夫识别XSS攻击的方法。
一、原理
本小节通过将机器当做小白,训练它学会XSS攻击语法,然后再让机器从访问日志中寻找符合攻击语法的疑似攻击日志。
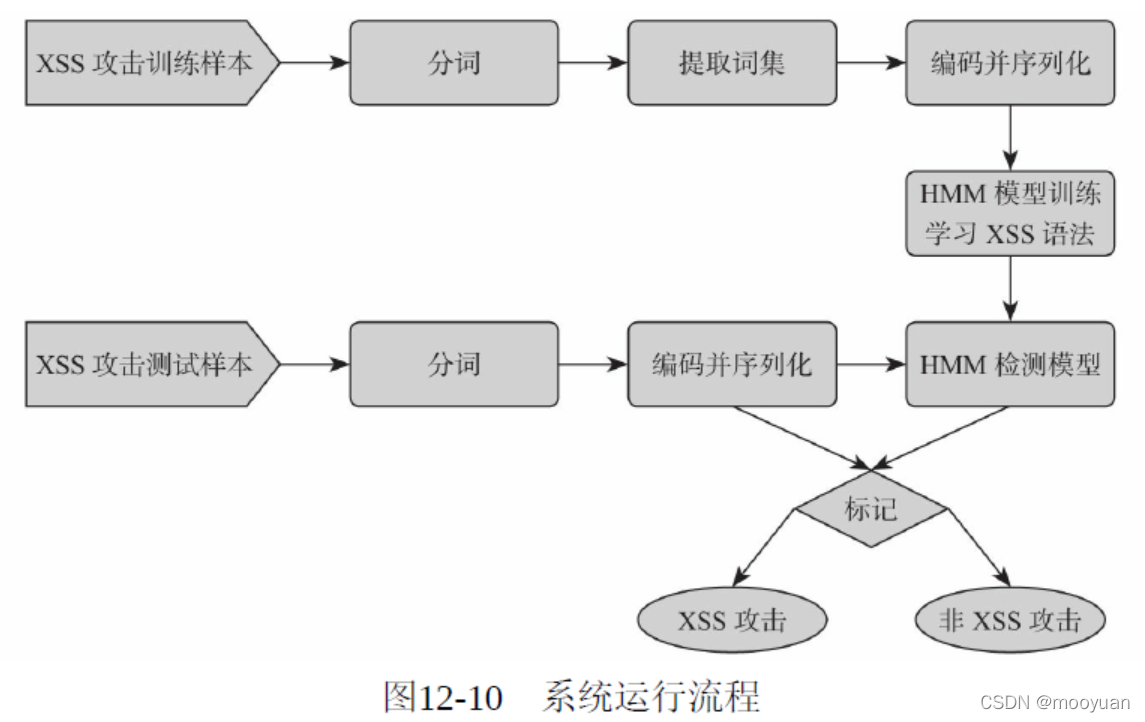
整个系统运行流程如下所示:
二、词袋/词集模型
词集模型:单词构成的集合,集合中自然每个元素都只有一个,即词集中每个单词都只有一个
词袋模型:如果一个单词在文档中出现不止一次,统计出现的次数
通常是先生存词汇表,再生成词集。训练样本是1000条典型的XSS攻击日志,通过分词、计算词集,提炼出200个特征,全部样本就使用这200个特征进行编码并序列化。
 为了减少向量空间,需要把数字、字符以及超链接泛化,代码如下:
为了减少向量空间,需要把数字、字符以及超链接泛化,代码如下:
#数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
#url 换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:=]+', "http://u", line)
#干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)分词则是需要基于XSS特征,代码如下:
#</script><script>alert(String.fromCharCode(88,83,83))</script>
#<IMG SRC=x onchange="alert(String.fromCharCode(88,83,83))">
#<;IFRAME SRC=http://ha.ckers.org/scriptlet.html <;
#';alert(String.fromCharCode(88,83,83))//\';alert(String.fromCharCode(88,83,83))//";alert(String.fromCharCode(88,83,83))
# //\";alert(String.fromCharCode(88,83,83))//--></SCRIPT>">'><SCRIPT>alert(String.fromCharCode(88,83,83))</SCRIPT>
tokens_pattern = r'''(?x)
"[^"]+"
|http://\S+
|</\w+>
|<\w+>
|<\w+
|\w+=
|>
|\w+\([^<]+\) #函数 比如alert(String.fromCharCode(88,83,83))
|\w+
'''
def do_str(line):
words=nltk.regexp_tokenize(line, tokens_pattern)
#print(words)
return words数据集处理部分代码逻辑如下:
def load_wordbag(filename,max=100):
X = [[0]]
X_lens = [1]
tokens_list=[]
global wordbag
global index_wordbag
with open(filename) as f:
for line in f:
line=line.strip('\n')
#url解码
line=parse.unquote(line)
#处理html转义字符
h = HTMLParser()
line=h.unescape(line)
if len(line) >= MIN_LEN:
#print ("Learning xss query param:(%s)" % line)
#数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
#ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:=]+', "http://u", line)
#干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)
#print ("Learning xss query etl param:(%s) " % line)
tokens_list+=do_str(line)
#X=np.concatenate( [X,vers])
#X_lens.append(len(vers))
fredist = nltk.FreqDist(tokens_list) # 单文件词频
keys=list(fredist.keys())
keys=keys[:max]
for localkey in keys: # 获取统计后的不重复词集
if localkey in wordbag.keys(): # 判断该词是否已在词袋中
continue
else:
wordbag[localkey] = index_wordbag
index_wordbag += 1
print("GET wordbag size(%d)" % index_wordbag)三、训练模型
(1)模型保存
训练好的模型保存为xss-train.pkl,代码如下
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, "xss-train.pkl")(2)模型训练
训练样本为xss黑样本,训练时的数据集处理的完整代码如下:
def train(filename):
X = [[-1]]
X_lens = [1]
global wordbag
global index_wordbag
with open(filename, encoding='utf-8') as f:
for line in f:
line=line.strip('\n')
#url解码
line=parse.unquote(line)
#处理html转义字符
line=html.unescape(line)
if len(line) >= MIN_LEN:
#print ("Learning xss query param:(%s)" % line)
#数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
#ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", line)
#干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)
#print ("Learning xss query etl param:(%s) " % line)
words=do_str(line)
vers=[]
for word in words:
#print ("ADD %s" % word)
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
X=np.concatenate([X,np_vers])
X_lens.append(len(np_vers))
print(len(X_lens), X_lens)
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, "xss-train.pkl")
return remodel(3)优化训练
这里我认为代码应该使用基于黑样本特征而训练,即
def train_black(filename, train_model):
X = [[-1]]
X_lens = [1]
global wordbag
global index_wordbag
with open(filename, encoding='utf-8') as f:
for line in f:
# 切割参数
result = parse.urlparse(line)
# url解码
query = parse.unquote(result.query)
params = parse.parse_qsl(query, True)
for k, v in params:
v=v.strip('\n')
#print "CHECK v:%s LINE:%s " % (v, line)
if len(v) >= MIN_LEN:
# print "CHK XSS_URL:(%s) " % (line)
# 数字常量替换成8
v, number = re.subn(r'\d+', "8", v)
# ulr日换成http://u
v, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", v)
# 干掉注释
v, number = re.subn(r'\/\*.?\*\/', "", v)
# print "Learning xss query etl param:(%s) " % line
words = do_str(v)
# print "GET Tokens (%s)" % words
vers = []
for word in words:
# print "ADD %s" % word
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
X = np.concatenate([X, np_vers])
X_lens.append(len(np_vers))
print(len(X_lens), X_lens)
remodel = hmm.GaussianHMM(n_components=3, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, train_model)
return remodel四、验证模型
(1)测试模型
如下代码逻辑是基于白样本的测试函数,具体如下
def test(filename):
remodel = joblib.load("xss-train.pkl")
i = 1
x = []
y = []
with open(filename, encoding='utf-8') as f:
for line in f:
#print(i,line)
i= i +1
line = line.strip('\n')
# url解码
line = parse.unquote(line)
# 处理html转义字符
line = html.unescape(line)
if len(line) >= MIN_LEN:
#print("CHK XSS_URL:(%s) " % (line))
# 数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
# ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", line)
# 干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)
#print("Learning xss query etl param:(%s) " % line)
words = do_str(line)
#print("GET Tokens (%s)" % words)
vers = []
for word in words:
# print(("ADD %s" % word)
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
pro = remodel.score(np_vers)
x.append(len(vers))
y.append(pro)
return x, y基于上一小节的理解,可以将其分为基于白样本和黑样本两类:
(2)黑样本优化测试
def test_black(filename, train_model):
remodel=joblib.load(train_model)
x = []
y = []
with open(filename, encoding='utf-8') as f:
for line in f:
# 切割参数
result = parse.urlparse(line)
# url解码
query = parse.unquote(result.query)
params = parse.parse_qsl(query, True)
for k, v in params:
v=v.strip('\n')
#print "CHECK v:%s LINE:%s " % (v, line)
if len(v) >= MIN_LEN:
# print "CHK XSS_URL:(%s) " % (line)
# 数字常量替换成8
v, number = re.subn(r'\d+', "8", v)
# ulr日换成http://u
v, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", v)
# 干掉注释
v, number = re.subn(r'\/\*.?\*\/', "", v)
# print "Learning xss query etl param:(%s) " % line
words = do_str(v)
# print "GET Tokens (%s)" % words
vers = []
for word in words:
# print "ADD %s" % word
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
#print("CHK SCORE:(%d) QUREY_PARAM:(%s) XSS_URL:(%s) " % (pro, v, line))
pro = remodel.score(np_vers)
x.append(len(vers))
y.append(pro)
return x, y
(3)白样本优化测试
def test_white(filename, train_model):
remodel = joblib.load(train_model)
i = 1
x = []
y = []
with open(filename, encoding='utf-8') as f:
for line in f:
#print(i,line)
i= i +1
line = line.strip('\n')
# url解码
line = parse.unquote(line)
# 处理html转义字符
line = html.unescape(line)
if len(line) >= MIN_LEN:
#print("CHK XSS_URL:(%s) " % (line))
# 数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
# ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", line)
# 干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)
#print("Learning xss query etl param:(%s) " % line)
words = do_str(line)
#print("GET Tokens (%s)" % words)
vers = []
for word in words:
# print("ADD %s" % word)
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
pro = remodel.score(np_vers)
x.append(len(vers))
y.append(pro)
return x, y
五、测试数据
使用正常日志与XSS攻击日志进行测试。
pro = remodel.score(np_vers)完整代码
if __name__ == '__main__':
train_file = 'xss-10000.txt'
load_wordbag(train_file,200)
remodel = main(train_file)
x1, y1 = test('./good-xss-10000.txt')
x2, y2 = test('./xss-10000.txt')
fig,ax=plt.subplots()
ax.set_xlabel('Line Length')
ax.set_ylabel('HMM Score')
ax.scatter(x2, y2, color='g', label="xss",marker='v')
ax.scatter(x1, y1, color='r', label="good",marker='*')
ax.legend(loc='best')
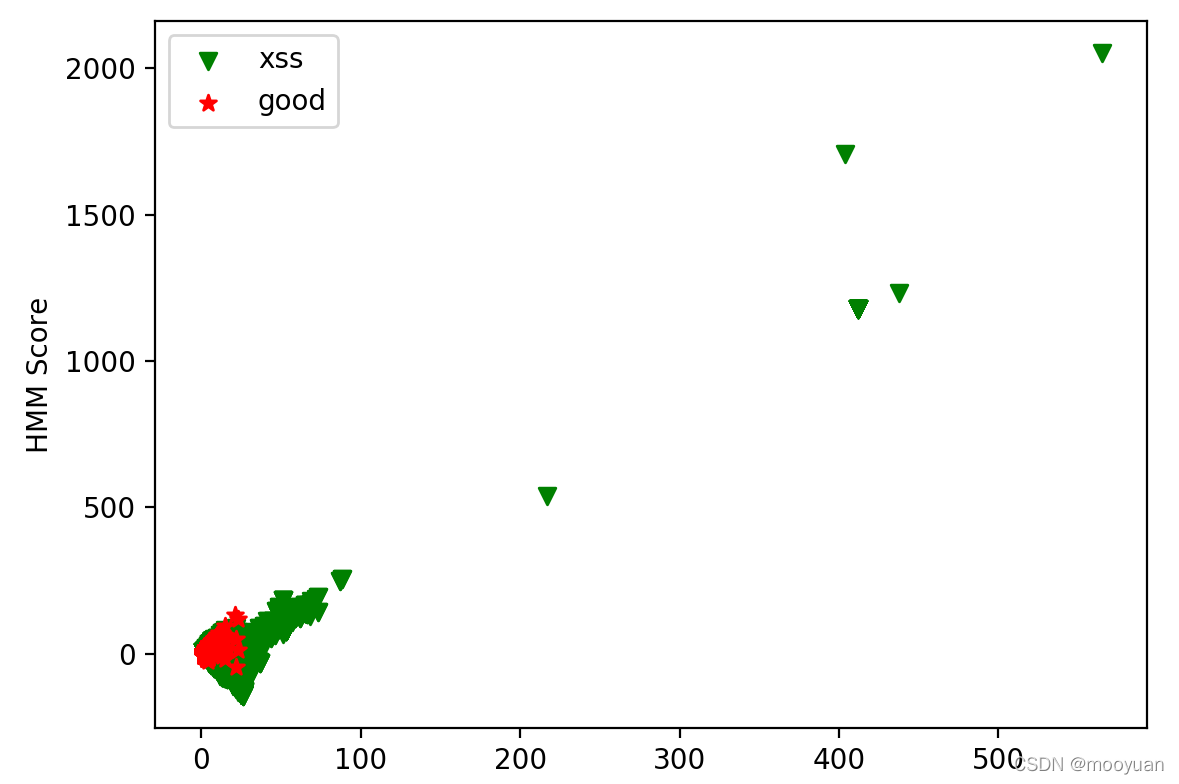
plt.show()y1和y2的长度如下
8018 10000图示如下
六、优化对比测试
(1)黑样本训练
if __name__ == '__main__':
train_file = 'xss-10000.txt'
train_model = '"xss-train_black.pkl"'
load_wordbag(train_file,200)
remodel = train_black(train_file, train_model)(2)黑样本测试
这里使用黑样本训练,用黑白样本分别测试:
if __name__ == '__main__':
train_file = 'xss-10000.txt'
train_model = '"xss-train_black.pkl"'
load_wordbag(train_file,200)
remodel = train_black(train_file, train_model)
x1, y1 = test_black('./good-xss-10000.txt',train_model)
x2, y2 = test_black('./xss-10000.txt', train_model)
print(len(y1), len(y2))
fig,ax=plt.subplots()
ax.set_xlabel('Line Length')
ax.set_ylabel('HMM Score')
ax.scatter(x2, y2, color='g', label="xss",marker='v')
ax.scatter(x1, y1, color='r', label="good",marker='*')
ax.legend(loc='best')
plt.show()这里测试模型过滤后白样本仅193,黑样本为16072个
193 16072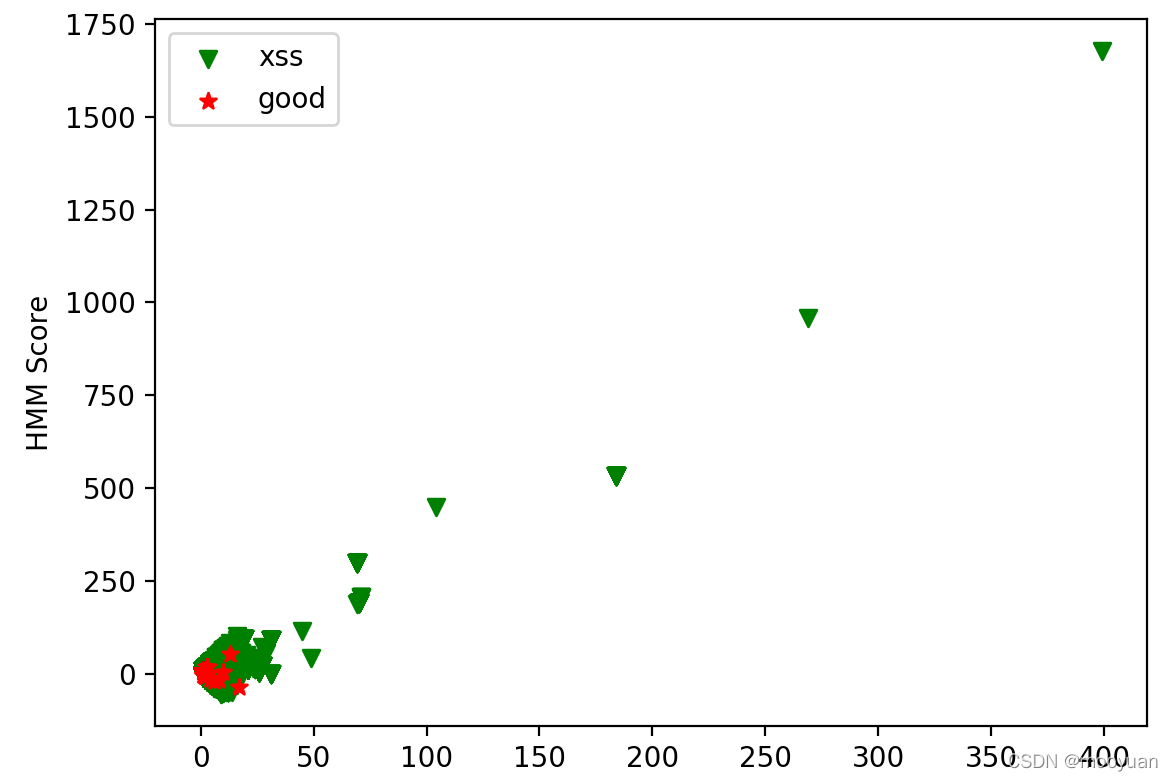
(3)白样本函数
if __name__ == '__main__':
train_file = 'xss-10000.txt'
train_model = '"xss-train_black.pkl"'
load_wordbag(train_file,200)
remodel = train_black(train_file, train_model)
x1, y1 = test_write('./good-xss-10000.txt',train_model)
x2, y2 = test_write('./xss-10000.txt', train_model)
print(len(y1), len(y2))
fig,ax=plt.subplots()
ax.set_xlabel('Line Length')
ax.set_ylabel('HMM Score')
ax.scatter(x2, y2, color='g', label="xss",marker='v')
ax.scatter(x1, y1, color='r', label="good",marker='*')
ax.legend(loc='best')
plt.show()测试结果
8018 10000
图示如下
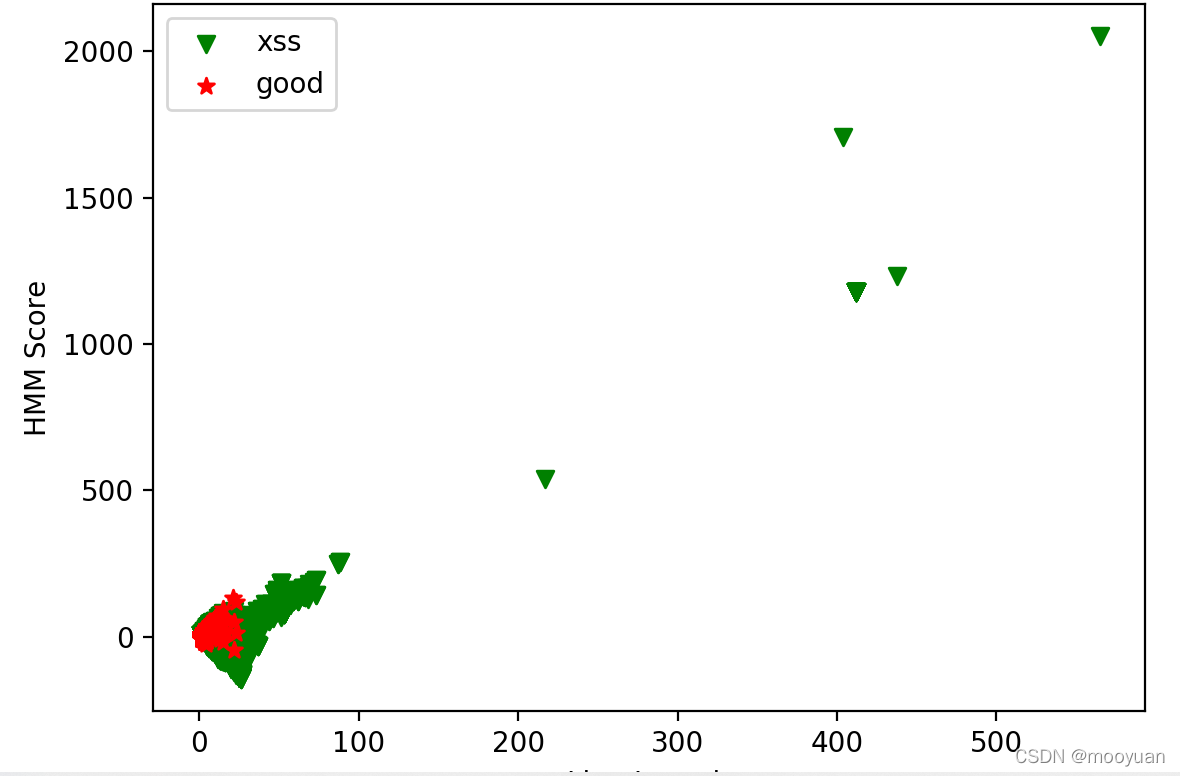
(4)黑样本用黑样本函数,白样本用白函数混用
黑样本用黑样本函数,白样本用白样本函数
if __name__ == '__main__':
train_file = 'xss-10000.txt'
train_model = '"xss-train_black.pkl"'
load_wordbag(train_file,200)
remodel = train_black(train_file, train_model)
x1, y1 = test_white('./good-xss-10000.txt',train_model)
x2, y2 = test_black('./xss-10000.txt', train_model)
print(len(y1), len(y2))
fig,ax=plt.subplots()
ax.set_xlabel('Line Length')
ax.set_ylabel('HMM Score')
ax.scatter(x2, y2, color='g', label="xss",marker='v')
ax.scatter(x1, y1, color='r', label="good",marker='*')
ax.legend(loc='best')
plt.show()测试结果
8018 16072图示如下

不过黑样本训练后,使用三种测试效果都不咋地,也就特征过于明显的test_write效果稍微好一点点。
总体来讲,这两小节的实验效果除了test_write这种方式的分词方式,无论是白生成黑,还是黑生成白,哪种训练和测试方法效果都不太明显。而且我发现词汇长度相似的情况下,两小节的score效果也相近。
因为作者配套源码未有给出如何运行,未给出明确数据集,书上给的参数与源码很多都不一致,也没有详细注释,修改后多次调试训练结果不好,此节只是暂时初步理解这种方法即可。
后续如有深刻理解,会更新此笔记,也欢迎指教。
















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











