







消息传递和节点分类
本节需要解决的问题是:假如一个图中某些节点的标签已经知道,如何根据节点的邻接关系和节点特征来确定其他节点的标签。在第三讲中,我们已经介绍了利用节点嵌入和传统机器学习方法给节点分类,本节讲介绍如何利用消息 (message passing) 来预测节点分类。本节内容包括:
- 网络中节点的同质性 (Homophily) 和影响性 (Influence)
- 节点集体分类 (Collective classification) 的方法
- 关联分类 (Relational classification)
- 迭代分类 (Iterative classification)
- 信念传播 (Belief propagation)
同质性和影响性
同质性 (Homophily) 具有相似特征的个体倾向于聚集和关联,也就是“人以类聚,物以群分”,比如同意邻域的研究人员更容易建立相互连接。影响性 (Influence) 指的是具有连接的个体之间会相互影响从而改变个体的特征,也就是"近朱者赤,近墨者黑"。
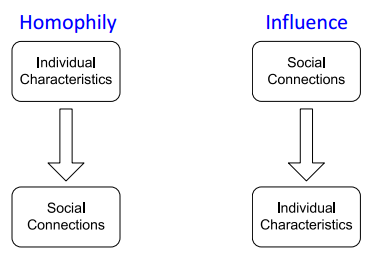
基于同质性和影响性的假设,可以认为节点的分类取决于
-
节点自身的特征
-
邻域节点的类别
-
邻域节点的特征
不同节点的分类标签是相互关联的,这里我们可以假设节点的标签分类符合 Markov 假设,即节点的标签只与其邻域节点相关:
P
(
Y
v
)
=
P
(
Y
v
∣
N
V
)
P(Y_v) = P(Y_v | N_V)
P(Yv)=P(Yv∣NV)
基于以上两点,我们可以采用集体分类 (Collective classification) 的方法。集体分类方法包括3个步骤
- 局部分类 (Local Classifier):根据节点特征,为所有节点赋予初始标签值
- 关联分类 (Relational Classifier):根据节点的连接关系,计算节点的标签值
- 集体推断 (Collective Inference): 不断的对节点做关联分类预测,直到邻接节点间的标签不相容性达到最小, 也就是将节点的相互关联传播到整个网络
关联分类器
关联分类器的基本思想是节点属于某一类别的概率等于其邻域节点概率的加权和,已知类别的节点的概率值始终为1,而未知节点的初始概率值为0.5,通过下面的公式不断迭代计算和更新节点概率值知道收敛或者达到最大迭代次数,最终就能得到每个节点属于某一类别的概率。
P
(
Y
v
=
c
)
=
1
∑
(
v
,
u
)
∈
E
∑
(
v
,
u
)
∈
E
A
v
,
u
P
(
Y
u
=
c
)
P(Y_v = c) = \frac {1} {\sum_{(v, u)} \in E} \sum_{(v, u) \in E} A_{v, u} P(Y_u = c)
P(Yv=c)=∑(v,u)∈E1(v,u)∈E∑Av,uP(Yu=c)
其中
E
E
E 表示与节点
v
v
v 相连的边,
A
v
,
u
A_{v, u}
Av,u 表示边的权重,
P
(
Y
v
=
c
)
P(Y_v = c)
P(Yv=c) 表示节点属于类别
c
c
c 的概率。
关联分类器有两个缺点
- 不能保证计算一定能收敛
- 没有利用节点自身特征信息
具体迭代计算的例子可参考本课程对应的课件.
迭代分类
迭代分类中包括两个分类器: ϕ 1 ( f v ) \phi_1(f_v) ϕ1(fv) 根据节点特征向量预测节点类别; ϕ 2 ( f v , z v ) \phi_2(f_v, z_v) ϕ2(fv,zv) 根据节点特征和邻域节点特征的统计来预测节点类别。其中 z v z_v zv 一般可以取:
- 邻域 N v N_v Nv 中不同类别节点数量的归一化直方图
- 邻域 N v N_v Nv 中出现次数最多的节点标签值
- 邻域 N v N_v Nv 出现不同类别的数量
迭代分类分为两个阶段:
- 阶段1:根据节点特征计算节点标签
- 在训练时,需要训练两个分类器(分类器可采用线性分类器,SVM,神经网络等)
- ϕ 1 ( f v ) \phi_1(f_v) ϕ1(fv) 根据节点特征向量计算节点类别
- ϕ 2 ( f v , z v ) \phi_2(f_v, z_v) ϕ2(fv,zv) 根据节点特征和邻域节点特征的统计来计算节点类别
- 阶段2:不断迭代直到收敛
- 在测试时,首先用分类器 ϕ 1 \phi_1 ϕ1 预测节点标签 Y v Y_v Yv 并计算邻域特征 z v z_v zv ,然后用分类器 ϕ 2 \phi_2 ϕ2 预测最终节点标签
- 对于每一个节点,迭代计算有两步
- 根据当前邻域节点的标签 Y u Y_u Yu 计算中心节点的邻域特征 z v z_v zv
- 使用 ϕ 2 \phi_2 ϕ2 更新中心节点的 v v v 的标签值 Y v Y_v Yv
- 不断迭代直至收敛或达到最大迭代次数
注意:上述迭代过程也不能保证收敛。具体计算示例见对应课件。
循环信念传播 (Loopy Belief Propagation)
信念传播 (Belief propagation) 是一种动态规划方法,用来解决图的概率查询问题 (answering probability queries),它是一个节点之间相互传递消息且不断迭代的过程。使用循环信念传播,是因为图中可能存在环。消息传递简单解释可参考下图

消息传递的简单例子如下图,任务是计算图所有节点的数量

计算过程为
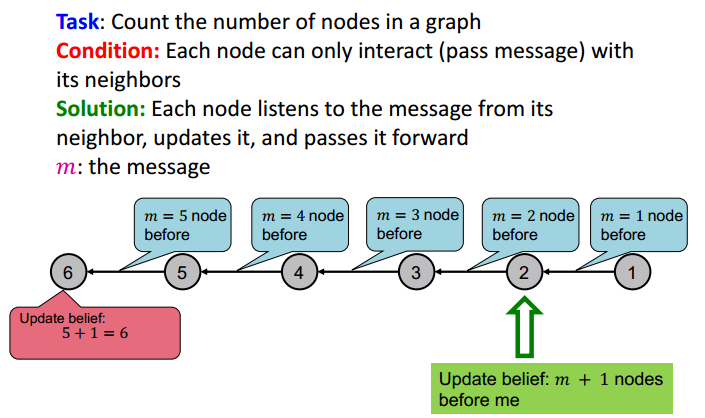
信念传播 (BP) 算法
如图,信念传播中的一个重要问题是如何计算节点 i i i 传递给节点 j j j 的消息,这依赖于节点 i i i 从其他节点听到消息。每一个邻接节点根据节点 i i i 可能存在的不同状态,会传递给 i i i 不同的消息。
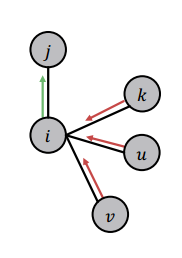
我们需要定义几个变量:
-
标签势能矩阵 (Label-label potential matrix) ψ \psi ψ :表示节点之间的相互依赖关系。 ψ ( Y i , Y j ) ∝ P ( Y j ∣ Y i ) \psi(Y_i, Y_j) \ \propto P(Y_j | Y_i) ψ(Yi,Yj) ∝P(Yj∣Yi)
-
先验信念 (Prior belief) ϕ \phi ϕ : ϕ ( Y i ) ∝ P ( Y i ) \phi(Y_i) \propto P(Y_i) ϕ(Yi)∝P(Yi)
-
m i → j ( Y j ) m_{i \rightarrow j} (Y_j) mi→j(Yj) :节点 j j j 类别为 Y j Y_j Yj 时,节点 i i i 向 节点 j j j 传递的消息
-
L \mathcal L L :所有类别的集合
信念传播的过程为:
- 将所有消息初始化为1
- 按照如下公式迭代计算节点消息
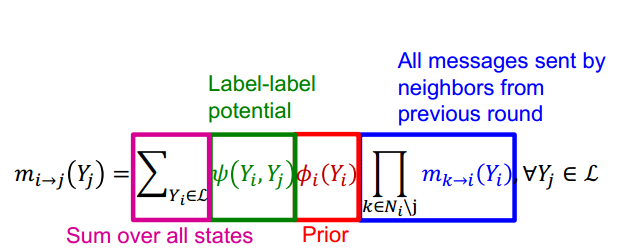
当计算收敛后,节点
i
i
i 属于类别
Y
i
Y_i
Yi 的置信度
b
i
(
Y
i
)
b_i(Y_i)
bi(Yi)
b
i
(
Y
i
)
=
ϕ
(
Y
i
)
∏
j
∈
N
i
m
j
→
i
(
Y
i
)
,
∀
Y
i
∈
L
b_i(Y_i) = \phi(Y_i) \prod _{j \in N_i} m_{j \rightarrow i} (Y_i), \quad \forall Y_i \in \mathcal L
bi(Yi)=ϕ(Yi)j∈Ni∏mj→i(Yi),∀Yi∈L
当图中包含环 (cycles)时,节点就不存在顺序,计算也不一定能收敛,但实际过程中,循环信念传播表现也不错。
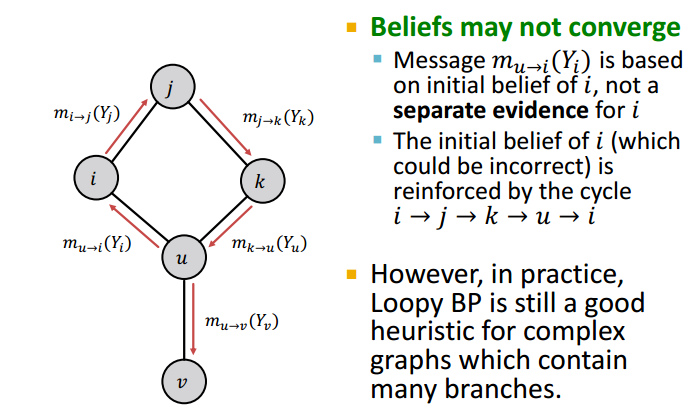
信念传播也会出现一些错误,参见下图。















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









