







图神经网络中的注意力机制
本文讨论了 GNN 中常用的注意力机制,相关论文有:
- Graph Attention Networks
- How Attentive are Graph Attention Networks
- Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
Graph Attention Networks (GAT)
GAT 的基本原理
GAT 是 GNN 中的经典模型,原始论文为 Graph Attention Networks 。在最初的 GCN 中,中心节点从邻域节点得到的消息会通过 sum, max, mean 等方式进行聚合,每个节点消息的重要性都是相等的。所谓注意力,就是希望中心节点对不同节点传递的消息做不同的对待,即对所有消息都分配一个权重。GAT 的思路非常简单,节点嵌入的计算方式为
x
i
′
=
α
i
,
i
W
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
W
x
j
\mathbf{x}^{\prime}_i = \alpha_{i,i}\mathbf{W}\mathbf{x}_{i} + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j}\mathbf{W}\mathbf{x}_{j}
xi′=αi,iWxi+j∈N(i)∑αi,jWxj
其中
α
i
,
j
\alpha_{i,j}
αi,j 表示节点
j
j
j 对节点
i
i
i 的注意力,计算公式为
α
i
,
j
=
exp
(
L
e
a
k
y
R
e
L
U
(
a
⊤
[
W
x
i
∥
W
x
j
]
)
)
∑
k
∈
N
(
i
)
∪
{
i
}
exp
(
L
e
a
k
y
R
e
L
U
(
a
⊤
[
W
x
i
∥
W
x
k
]
)
)
.
\alpha_{i,j} = \frac{ \exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top} [\mathbf{W}\mathbf{x}_i \, \Vert \, \mathbf{W}\mathbf{x}_j] \right)\right)} {\sum_{k \in \mathcal{N}(i) \cup \{ i \}} \exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top} [\mathbf{W}\mathbf{x}_i \, \Vert \, \mathbf{W}\mathbf{x}_k] \right)\right)}.
αi,j=∑k∈N(i)∪{i}exp(LeakyReLU(a⊤[Wxi∥Wxk]))exp(LeakyReLU(a⊤[Wxi∥Wxj])).
如果边
e
i
j
e_{ij}
eij 也有特征,那么注意力
α
i
,
j
\alpha_{i,j}
αi,j 可以是
α
i
,
j
=
exp
(
L
e
a
k
y
R
e
L
U
(
a
⊤
[
W
x
i
∥
W
x
j
∥
W
e
e
i
,
j
]
)
)
∑
k
∈
N
(
i
)
∪
{
i
}
exp
(
L
e
a
k
y
R
e
L
U
(
a
⊤
[
W
x
i
∥
W
x
k
∥
W
e
e
i
,
k
]
)
)
.
\alpha_{i,j} = \frac{ \exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top} [\mathbf{W}\mathbf{x}_i \, \Vert \, \mathbf{W}\mathbf{x}_j \, \Vert \, \mathbf{W}_{e} \mathbf{e}_{i,j}]\right)\right)} {\sum_{k \in \mathcal{N}(i) \cup \{ i \}} \exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top} [\mathbf{W}\mathbf{x}_i \, \Vert \, \mathbf{W}\mathbf{x}_k \, \Vert \, \mathbf{W}_{e} \mathbf{e}_{i,k}]\right)\right)}.
αi,j=∑k∈N(i)∪{i}exp(LeakyReLU(a⊤[Wxi∥Wxk∥Weei,k]))exp(LeakyReLU(a⊤[Wxi∥Wxj∥Weei,j])).
可以把上面的式子分解为两步,一是计算消息的权重 (weight)
β
i
,
j
=
σ
(
W
x
i
,
W
x
i
)
\beta_{i,j} = \sigma(\mathbf W \mathbf x_i, \mathbf W \mathbf x_i)
βi,j=σ(Wxi,Wxi)
二是通过 softmax 计算注意力
α
i
,
j
=
softmax
j
(
β
i
,
j
)
\alpha_{i,j} = \text{softmax}_j(\beta_{i,j})
αi,j=softmaxj(βi,j)
以上是单头注意力公式,如果考虑多头注意力 (multi-head attention) ,可以将多个注意力计算的结果联结 (concat) 组成一个嵌入向量,也可以计算多个注意力结果的平均值。联结计算方式为
x
i
′
=
∥
k
=
1
K
(
α
i
,
i
W
k
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
W
k
x
j
)
\mathbf x_i' = \Vert_{k=1}^K \left( \alpha_{i,i}\mathbf{W}^k \mathbf{x}_{i} + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j}\mathbf{W}^k \mathbf{x}_{j} \right)
xi′=∥k=1K⎝⎛αi,iWkxi+j∈N(i)∑αi,jWkxj⎠⎞
平均计算方式为
x
i
′
=
1
K
∑
k
=
1
K
(
α
i
,
i
W
k
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
W
k
x
j
)
\mathbf x_i' = \frac {1}{K} \sum_{k=1}^K \left( \alpha_{i,i}\mathbf{W}^k \mathbf{x}_{i} + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j}\mathbf{W}^k \mathbf{x}_{j} \right)
xi′=K1k=1∑K⎝⎛αi,iWkxi+j∈N(i)∑αi,jWkxj⎠⎞
GAT 消息传递的过程可以用论文中的 Figure 1 来说明
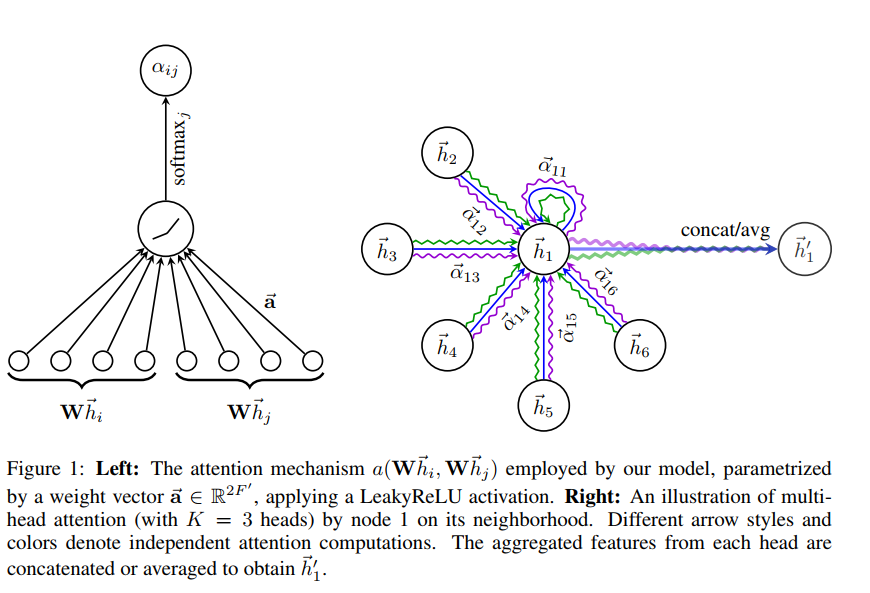
GAT 的优缺点
优点如下:
- 注意力计算只涉及到中心节点及其邻域节点,很容易实现并行计算
- 因为只关心图结构中的局部注意力,所以能够将训练的模型应用到陌生的图数据中,并不局限于训练数据中才有的图结构
缺点有
- 注意力只关注节点的局部特征,在获取全局特征上效果可能不佳(个人观点)
代码实现
此处的代码为 Pytorch-Geometric 中的 GATConv ,为了简单起见,我们不考虑二分图 (bipartite graphs)的情况。
class GATConv(MessagePassing):
def __init__(self, in_channels: Union[int, Tuple[int, int]],
out_channels: int, heads: int = 1, concat: bool = True,
negative_slope: float = 0.2, dropout: float = 0.0,
add_self_loops: bool = True, bias: bool = True, **kwargs):
kwargs.setdefault('aggr', 'add')
super(GATConv, self).__init__(node_dim=0, **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.negative_slope = negative_slope
self.dropout = dropout
self.add_self_loops = add_self_loops
# 节点特征变换需要的算子
self.lin_src = Linear(in_channels, heads * out_channels,
bias=False, weight_initializer='glorot')
self.lin_dst = self.lin_src
# 计算注意力需要的权重参数 W
self.att_src = Parameter(torch.Tensor(1, heads, out_channels))
self.att_dst = Parameter(torch.Tensor(1, heads, out_channels))
if bias and concat:
self.bias = Parameter(torch.Tensor(heads * out_channels))
elif bias and not concat:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self._alpha = None
self.reset_parameters()
def reset_parameters(self):
self.lin_src.reset_parameters()
self.lin_dst.reset_parameters()
glorot(self.att_src)
glorot(self.att_dst)
zeros(self.bias)
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None, return_attention_weights=None):
H, C = self.heads, self.out_channels
# 首先使用 torch 中的 Linear 对输入节点特征做变换,这里源节点和目标节点
# 变换计算的权重是共享的,如果输入时二分图,二者的权重就不同
assert x.dim() == 2, "Static graphs not supported in 'GATConv'"
x_src = x_dst = self.lin_src(x).view(-1, H, C)
x = (x_src, x_dst)
# 接下来计算节点级别的注意力系数,源节点和目标节点都需要计算
# 计算公式为 a^T @ x_i
alpha_src = (x_src * self.att_src).sum(dim=-1)
alpha_dst = None if x_dst is None else (x_dst * self.att_dst).sum(-1)
alpha = (alpha_src, alpha_dst)
if self.add_self_loops:
if isinstance(edge_index, Tensor):
# We only want to add self-loops for nodes that appear both as
# source and target nodes:
num_nodes = x_src.size(0)
if x_dst is not None:
num_nodes = min(num_nodes, x_dst.size(0))
num_nodes = min(size) if size is not None else num_nodes
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes)
elif isinstance(edge_index, SparseTensor):
edge_index = set_diag(edge_index)
# propagate_type: (x: OptPairTensor, alpha: OptPairTensor)
out = self.propagate(edge_index, x=x, alpha=alpha, size=size)
alpha = self._alpha
assert alpha is not None
self._alpha = None
if self.concat:
out = out.view(-1, self.heads * self.out_channels)
else:
out = out.mean(dim=1)
if self.bias is not None:
out += self.bias
if isinstance(return_attention_weights, bool):
if isinstance(edge_index, Tensor):
return out, (edge_index, alpha)
elif isinstance(edge_index, SparseTensor):
return out, edge_index.set_value(alpha, layout='coo')
else:
return out
def message(self, x_j: Tensor, alpha_j: Tensor, alpha_i: OptTensor,
index: Tensor, ptr: OptTensor,
size_i: Optional[int]) -> Tensor:
# 在 message 之前,MassagePassing 通过 __collect__ 函数计算 message 需要的
# 参数。这里 propagate 的输入参数为节点特征 x(类型为 Tuple), 节点注意力系数
# alpha (类型为 Tuple) 以及节点数量,经过 __collect__ 过后,x_j=x[0],
# alpha_j = alpha[0], alpha_i = alpha[1]
alpha = alpha_j if alpha_i is None else alpha_j + alpha_i
alpha = F.leaky_relu(alpha, self.negative_slope)
alpha = softmax(alpha, index, ptr, size_i)
self._alpha = alpha # Save for later use.
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
return x_j * alpha.unsqueeze(-1)
def __repr__(self):
return '{}({}, {}, heads={})'.format(self.__class__.__name__,
self.in_channels,
self.out_channels, self.heads)
注意到代码中
a
⊤
[
W
x
i
∥
W
x
j
]
\mathbf{a}^{\top} [\mathbf{W}\mathbf{x}_i \, \Vert \, \mathbf{W}\mathbf{x}_j]
a⊤[Wxi∥Wxj] 的计算并不是按照公式直译为代码,实际计算过程为
a
s
r
c
T
(
W
x
j
)
+
a
d
s
t
T
(
W
x
i
)
\mathbf a_{src}^T (\mathbf W \mathbf x_j) + \mathbf a_{dst}^T (\mathbf W \mathbf x_i)
asrcT(Wxj)+adstT(Wxi)
这样做我觉得是为了适应 MassagePassing 结构,需要的内存也小一点。
GATv2 Conv
GATv2 Conv 是对 GAT 的改进,原始论文为 How Attentive are Graph Attention Networks. 相对于 GAT, GATv2 只是修改的注意力中线性变换 Linear 的计算顺序,并引入了静态注意力 (Static attention ) 和动态注意力 (Dynamic attention). 具体计算公式如下
x
i
′
=
α
i
,
i
W
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
W
x
j
,
\mathbf{x}^{\prime}_i = \alpha_{i,i}\mathbf{W}\mathbf{x}_{i} + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j}\mathbf{W}\mathbf{x}_{j},
xi′=αi,iWxi+j∈N(i)∑αi,jWxj,
注意力
α
i
,
j
\alpha_{i,j}
αi,j 为
α
i
,
j
=
exp
(
a
⊤
L
e
a
k
y
R
e
L
U
(
W
[
x
i
∥
x
j
]
)
)
∑
k
∈
N
(
i
)
∪
{
i
}
exp
(
a
⊤
L
e
a
k
y
R
e
L
U
(
W
[
x
i
∥
x
k
]
)
)
.
\alpha_{i,j} = \frac{ \exp\left(\mathbf{a}^{\top}\mathrm{LeakyReLU}\left(\mathbf{W} [\mathbf{x}_i \, \Vert \, \mathbf{x}_j] \right)\right)} {\sum_{k \in \mathcal{N}(i) \cup \{ i \}} \exp\left(\mathbf{a}^{\top}\mathrm{LeakyReLU}\left(\mathbf{W} [\mathbf{x}_i \, \Vert \, \mathbf{x}_k] \right)\right)}.
αi,j=∑k∈N(i)∪{i}exp(a⊤LeakyReLU(W[xi∥xk]))exp(a⊤LeakyReLU(W[xi∥xj])).
对比 GAT,只是改变了
a
T
\mathbf a^T
aT ,
L
e
a
k
y
R
e
L
U
\mathrm{LeakyReLU}
LeakyReLU ,
L
i
n
e
a
r
\mathrm{Linear}
Linear 的计算顺序,不过实际效果见仁见智。
Transformer Conv
Transformer conv 基本原理
Transformer conv 是来自百度的论文 Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification ,该论文使用了类似于 Transformer 的方式计算节点注意力。
对于每一条从节点
j
j
j 指向节点
i
i
i 的边,我们需要计算 query, key, value,具体计算公式如下
q
c
,
i
=
W
c
,
q
x
i
+
b
c
,
q
k
c
,
j
=
W
c
,
k
x
j
+
b
c
,
k
e
c
,
i
j
=
W
c
,
e
e
i
j
+
b
c
,
e
α
c
,
i
j
=
⟨
q
c
,
i
,
k
c
,
j
+
e
c
,
i
j
⟩
∑
u
∈
N
(
i
)
⟨
q
c
,
i
,
k
c
,
u
+
e
c
,
i
u
⟩
q_{c, i} = W_{c, q} x_i + b_{c,q} \\ k_{c, j} = W_{c, k} x_j + b_{c, k} \\ e_{c, ij} = W_{c, e} e_{ij} + b_{c, e} \\ \alpha_{c, ij} = \frac {\left \langle q_{c,i}, k_{c,j} + e_{c, ij} \right \rangle} {\sum_{u \in \mathcal {N}(i)} \left \langle q_{c,i}, k_{c,u} + e_{c, iu} \right \rangle}
qc,i=Wc,qxi+bc,qkc,j=Wc,kxj+bc,kec,ij=Wc,eeij+bc,eαc,ij=∑u∈N(i)⟨qc,i,kc,u+ec,iu⟩⟨qc,i,kc,j+ec,ij⟩
其中
-
q, k 分别是 query 和 key 向量
-
e i j e_{ij} eij 表示边的特征,例如节点的相对位置坐标等
-
⟨ q , k ⟩ = exp ( q T k d ) \langle q, k \rangle = \exp(\frac{q^Tk}{\sqrt d}) ⟨q,k⟩=exp(dqTk), 与 Transformer 中一样是计算 query 和 key 之间的点积注意力
写成矩阵形式就是
x
i
′
=
W
1
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
W
2
x
j
,
\mathbf{x}^{\prime}_i = \mathbf{W}_1 \mathbf{x}_i + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j} \mathbf{W}_2 \mathbf{x}_{j},
xi′=W1xi+j∈N(i)∑αi,jW2xj,
注意力为
α
i
,
j
=
softmax
(
(
W
3
x
i
)
⊤
(
W
4
x
j
)
d
)
\alpha_{i,j} = \textrm{softmax} \left( \frac{(\mathbf{W}_3\mathbf{x}_i)^{\top} (\mathbf{W}_4\mathbf{x}_j)} {\sqrt{d}} \right)
αi,j=softmax(d(W3xi)⊤(W4xj))
如果考虑边的特征
x
i
′
=
W
1
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
(
W
2
x
j
+
W
6
e
i
j
)
α
i
,
j
=
softmax
(
(
W
3
x
i
)
⊤
(
W
4
x
j
+
W
6
e
i
j
)
d
)
\mathbf{x}^{\prime}_i = \mathbf{W}_1 \mathbf{x}_i + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j} \left( \mathbf{W}_2 \mathbf{x}_{j} + \mathbf{W}_6 \mathbf{e}_{ij} \right) \\ \alpha_{i,j} = \textrm{softmax} \left( \frac{(\mathbf{W}_3\mathbf{x}_i)^{\top} (\mathbf{W}_4\mathbf{x}_j + \mathbf{W}_6 \mathbf{e}_{ij})} {\sqrt{d}} \right)
xi′=W1xi+j∈N(i)∑αi,j(W2xj+W6eij)αi,j=softmax(d(W3xi)⊤(W4xj+W6eij))
如果是多头注意力,仍然可以采用 GAT 中的联结 (concat) 和平均 (mean) 两种方式将多头注意的结果变换为一个节点特征向量。
除此之外,论文中还增加了一个门控单元来计算残差的权重,以避免过平滑问题 (over smoothing).
x
i
′
=
W
1
x
i
+
∑
j
∈
N
(
i
)
α
i
,
j
(
W
2
x
j
+
W
6
e
i
j
)
α
i
,
j
=
softmax
(
(
W
3
x
i
)
⊤
(
W
4
x
j
+
W
6
e
i
j
)
d
)
\mathbf{x}^{\prime}_i = \mathbf{W}_1 \mathbf{x}_i + \sum_{j \in \mathcal{N}(i)} \alpha_{i,j} \left( \mathbf{W}_2 \mathbf{x}_{j} + \mathbf{W}_6 \mathbf{e}_{ij} \right) \\ \alpha_{i,j} = \textrm{softmax} \left( \frac{(\mathbf{W}_3\mathbf{x}_i)^{\top} (\mathbf{W}_4\mathbf{x}_j + \mathbf{W}_6 \mathbf{e}_{ij})} {\sqrt{d}} \right)
xi′=W1xi+j∈N(i)∑αi,j(W2xj+W6eij)αi,j=softmax(d(W3xi)⊤(W4xj+W6eij))
论文中 Transformer Conv 的网络结构如下
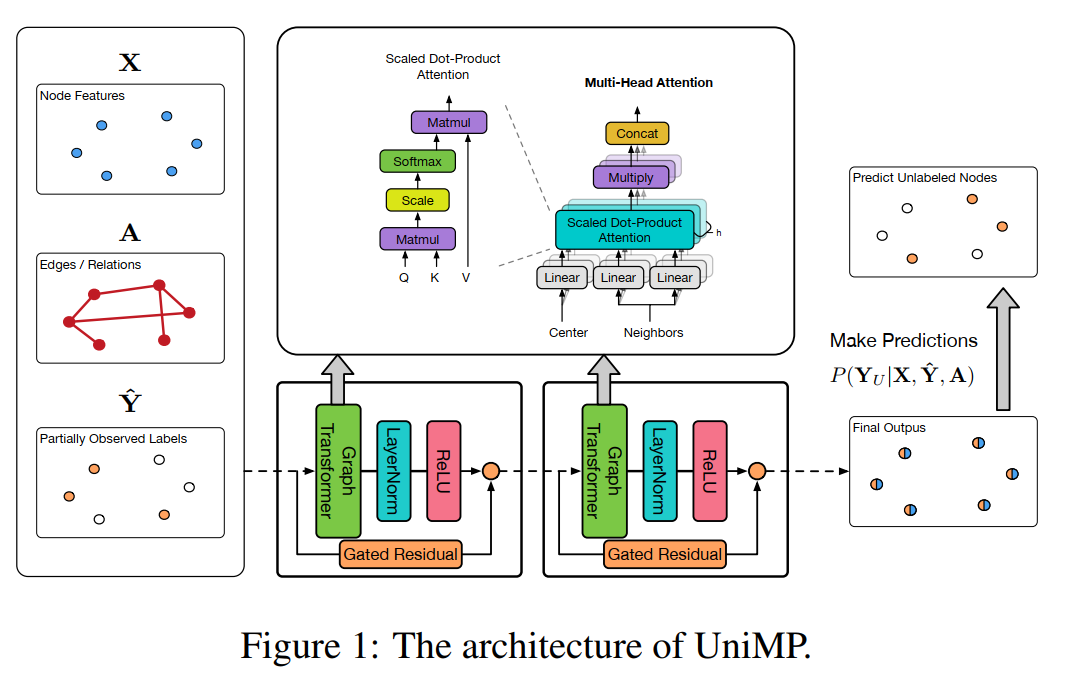
Transformer Conv 代码实现
代码为 PyG 中 TransformerConv 的实现,最好结合 PyG 文档阅读
class TransformerConv(MessagePassing):
def __init__(
self,
in_channels: Union[int, Tuple[int, int]],
out_channels: int,
heads: int = 1,
concat: bool = True,
beta: bool = False,
dropout: float = 0.,
edge_dim: Optional[int] = None,
bias: bool = True,
root_weight: bool = True,
**kwargs,
):
kwargs.setdefault('aggr', 'add')
super(TransformerConv, self).__init__(node_dim=0, **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.beta = beta and root_weight
self.root_weight = root_weight
self.concat = concat
self.dropout = dropout
self.edge_dim = edge_dim
if isinstance(in_channels, int):
in_channels = (in_channels, in_channels)
# query, key, value 的变换算子,使用 Linear 完成
self.lin_key = Linear(in_channels[0], heads * out_channels)
self.lin_query = Linear(in_channels[1], heads * out_channels)
self.lin_value = Linear(in_channels[0], heads * out_channels)
# edge feature 的变换算子,在实际计算中 edge feature 可以是节点相对位置,
# 或者其他能够表示节点相对信息的特征
if edge_dim is not None:
self.lin_edge = Linear(edge_dim, heads * out_channels, bias=False)
else:
self.lin_edge = self.register_parameter('lin_edge', None)
# 使用 cancat 方式组合多头注意的结果,需要计算的变量有
# 残差连接 (skip), skip 的门控权重 beta
if concat:
self.lin_skip = Linear(in_channels[1], heads * out_channels,
bias=bias)
if self.beta:
self.lin_beta = Linear(3 * heads * out_channels, 1, bias=False)
else:
self.lin_beta = self.register_parameter('lin_beta', None)
else:
self.lin_skip = Linear(in_channels[1], out_channels, bias=bias)
if self.beta:
self.lin_beta = Linear(3 * out_channels, 1, bias=False)
else:
self.lin_beta = self.register_parameter('lin_beta', None)
self.reset_parameters()
def reset_parameters(self):
self.lin_key.reset_parameters()
self.lin_query.reset_parameters()
self.lin_value.reset_parameters()
if self.edge_dim:
self.lin_edge.reset_parameters()
self.lin_skip.reset_parameters()
if self.beta:
self.lin_beta.reset_parameters()
def forward(self, x: Union[Tensor, PairTensor], edge_index: Adj,
edge_attr: OptTensor = None, return_attention_weights=None):
# edge_attr 为每一条边的特征
if isinstance(x, Tensor):
x: PairTensor = (x, x)
# propagate_type: (x: PairTensor, edge_attr: OptTensor)
out = self.propagate(edge_index, x=x, edge_attr=edge_attr, size=None)
alpha = self._alpha
self._alpha = None
if self.concat:
out = out.view(-1, self.heads * self.out_channels)
else:
out = out.mean(dim=1)
# 计算中心节点特征,一般推荐使用 root_weight=True
# 是否使用门控计算 beta,看需求
# 对应的公式为 x_i' = W_1 * x_i + \sum message_j 或者
# x_i' = \beta_i W_1 * x_i + (1 - \beta_i) (\sum message_j)
if self.root_weight:
x_r = self.lin_skip(x[1])
if self.lin_beta is not None:
beta = self.lin_beta(torch.cat([out, x_r, out - x_r], dim=-1))
beta = beta.sigmoid()
out = beta * x_r + (1 - beta) * out
else:
out += x_r
if isinstance(return_attention_weights, bool):
assert alpha is not None
if isinstance(edge_index, Tensor):
return out, (edge_index, alpha)
elif isinstance(edge_index, SparseTensor):
return out, edge_index.set_value(alpha, layout='coo')
else:
return out
def message(self, x_i: Tensor, x_j: Tensor, edge_attr: OptTensor,
index: Tensor, ptr: OptTensor,
size_i: Optional[int]) -> Tensor:
# 计算 query, key
# query = W_3 * x_i
# key = W_4 * x_j
query = self.lin_query(x_i).view(-1, self.heads, self.out_channels)
key = self.lin_key(x_j).view(-1, self.heads, self.out_channels)
# 计算边的特征
# edge_feat = W_6 * edge_attr
# key = key + edge_feat
if self.lin_edge is not None:
assert edge_attr is not None
edge_attr = self.lin_edge(edge_attr).view(-1, self.heads,
self.out_channels)
key += edge_attr
# 计算 query 和 key 的点积注意力
alpha = (query * key).sum(dim=-1) / math.sqrt(self.out_channels)
alpha = softmax(alpha, index, ptr, size_i)
self._alpha = alpha
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
# 计算边的消息,out = (message + edge_attr) * alpha_{ij}
out = self.lin_value(x_j).view(-1, self.heads, self.out_channels)
if edge_attr is not None:
out += edge_attr
out *= alpha.view(-1, self.heads, 1)
return out
def __repr__(self):
return '{}({}, {}, heads={})'.format(self.__class__.__name__,
self.in_channels,
self.out_channels, self.heads)

















 9832
9832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









