







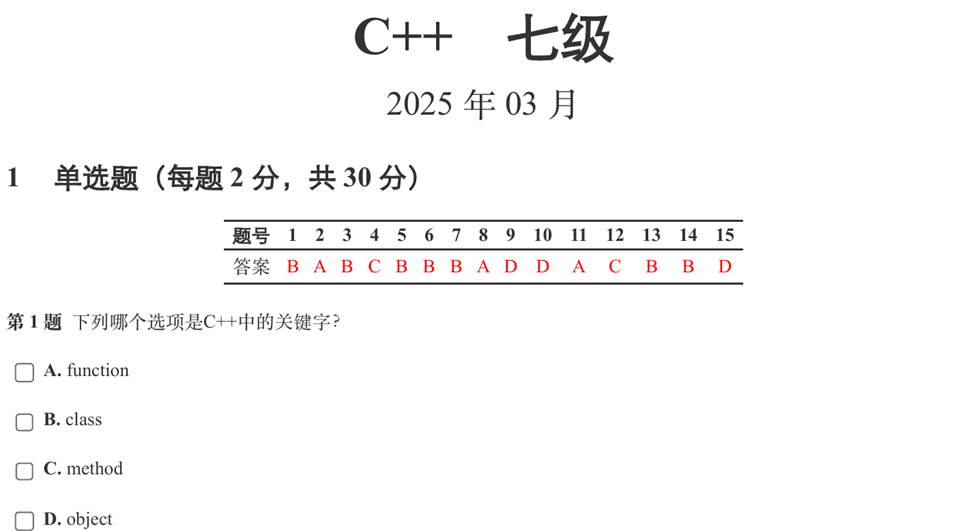
答案:B
解析:function、method、object是其他语言体系的关键字,但不是C++的关键字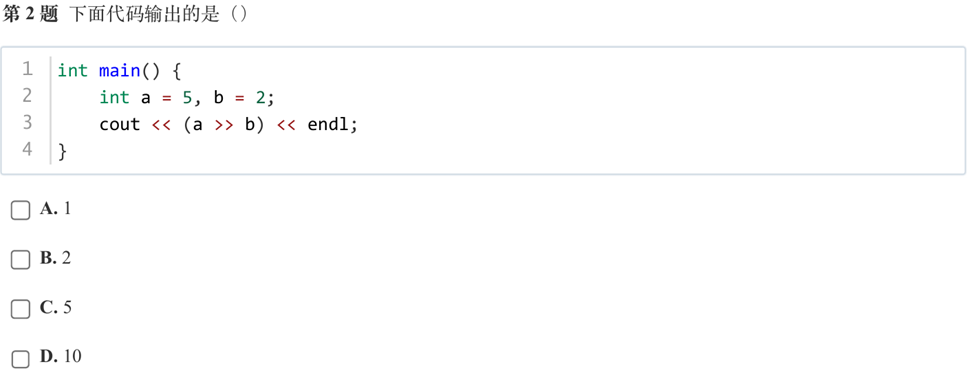
答案:A
解析:5(10)=101(2),右移两位,得1
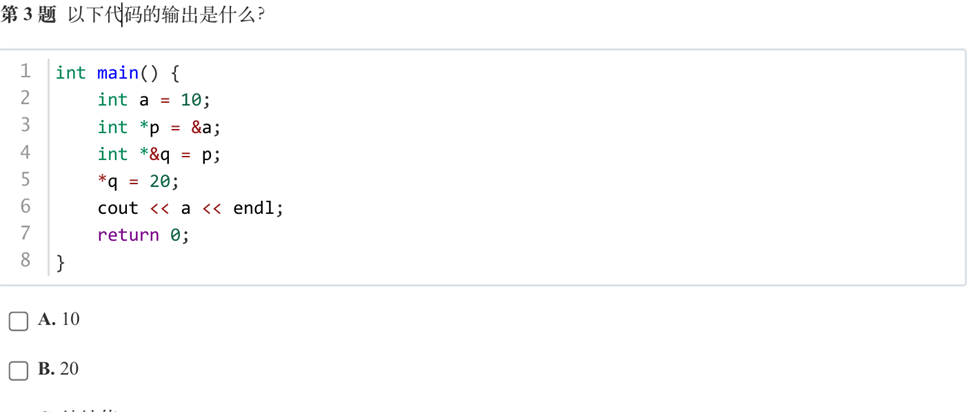
![]()
答案:B
解析:int *&q = p;表示q 是 p 的引用(别名),即 q 和 p 是完全相同的指针,指向同一个地址(&a)。这里与int *q = p;等效。

答案:C
解析:arr=&arr[0],*(arr+2)=arr[2],所以*p=arr[2]

答案:B
解析:A,选择排序的平均时间复杂度是O(n2)。B,归并排序是稳定的。C,快速排序最差的复杂度为O(nlogn)。D,插入排序最好情况是O(n),即已排序的状态。

答案:B
解析:析构函数可以为正常函数

答案:B
解析:在图论中,强连通图是指:
- 有向图(Directed Graph) 中,任意两个顶点 uu 和 vv 之间均存在双向路径,即:
- 从 u到 v 的有向路径;
- 从 v到 u的有向路径。
- 如果图是 无向图(Undirected Graph),则直接称为 连通图(Connected Graph)(因为无向边天然双向可达)。
如果把树看做有向图,每个节点指向其⼦节点,则此时不存在环,不可能是强连通的。

for(int i=0;i<s.length();i++){
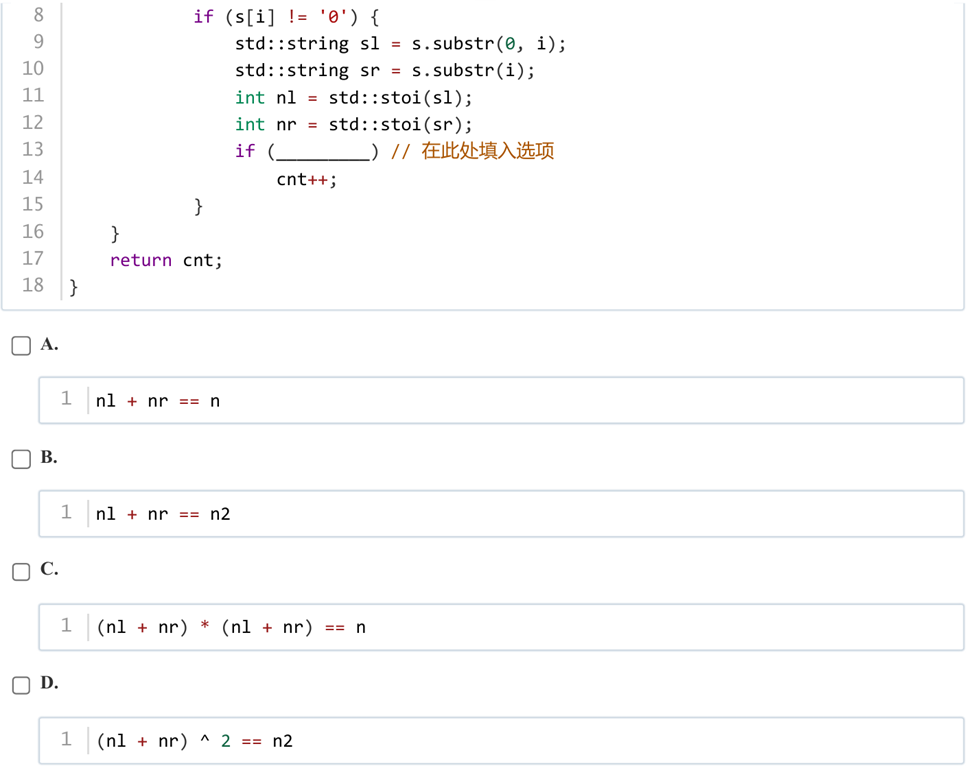
答案:A
解析:比如n=45,45*45=2025,此时只要判断2025里的某个切割的和为45。

}
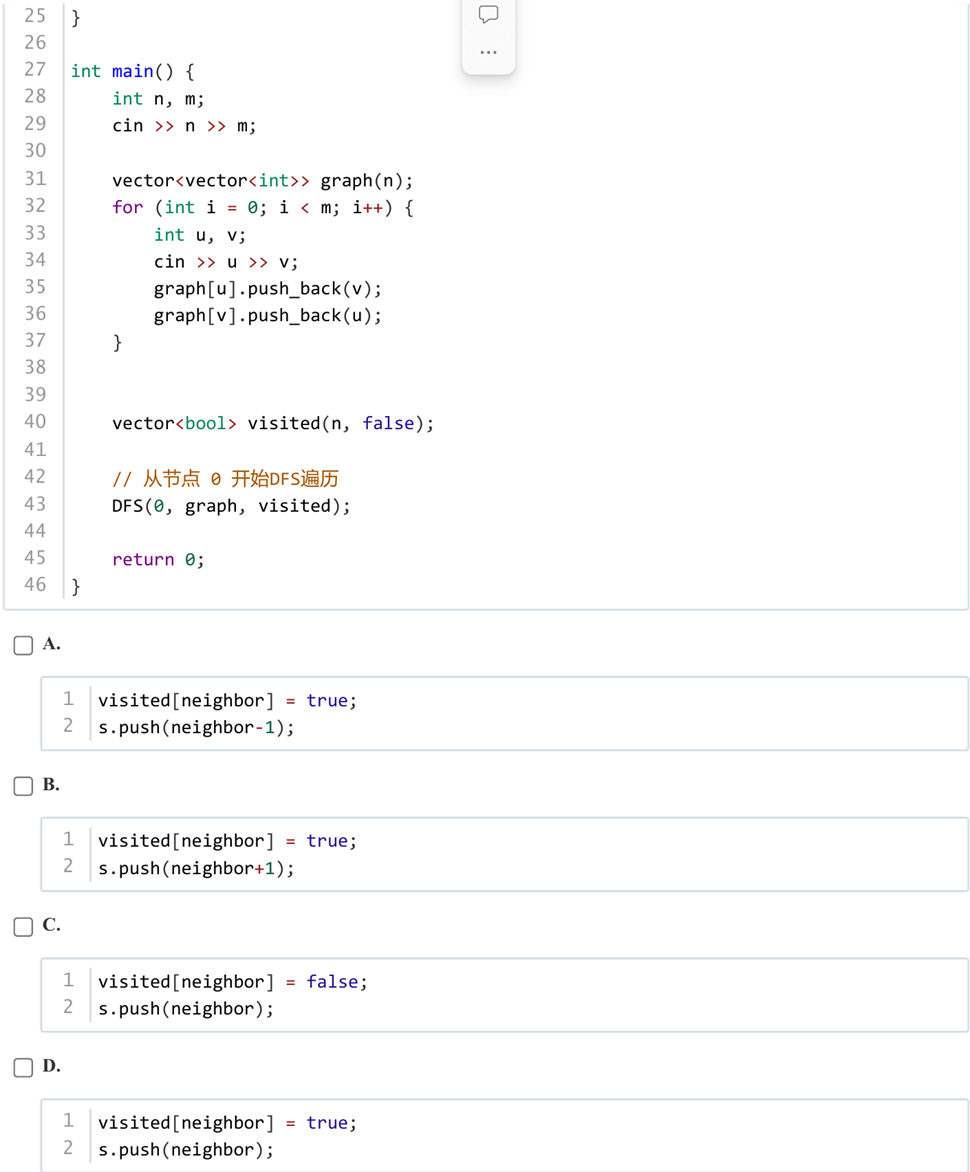
答案:D
解析:一目了然,首先肯定visited[neighbor] = true;,然后-1,+1肯定不对,选D

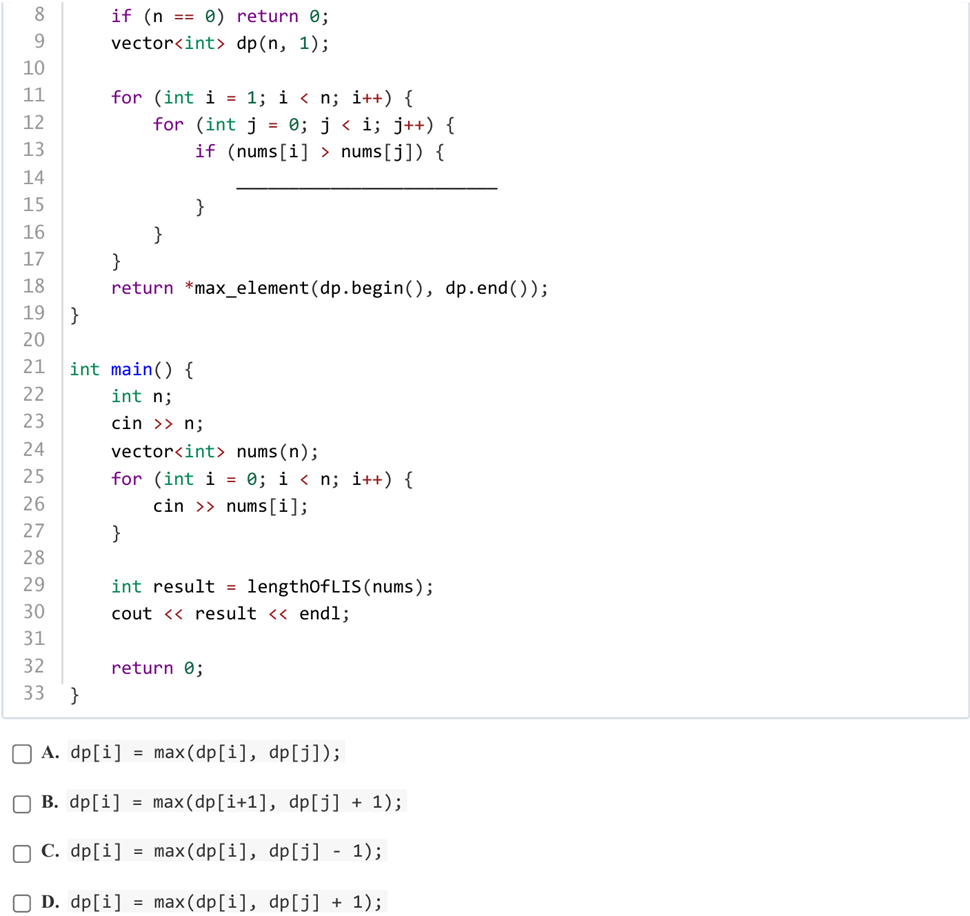
答案:D
解析:一目了然,最长上升子序列,取比当前元素小的数的上升序列长度+1
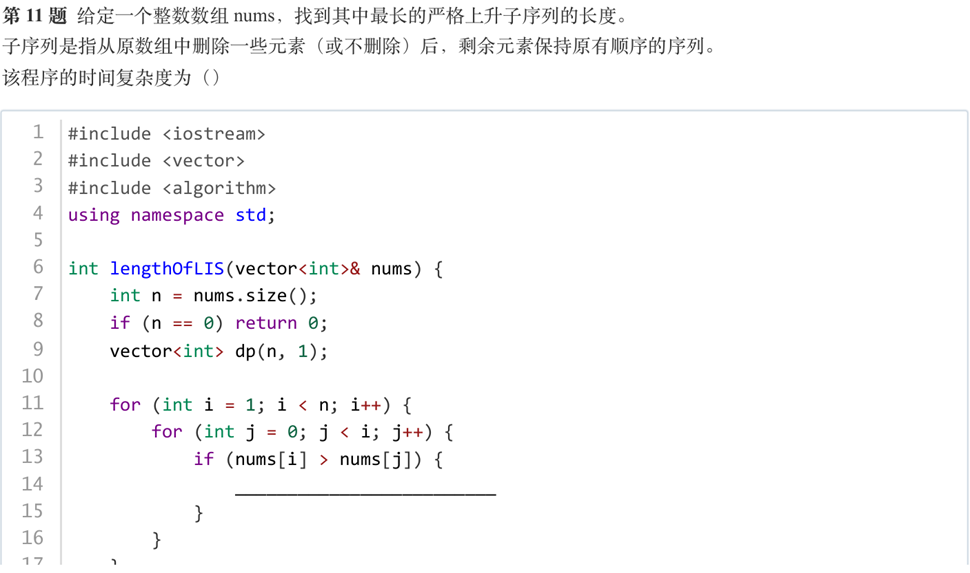
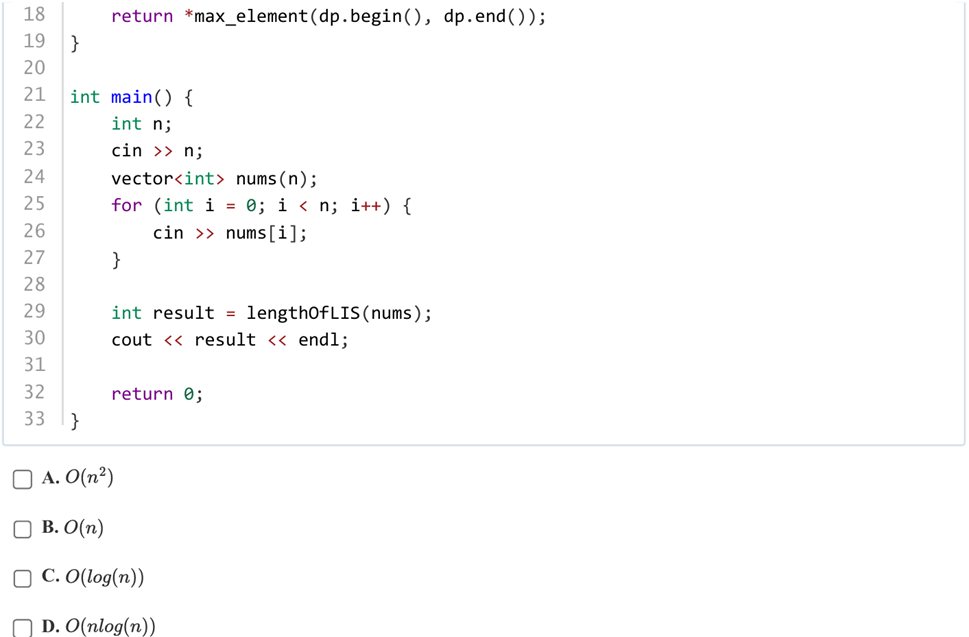
答案:A
解析:一目了然

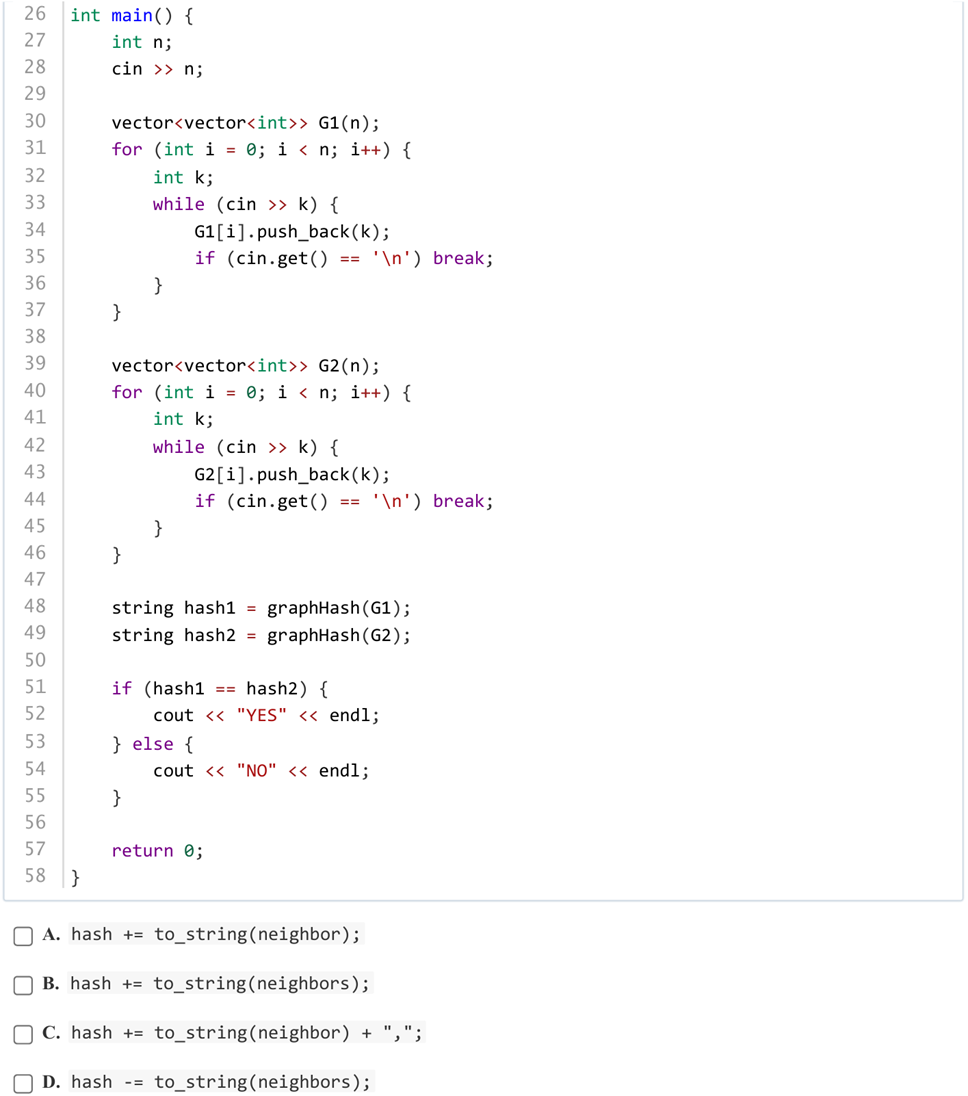
答案:C
解析:通过将领接表转换为string的hash表来比较两个图是否一致。D肯定不对,B也不对,应该是累加每个节点,而不是加数组。A这种处理可能造成歧义,比如1,11和11,1最后的hash值一样,但顺序是不一样的。所以选C。

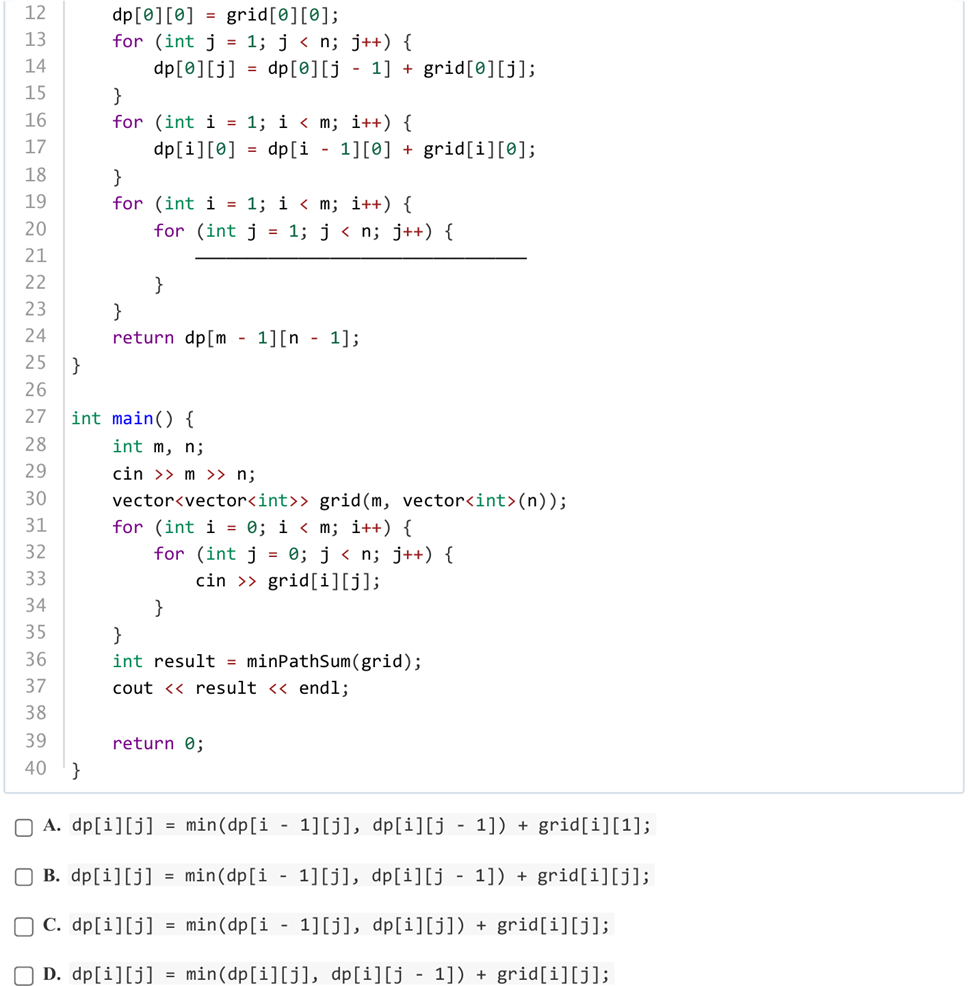
答案:B
解析:选择左边和上边的最小值后加上自身,即为到达当前节点的最小值
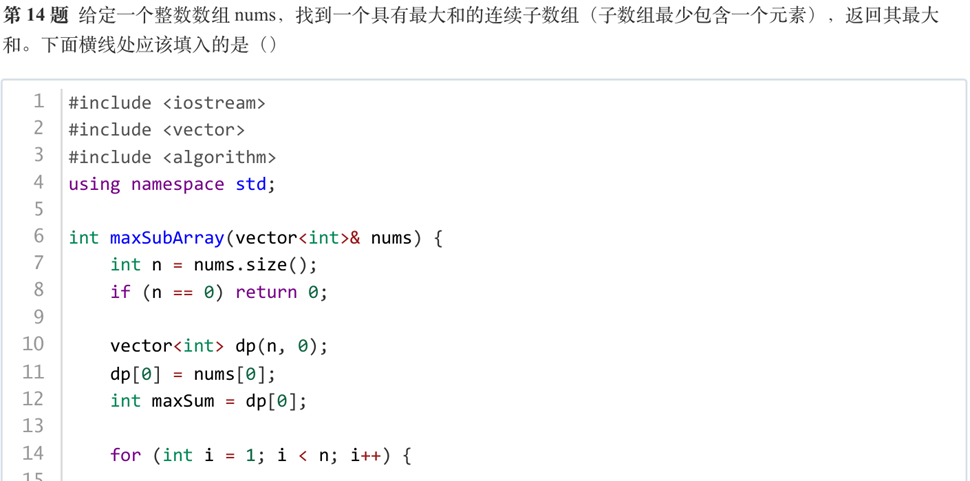
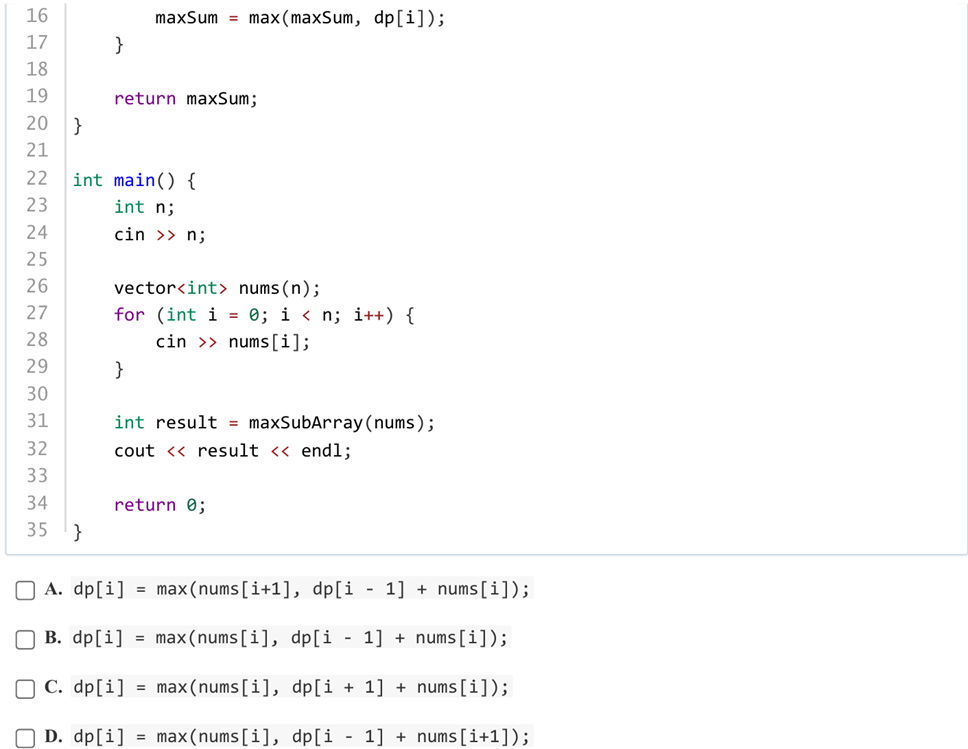
答案:B
解析:因为可能存在负数,如果前面的最大和大于0,那当前最大和就是加上自己,如果前面的最大和小于0,就是自己。

答案:D
解析:
| 策略 | 优点 | 缺点 | 适用场景 |
| 开放地址--线性探测 | 实现简单,缓存友好 | 易聚集,效率随负载上升而下降 | 内存紧凑的嵌入式系统 |
| 开放地址--平方探测 | 减少聚集 | 可能探测失败 | 中等负载的通用场景 |
| 双重哈希 | 冲突分布均匀 | 计算成本高 | 高性能哈希表 |
| 链地址法 | 负载容忍度高 | 链表过长时查询慢 | 高负载或动态数据 |
| Cuckoo Hashing | 最坏 O(1) 查询 | 插入复杂,可能失败 | 对查询延迟敏感的系统 |

答案:F
解析:^在C++中表示异或
![]()
答案:T
解析:如题所述
![]()
答案:T
解析:如题所述
![]()
答案:F
解析:
| 类型 | 位数(典型) | 表示范围 | 精度特点 |
| long long | 64-bit | -2⁶³ ~ 2⁶³-1(约 ±9.2×10¹⁸) | 精确表示所有整数 |
| double | 64-bit | ±1.7×10³⁰⁸(指数范围) | 精度有限(53位有效位) |
![]()
答案:F
解析:cos(60) 的 结果类型确实是 double,但 值不是 0.5,因为 C/C++ 的三角函数默认使用弧度制而非角度制。cos(60)≈−0.952(非 0.5!)
![]()
答案:T
解析:如题所述
![]()
答案:T
解析:如题所述
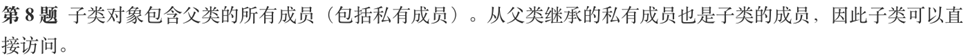
答案:F
解析:子类对象不能访问父类的私有成员

答案:T
解析:如题所述

答案:F
解析:只有在所有祖先的父母信息均已知且唯一的情况下成立。

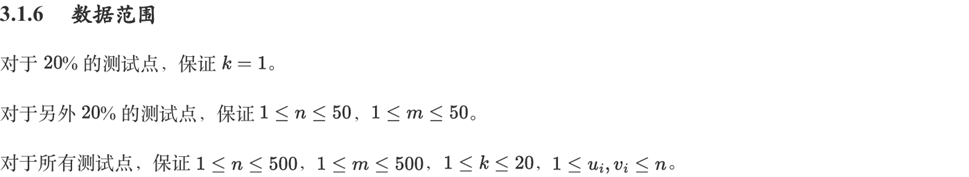
参考程序
//图上移动
#include <cstdio>
using namespace std;
const int K = 25;
const int N = 505;
const int E = N << 1;
int n, m, k;
int h[N], to[E], nx[E], et;
int f[K][N][N];
void ae(int u, int v) { //邻接表
et++; //边数
to[et] = v; //边终点
nx[et] = h[u]; //节点u的领接表首加上et这条边
h[u] = et;
}
int main() {
scanf("%d%d%d", &n, &m, &k);
for (int i = 1; i <= m; i++) { //构建邻接表
int u, v;
scanf("%d%d", &u, &v);
ae(u, v);
ae(v, u);
}
for (int i = 1; i <= n; i++) //初始化
f[0][i][i] = 1; //每个节点一步都不走,可以到达自己
for (int t = 1; t <= k; t++)
for (int x = 1; x <= n; x++)
for (int y = 1; y <= n; y++)
if (f[t - 1][x][y]) //如果f[t-1][x][y]为真,说明x到y一步可以到达
for (int i = h[y]; i; i = nx[i])//遍历y的邻接表
f[t][x][to[i]] = 1;//第t步x可以y的邻接点
for (int i = 1; i <= n; i++) {
for (int t = 1; t <= k; t++) {
int ans = 0;
for (int j = 1; j <= n; j++)
ans += f[t][i][j]; //统计节点i移动t步可以到达的节点数
printf("%d%c", ans, " \n"[t == k]);
}
}
return 0;
}

官方答案已经是高度优化后的实现,但它的核心思想来源于经典的前缀异或和+哈希表统计算法。为了更清晰地理解其原始思路,我们可以从未优化的暴力解法出发,逐步推导出优化后的版本。
1. 原始问题
统计字符串中所有满足以下条件的子串数量:
子串中每个字符出现的次数均为偶数次。
例如:"abba" 中符合条件的子串是 "bb" 和 "abba"。
2. 未优化的暴力解法(原始算法)
直接枚举所有可能的子串,并检查每个子串是否满足条件:
#include <cstdio>
#include <cstring>
using namespace std;
const int N = 2e5 + 5;
int n;
char s[N];
bool is_even_count(int l, int r) {
int cnt[26] = {0};
for (int i = l; i <= r; i++) {
cnt[s[i] - 'a']++;
}
for (int i = 0; i < 26; i++) {
if (cnt[i] % 2 != 0) return false;
}
return true;
}
int main() {
scanf("%d", &n);
scanf("%s", s + 1);
long long ans = 0;
for (int l = 1; l <= n; l++) {
for (int r = l; r <= n; r++) {
if (is_even_count(l, r)) ans++;
}
}
printf("%lld\n", ans);
return 0;
}
问题:
- 时间复杂度:O(n3)(两层循环 + 检查26个字符的奇偶性),无法处理 n≥1000的数据。
3. 第一次优化:利用前缀和
观察到字符的奇偶性可以表示为二进制位,用异或运算(^)维护状态:
#include <cstdio>
using namespace std;
const int N = 2e5 + 5;
int n;
char s[N];
int prefix[N]; // prefix[i] 表示前i个字符的异或状态
int main() {
scanf("%d", &n);
scanf("%s", s + 1);
prefix[0] = 0;
for (int i = 1; i <= n; i++) {
prefix[i] = prefix[i-1] ^ (1 << (s[i] - 'a'));
}
long long ans = 0;
for (int l = 1; l <= n; l++) {
for (int r = l; r <= n; r++) {
if ((prefix[r] ^ prefix[l-1]) == 0) ans++;
}
}
printf("%lld\n", ans);
return 0;
}
优化点:
- 用 prefix[r] ^ prefix[l-1] 计算子串 [l, r] 的异或和,时间复杂度降为 O(n2)。
问题: - 仍无法处理 n≥105的数据。
4. 第二次优化:哈希表统计相同前缀异或和
利用哈希表记录前缀异或值的出现次数,避免双重循环:
#include <cstdio>
#include <map>
using namespace std;
const int N = 2e5 + 5;
int n;
char s[N];
map<int, int> m; // 记录前缀异或值的出现次数
int main() {
scanf("%d", &n);
scanf("%s", s + 1);
int v = 0; //表示从字符串开头到当前位置的字符出现次数的奇偶性(用二进制位表示)
m[v]++; // 初始状态(空子串),m[v]表示前缀异或和为v的字符串个数,即字母组合奇偶性为v的字符串个数
long long ans = 0;
for (int i = 1; i <= n; i++) {
v ^= (1 << (s[i] - 'a')); //当前字符的异或和,每一个v值表示一个字母组合的奇偶性,
//相同的v值表示相同的奇偶性和相同的字母组合
//下面两行是为了累计相同v值的组合个数
//如果相同v值的数量有n-1个,每增加一个,总的组合个数就增加n-1个
//证明:C(n,2)-C(n-1,2)=n-1,数学可证
ans += m[v];
m[v]++;
}
printf("%lld\n", ans);
return 0;
}
优化点:
- 时间复杂度:O(nlogn) map 的插入和查询操作)。
- 核心思想:
- 若 v[i] == v[j],则子串 [i+1, j] 的异或和为 0(即所有字符出现偶数次)。
- 哈希表直接统计相同 v 的出现次数,避免重复计算。
5. 最终优化:用数组替代哈希表(针对小字符集)
如果字符集较小(例如仅小写字母),可以用数组代替 map,将时间复杂度降至 O(n):
#include <cstdio>
#include <cstring>
using namespace std;
const int N = 2e5 + 5;
int n;
char s[N];
int m[1 << 26]; // 假设字符集为26个小写字母
int main() {
scanf("%d", &n);
scanf("%s", s + 1);
int v = 0;
m[v] = 1; // 初始状态
long long ans = 0;
for (int i = 1; i <= n; i++) {
v ^= (1 << (s[i] - 'a'));
ans += m[v];
m[v]++;
}
printf("%lld\n", ans);
return 0;
}
注意:
- 此版本仅适用于字符集较小的情况(如 1 << 26 的数组在大多数平台不可行,需根据实际调整)。
6. 原始算法与优化后的对比
| 版本 | 时间复杂度 | 核心思想 |
| 暴力解法 | O(n3) | 枚举所有子串并检查字符奇偶性。 |
| 前缀异或和优化 | O(n2) | 用异或前缀和快速计算子串异或和。 |
| 哈希表优化 | O(nlogn) | 哈希表记录前缀异或值,直接统计相同状态的子串数量。因为map的操作是O(nlogn) |
| 数组优化(小字符集) | O(n) | 用数组替代哈希表,适用于有限字符集。 |
学编程、玩信奥,微信搜“信奥莫老师”,或关注微信公众号“AI之上-信奥驿站”


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









