







上一篇:TensorFlow常用函数(三)
1、tf.logging.set_verbosity():设置显示哪些级别的日志信息
2、tf.nn.max_pool_with_argmax():带索引的最大池化,最大池化同时返回索引值
3、tf.scatter_nd():根据索引(indices)将给定的张量(updates)散布到新的(初始为零)形状为shape的张量
4、Unpool():反最大池化函数的封装,根据最大池化后的结果和最大池化索引值反最大池化
5、tf.nn.embedding_lookup():选取一个张量里面索引对应的元素
6、tf.nn.nce_loss():计算训练词向量过程中的NCE
1、tf.logging.set_verbosity():设置显示哪些级别的日志信息
TensorFlow使用五个不同级别的日志消息。 按照上升的顺序,它们是DEBUG,INFO,WARN,ERROR和FATAL。 当你在任何这些级别配置日志记录时,TensorFlow将输出与该级别相对应的所有日志消息以及所有级别的严重级别。 例如,如果设置了ERROR的日志记录级别,则会收到包含ERROR和FATAL消息的日志输出,如果设置了一个DEBUG级别,则会从所有五个级别获取日志消息。默认情况下,TENSFlow在WARN的日志记录级别进行配置,但是在跟踪模型训练时,您需要将级别调整为INFO,这将提供适合操作正在进行的其他反馈。
if __name__=='__main__':
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run()
2、tf.nn.max_pool_with_argmax():带索引的最大池化,最大池化同时返回索引值
函数原型:
tf.nn.max_pool_with_argmax(
input,
ksize,
strides,
padding,
Targmax=tf.int64,
name=None
)
参数:
input: 一个4-D的Tensor. 它的类型必须为: float32, float64, int32, uint8, int16, int8, int64, bfloat16, uint16, half, uint32, uint64.形状为[batch,height, width, channels].
ksize: 池化核,length >= 4.
strides: 池化的步长length >= 4.
padding: 填充方式,为 "SAME", "VALID".
Targmax: 可选的tf.DType 值类型为: tf.int32, tf.int64. Defaults to tf.int64.
name: 操作名(可选).
返回值:
Tensor对象元组(output, argmax).
output: 一个Tensor.与输入有相同的类型.
argmax: 一个Tensor与Targmax有相同的类型.实例如下:
inputs = tf.constant([4,5,2,3,0,1,6,7,12,13,10,11,8,9,14,15],dtype = tf.float32,shape = [1,4,4,1])
net, indices = tf.nn.max_pool_with_argmax(inputs,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
with tf.Session() as sess:
print(inputs.eval())
print (net.eval())
print(indices.eval())
输出:
[[[[ 4.] [ 5.] [ 2.] [ 3.]]
[[ 0.] [ 1.] [ 6.] [ 7.]]
[[12.] [13.] [10.] [11.]]
[[ 8.] [ 9.] [14.] [15.]]]]
[[[[ 5.] [ 7.]]
[[13.] [15.]]]]
[[[[ 1] [ 7]]
[[ 9] [15]]]]3、tf.scatter_nd():根据索引(indices)将给定的张量(updates)散布到新的(初始为零)形状为shape的张量
函数原型:
tf.scatter_nd(
indices,
updates,
shape,
name=None
)
函数参数:
indices:一个Tensor;必须是以下类型之一:int32,int64;指数张量。
updates:一个Tensor;分散到输出的更新。
shape:一个Tensor;必须与indices具有相同的类型;1-d;得到的张量的形状。
name:操作的名称(可选)。
函数返回值:
此函数将返回一个Tensor,它与updates有相同的类型;根据indices应用的一个新具有给定的形状和更新的张量。indices是一个整数张量,其中含有索引形成一个新的形状shape张量。indices的最后的维度可以是shape的最多的秩:
indices.shape[-1] <= shape.rank例如:

indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
scatter = tf.scatter_nd(indices, updates, shape)
with tf.Session() as sess:
print(sess.run(scatter))
结果:
[0, 11, 0, 10, 9, 0, 0, 12]4、Unpool():反最大池化函数的封装,根据最大池化后的结果和最大池化索引值反最大池化
def unpool(updates, mask, k_size=[1, 2, 2, 1], output_shape=None, scope=''):
'''Unpooling function based on the implementation by Panaetius at
https://github.com/tensorflow/tensorflow/issues/2169
https://github.com/yselivonchyk/Tensorflow_WhatWhereAutoencoder/blob/master/WhatWhereAutoencoder.py
Args:
- inputs: 池化后的结果,形状为 [batch_size, height, width, num_channels]
- mask: 最大池化索引,由tf.nn.max_pool_with_argmax()产生,它和inputs具有相同的形状。
- k_size: 反池化核的维度。
- output_shape:反池化后的输出形状
- scope : 操作名
Returns:
- 一个4D张量,与output_shape有相同的形状
'''
with tf.variable_scope(scope):
mask = tf.cast(mask, tf.int32)
input_shape = tf.shape(updates, out_type=tf.int32)
# 计算输出的形状
if output_shape is None:
output_shape = (input_shape[0], input_shape[1] * ksize[1], input_shape[2] * ksize[2], input_shape[3])
# 接下来为batch, height, width、channel计算各自的索引
one_like_mask = tf.ones_like(mask, dtype=tf.int32)
# batch的索引使用默认值,因为反池化不改变batch
batch_shape = tf.concat([[input_shape[0]], [1], [1], [1]], 0)
batch_range = tf.reshape(tf.range(output_shape[0], dtype=tf.int32), shape=batch_shape)
b = one_like_mask * batch_range
# 根据最大池化索引值计算输出张量中height的索引
y = mask // (output_shape[2] * output_shape[3])
# 根据最大池化索引值计算输出张量中width的索引
x = (mask // output_shape[3]) % output_shape[2]
# channel的索引也使用默认值,因为反池化不改变channel
feature_range = tf.range(output_shape[3], dtype=tf.int32)
f = one_like_mask * feature_range #
# 把batch、height、width、channel的索引串联到一起,并改变其形状再进行转置,
# 使得每个元素有4个坐标值,之后用scatter_nd()函数根据索引值将输入分发到输出的张量中,
# 每个元素根据4个坐标值在输出张量中找到其对应的位置,从而完成反池化过程
updates_size = tf.size(updates)
indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))
values = tf.reshape(updates, [updates_size])
ret = tf.scatter_nd(indices, values, output_shape)
return ret5、tf.nn.embedding_lookup():选取一个张量里面索引对应的元素
函数原型:
tf.nn.embedding_lookup(params, ids, partition_strategy='mod', name=None, validate_indices=True, max_norm=None)
参数:
params: 一个表示完整的词嵌入的tensor.
ids: 一个类型为int32或者int64的tensor,用于在params中查询.
partition_strategy: 指定分割方法的字符串,默认为'mod', 如果len(params) > 1,支持"div"和"mod" 两种方法。
name: 操作名(可选).
validate_indices: DEPRECATED.
max_norm: 如果不为None,每个词向量将被裁剪,如果它的二范数大于这个值。
实例:
a = [[0.1, 0.2, 0.3],
[1.1, 1.2, 1.3],
[2.1, 2.2, 2.3],
[3.1, 3.2, 3.3],
[4.1, 4.2, 4.3]]
a = np.asarray(a)
idx1 = tf.Variable([0, 2, 3, 1], tf.int32)
idx2 = tf.Variable([[0, 2, 3, 1], [4, 0, 2, 2]], tf.int32)
out1 = tf.nn.embedding_lookup(a, idx1)
out2 = tf.nn.embedding_lookup(a, idx2)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print ('a')
print (a)
print ('out1')
print (sess.run(out1))
print ('out2')
print (sess.run(out2))
输出:
a
[[0.1 0.2 0.3]
[1.1 1.2 1.3]
[2.1 2.2 2.3]
[3.1 3.2 3.3]
[4.1 4.2 4.3]]
out1
[[0.1 0.2 0.3]
[2.1 2.2 2.3]
[3.1 3.2 3.3]
[1.1 1.2 1.3]]
out2
[[[0.1 0.2 0.3]
[2.1 2.2 2.3]
[3.1 3.2 3.3]
[1.1 1.2 1.3]]
[[4.1 4.2 4.3]
[0.1 0.2 0.3]
[2.1 2.2 2.3]
[2.1 2.2 2.3]]]6、tf.nn.nce_loss():计算训练词向量过程中的NCE
(1)为什么要使用NCE作为损失而不使用softmax呢?
使用“标准”神经网络学习词向量存在一些问题。 这种方式下,当网络在学习在给定网络的输入的情况下预测下一个单词时,词向量同时被学习到。预测下一个单词就像预测一个类别一样。 也就是说,这样的网络只是一个“标准”的多分类器。 并且该网络必须具有与类别相同数量的输出神经元。 当类别是实际的单词时,神经元的数量是巨大的。“标准”神经网络通常使用交叉熵进行训练,该函数要求输出神经元的值表示概率 - 这意味着网络为每个类别计算的输出“得分”必须归一化,转换为 每个类别的实际概率。 该归一化步骤通过softmax函数实现。 当应用于巨大的输出层时,Softmax非常昂贵。
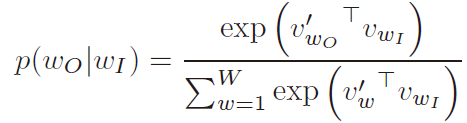
其中![]() 为输入的词向量,
为输入的词向量,![]() 为softmax的权重矩阵,
为softmax的权重矩阵,![]() 为权重矩阵的一行。
为权重矩阵的一行。
为了解决这个问题,即对softmax进行昂贵的计算,Word2Vec使用了一种称为噪声对比估计的技术。基本思想是转换多分类问题到二分类问题。也就是说,不使用softmax来估计输出单词的真实概率分布,而是使用逻辑回归(二元分类)来代替。对于每个训练样本,一个真正的对(一个中心词和出现在其上下文中的另一个词)和一些随机损坏的对(由中心词和随机选择的词组成) 词汇被输入到增强后分类器中,通过学习区分真实对与损坏对,分类器最终将学习到词向量。这很重要:增强的分类器不是预测下一个单词(“标准”训练技术),而是简单地预测一对单词是好还是坏。之前的问题是计算某个类的归一化概率是多少,二分类的问题是input和label正确匹配的概率是多少。
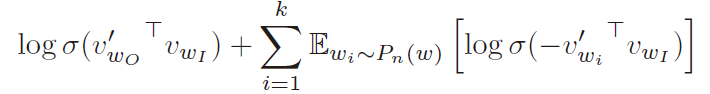
其中k为负样本的个数,而Sigmoid函数为:

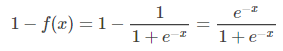
(2)NCE的TensorFlow实现
函数原型:
nce_loss(weights,
biases,
inputs,
labels,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss"):
'''
if mode == "train":
loss = tf.nn.nce_loss(
weights=weights,
biases=biases,
labels=labels,
inputs=inputs,
...,
partition_strategy="div")
elif mode == "eval":
logits = tf.matmul(inputs, tf.transpose(weights))
logits = tf.nn.bias_add(logits, biases)
labels_one_hot = tf.one_hot(labels, n_classes)
loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=labels_one_hot,
logits=logits)
loss = tf.reduce_sum(loss, axis=1)
Args:
weight.shape = (N, K),这里输入数据是K维的,一共有N个类
bias.shape = (N)
inputs.shape = (batch_size, K)
labels.shape = (batch_size, num_true)
num_sampled: 采样出多少个负样本。
num_classes: 总共有多少个类别,这里为词汇表单词个数
num_true : 实际的正样本个数。
sampled_values: 采样出的负样本,如果是None,就会用不同的sampler去采样。
remove_accidental_hits: 如果采样时不小心采样到的负样本刚好是正样本,要不要干掉。
partition_strategy:对weights进行embedding_lookup时并行查表时的策略。
Returns:
A `batch_size` 1-D tensor of per-example NCE losses.
'''
logits, labels = _compute_sampled_logits(
weights=weights, biases=biases, labels=labels, inputs=inputs,
num_sampled=num_sampled, num_classes=num_classes, num_true=num_true,
sampled_values=sampled_values, subtract_log_q=True,
remove_accidental_hits=remove_accidental_hits,
partition_strategy=partition_strategy, name=name)
sampled_losses = sigmoid_cross_entropy_with_logits(
labels=labels, logits=logits, name="sampled_losses")
return _sum_rows(sampled_losses)nce_loss的实现逻辑如下:
1) _compute_sampled_logits()负责采样,通过这个函数计算出正样本和采样出的负样本对应的output和label;
def _compute_sampled_logits(weights,
biases,
labels,
inputs,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
subtract_log_q=True,
remove_accidental_hits=False,
partition_strategy="mod",
name=None,
seed=None):
"""
Args:
weight.shape = (N, K),这里输入数据是K维的,一共有N个类
bias.shape = (N)
labels.shape = (batch_size, num_true)
inputs.shape = (batch_size, K)
num_sampled: 采样出多少个负样本。
num_classes: 总共有多少个类别,这里为词汇表单词个数
num_true : 实际的正样本个数。
sampled_values: 采样出的负样本,如果是None,就会用不同的sampler去采样。
remove_accidental_hits: 如果采样时不小心采样到的负样本刚好是正样本,要不要干掉。
partition_strategy:对weights进行embedding_lookup时并行查表时的策略。
name: 操作名(可选).
seed: 随机采样的种子,默认为None
Returns:
out_logits: 一个tensor对象,其形状为[batch_size, num_true + num_sampled], 用于传递给
nn.sigmoid_cross_entropy_with_logits (NCE) 或者
nn.softmax_cross_entropy_with_logits_v2(sampled softmax).
out_labels: 一个Tensor 对象,和out_logits有相同的形状。
""" _compute_sampled_logits()完成的是一个什么过程呢。就是对于每一个样本,计算出一个维度为[batch_size, num_true + num_sampled]的向量,向量的每个元素都同之前logits的每个元素的意义一样,是输出值。同时,返回一个维度为[batch_size, num_true + num_sampled]的向量labels。这个labels中只有一个元素为1。 其实,此时的out_logits中对应(label位置为0)的元素就是![]() ,对应label位置为1)的元素就是
,对应label位置为1)的元素就是![]() 。然后再传给sigmoid_cross_entropy_with_logitt().
。然后再传给sigmoid_cross_entropy_with_logitt().
2)sigmoid_cross_entropy_with_logits()负责做逻辑回归(logistic regression),然后计算交叉熵损失(cross entropy loss),通过 sigmoid cross entropy来计算output和label的loss,从而进行反向传播。这个函数把最后的问题转化为了num_sampled+num_real个两类分类问题,然后每个分类问题用了交叉熵的损失函数,也就是logistic regression常用的损失函数;
3)最后用_sum_rows()求和。















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









