






本文转自快手音视频技术。
”
双图层实例分割

物体的互相遮挡在日常生活中普遍存在,严重的遮挡易带来易混淆的遮挡边界及非连续自然的物体形状,从而导致当前已有的检测及分割等的算法性能大幅下降。本文通过将图像建模为两个重叠图层,为网络引入物体间的遮挡与被遮挡关系,从而提出了一个轻量级的能有效处理遮挡的实例分割算法。

文 / 轩飞
编辑 / 贞霓

论文地址| https://arxiv.org/pdf/2103.12340.pdf
论文代码|https://github.com/lkeab/BCNet
01
摘要
由于物体的真实轮廓和遮挡边界之间通常没有区别,对高度重叠的对象进行分割是非常具有挑战性的。与之前的自顶向下的实例分割方法不同,本文提出遮挡感知下的双图层实例分割网络BCNet,将图像中的感兴趣区域(Region of Interest,RoI)建模为两个重叠图层,其中顶部图层检测遮挡对象,而底图层推理被部分遮挡的目标物体。双图层结构的显式建模自然地将遮挡和被遮挡物体的边界解耦,并在Mask预测的同时考虑遮挡关系的相互影响。作者在具有不同主干和网络层选择的One-stage和Two-stage目标检测器上验证了双层解耦的效果,显著改善了现有图像实例分割模型在处理复杂遮挡物体的表现,并在COCO和KINS数据集上均取得总体性能的大幅提升。
02
背景
实例分割(Instance Segmentation)是图像及视频场景理解的基础任务,该任务将物体检测与语义分割有机结合,不仅需要预测出输入图像的每一个像素点是否属于物体,还需将不同的物体所包含的像素点区分开。目前,实例分割技术已经大规模地应用在短视频编辑、视频会议、医学影像、自动驾驶等领域中, 下图展示了在自动驾驶场景下其对周边车辆的位置感知:

自动驾驶 - 车辆识别与感知
03
问题
以Mask R-CNN为代表的实例分割方法通常遵循先检测再分割(Detect-then-segment)的范例,即先获取感兴趣目标检测框,然后对区域内的像素进行Mask预测,在COCO数据集取得了领先性能并在工业界得到广泛应用。我们注意到大多数后续改进算法如PANet、HTC、BlendMask、CenterMask等均着重于设计更好的网络骨干(Backbone)、高低层特征的融合机制或级联结构(Cascade Structure),而忽视了掩膜预测分支(Mask Regression Head)的作用。同时,如图1所示的重叠人群,大面积的实例分割错误都是由于同一感兴趣区域(RoI)中包含的重叠物体混淆了不同物体的真实轮廓,特别是当遮挡和被遮挡目标都属于相同类别或纹理颜色相似。

图1 高度遮挡下的实例分割结果对比
04
成果
近日,香港科技大学联合快手对图像实例分割当下性能瓶颈进行了深入剖析,该研究通过将图像中感兴趣区域(RoI)建模为两个重叠图层(如图2示),并提出遮挡感知下的双图层实例分割网络BCNet,顶层GCN层检测遮挡对象,底层GCN层推理被部分遮挡的目标物体,通过显式建模自然地将遮挡和被遮挡物体的边界解耦,并在mask预测的同时考虑遮挡关系的相互影响,显著改善了现有实例分割模型在处理复杂遮挡物体时的表现,在COCO和KINS数据集上均取得领先性能。

图2 遮挡物和被遮挡物的双图层分解示意简图
05
意义
物体互相遮挡在日常生活中普遍存在,严重的遮挡会带来易混淆的遮挡边界及非连续自然的物体形状,从而导致当前已有的检测及分割等的算法的性能大幅下降。该研究系统提出了一个轻量级且能有效处理遮挡的实例分割算法,在工业界也具有极大意义。随着短视频作为主要信息传播媒介不断渗透进日常生活,在实际的物体分割应用场景中,分割的准确性直接影响着用户的使用体验和产品观感。因此,如何将实例分割技术应用在复杂的日常应用场景并保持高精度,此项研究给出了一个合理、有效的解决方案。
BCNet的结构框架
整个分割系统分为两个部分,物体检测部分和物体分割部分,算法流程如下图:

图3 BCNet的网络结构
输入单张图像,使用基于Faster R-CNN或者FCOS的物体检测算法预测感兴趣目标区域(RoI)候选框坐标(x,y,w,h),采用Resnet-50/101及特征金字塔作为基础网络(backbone)获取整张输入图片的特征。
使用RoI Align算法根据物体检测框位置,在整张图片特征图内准确抠取感兴趣目标区域的特征子图,并将其作为双图卷积神经网络的输入用于最终的物体分割。
实例分割网络BCNet由级联状的双图层神经网络组成:
第一个图层对感兴趣目标区域内遮挡物体(Occluder)的形状和外观进行显式建模,该层图卷积网络包含四层,即卷积层(卷积核大小3x3)、图卷积层(Non-local Layer)以及末尾的两个卷积(卷积核大小3x3)。第一个图卷积网络输入感兴趣目标区域特征,输出感兴趣目标框中遮挡物体的边界和掩膜。
第二个图层结合第一个图卷积网络(用于对遮挡物体建模)已经提取的遮挡物体信息(包括遮挡物的Boundary和Mask),具体做法是将步骤2中得到的感兴趣目标区域特征与经过第一个图卷积网络中最后一层卷积后的特征3a相加,得到新的特征,并将其作为第二个图卷积网络(用于被遮挡物分割)的输入。第二个图卷积网络与第一个图卷积网络结构相同,构成级联网络关系。该操作将遮挡与被遮挡关系同时考虑进来,能有效地区分遮挡物与被遮挡物的相邻物体边界,最终输出目标区域被遮挡目标物体(Occludee)的分割结果。
为了减少模型的参数量,我们使用非局部算子(Non-local Operator)操作进行图卷积层的实现,具体实现位于结构图左上位置,包含三个卷积核大小为1x1的卷积层以及Softmax算子,其将图像空间中像素点根据对应特征向量的相似度有效关联起来,实现输入目标区域特征的重新聚合,能较好解决同一个物体的像素点在空间上被遮挡截断导致不连续的问题。
BCNet与其他经典网络结构对比
我们的提出的复杂遮挡下的图像分割算法,基于已有的双阶段分割模型,将传统的单个的全卷积(Fully Convolution)掩膜预测分支网络替换成由双图层级联构成的图神经网络(Graph Convolutional Network)模型,在感兴趣目标区域(RoI)中,前图层建模输出遮挡物体(Occluder)的位置和形状,后图层在前图层基础上最终输出相应的被遮挡物体(Occludee)的Mask,从而让实例分割算法在遮挡情况下仍然能够保持高运行速度和服务器端的高速度。如下是BCNet与其它经典网络结构设计对比图:

图4 分割网络结构设计对比
实验和对比
作者在三个数据集包括COCO、COCOA以及KINS上对算法进行了验证,大量的定量实验结果(表1和表2,包含Modal Segmentation和Amodal Segmentation)表明BCNet在不过度增加网络参数和预测耗时的基础上,结合现有的One-stage和Two-stage物体检测器上均能取得较大的性能提升,优于CenterMask、BlendMask以及多阶段Cascade的HTC等现有算法,尤其是对于存在遮挡的物体。同时,表3证明双图层结构在两个完全的全卷积网络(pure FCN)图层中依然有效。
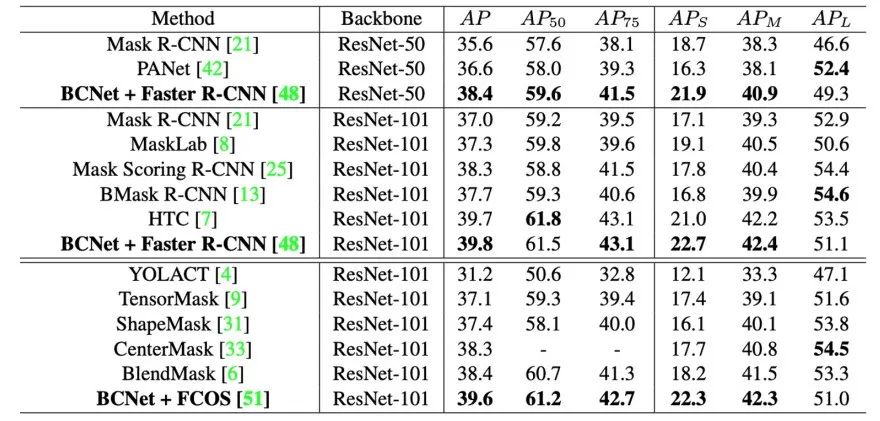
表1 在COCO-test-dev上的对比结果,
BCNet性能大幅优于BlendMask、CenterMask等网络

表2 在COCO-Val、COCOA和KINS数据集上的对比结果

表3 对双图层结构(bilayer structure)的有效性验证
另外,作者也提供了不同数据集下的可视化对比结果。对于COCO数据集,在图5和图6中可以看到即使在复杂的遮挡情况下,BCNet也能给出较为鲁棒的预测结果,而且通过分别可视化前图层和后图层对遮挡物和被遮挡物的Boundary和Mask的建模结果,使得BCNet的预测较以往算法具有更强的可解释性。图7和图8提供了对于Amodal Segmentation下的KINS和COCOA数据集的实例分割效果对比。

图5 基于FCOS检测器,COCO上CenterMask(第一行)和BCNet(第二行)的可视化结果对比。最下面一行显示了由两个GCN图层分别预测的遮挡物和被遮挡物的轮廓以及掩膜,从而使得BCNet的最终分割结果比以前的方法更具可解释性。

图6基于Faster R-CNN检测器,COCO上Mask Scoring R-CNN(第一行)和BCNet(第二行)的可视化结果对比

图7 KINS数据集上,ASN(第一行)和BCNet(第二行)的可视化结果(amodal)对比

图8 COCOA(左)及KINS(右)上的更多结果(amodal)对比
更多BCNet的实现和实验细节可参考论文和开源代码,图5到图8可视化部分基于的对比算法来源如下:
[1] Lee, Youngwan, and Jongyoul Park. "Centermask: Real-time anchor-free instance segmentation." In CVPR, 2020.
[2] Huang Z, Huang L, Gong Y, et al. Mask scoring r-cnn. In CVPR, 2019.
[3] Qi L, Jiang L, Liu S, et al. Amodal instance segmentation with kins dataset. In CVPR, 2019.
[4] Follmann, Patrick, et al. "Learning to see the invisible: End-to-end trainable amodal instance segmentation." In WACV, 2019.
”
欢迎加入

快手音视频技术团队由业界资深的专家组成,通过工程建设、算法优化,结合数据驱动、专业质量评测及产品化的手段为用户打造极致的体验。团队自2016年成立以来,已经建立起了业界领先的短视频+直播技术体系,支撑快手在国内、海外的数亿用户。
在这里你可以:
接触世界最前沿的音视频技术
在丰富的应用场景中大展身手
和行业里最优秀的同学们并肩作战
我们期待你的加入!请发送简历到:
video-hr@kuaishou.com
”
原文链接:CVPR系列(二)—— 双图层实例分割,大幅提升遮挡处理性能

备注:分割

图像分割交流群
语义分割、实例分割、全景分割、抠图等技术,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









