







 文章介绍了剑桥三星AI中心提出的X-ViT模型,该模型通过时空混合注意力机制降低了计算复杂度,同时保持了高精度的视频识别。X-ViT在时间维度上使用局部窗口和时间聚合,结合空间信息,实现了与图像Transformer相当的效率,且在多种视频识别数据集上表现出色。
文章介绍了剑桥三星AI中心提出的X-ViT模型,该模型通过时空混合注意力机制降低了计算复杂度,同时保持了高精度的视频识别。X-ViT在时间维度上使用局部窗口和时间聚合,结合空间信息,实现了与图像Transformer相当的效率,且在多种视频识别数据集上表现出色。
关注公众号,发现CV技术之美
▊ 写在前面
本文介绍了利用Transformer进行的视频识别问题。最近Transformer在视频识别领域的尝试在识别精度方面展现出了非常不错的结果,但在许多情况下,由于时间维度的额外建模,会导致显著的计算开销提升。
在这项工作中,作者提出了一个视频Transformer模型,该模型的复杂度与视频序列中的帧数呈线性的关系,因此与基于图像的Transformer模型相比,不会产生额外的计算开销。为了实现这一点,本文的视频Transformer对 full space-time attention进行了两个方面的近似:
a)它将时间注意力限制在一个局部时间窗口 ,并利用Transformer的深度来获得视频序列的全时间覆盖(这一点类似CNN中用小卷积核和深层结构获得全局空间建模的思想很像)。
b)它使用有效的时空混合来联合建模空间和时间信息 ,与仅空间注意模型相比没有产生任何额外的计算成本。作者通过实验证明了,本文的模型在视频识别数据集上产生了非常高的精度。
▊ 1. 论文和代码地址

Space-time Mixing Attention for Video Transformer
论文地址:https://arxiv.org/abs/2106.05968
代码地址:未开源
▊ 2. Motivation
视频识别任务指的是识别视频序列中感兴趣的事件,如人类活动的问题。随着Transformer在处理序列数据方面取得的巨大成功,特别是在自然语言处理(NLP)任务中,视觉Transformer最近被证明在图像识别方面也优于CNN。在此基础上,作者提出了一个视频Transformer模型来提高视频识别任务的准确性。
视觉Transformer在时空领域的一个直接的、自然的扩展是在所有的S个空间位置和T个时间位置上共同进行Self-Attention。但是全时空注意具有的复杂性,这使得模型计算起来很沉重,甚至比3D CNN的复杂度还要高。
因此,在本文中,作者的目标是在保留对视频流中存在的时间信息建模的同时,最小化Transformer框架内的计算负担,以实现有效的视频识别。
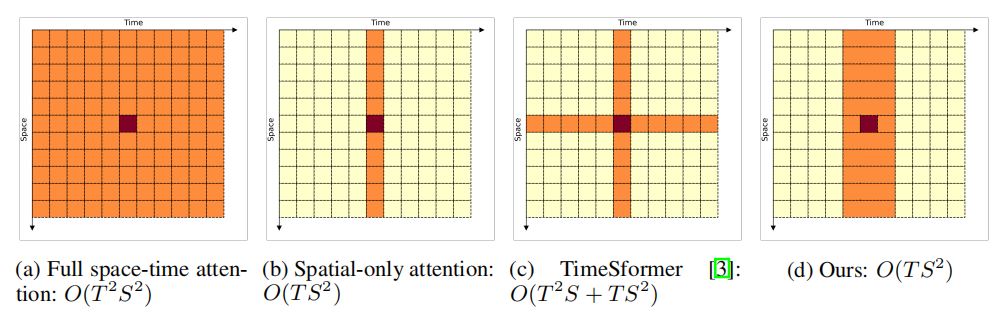
这个问题的一个基本解决方案是只考虑空间注意,然后在时间维度上平均,它具有的复杂度(上图(b))。还有一些方法(上图(c))在视频识别精度方面已经显示出了很不错的结果,但在大多数情况下,由于时间信息的额外建模,与baseline(仅空间建模)方法相比,它们还是会导致显著的计算开销。
本文的主要贡献是提出了一个具有复杂度的视频Transformer模型,因此,与baseline模型一样高效,它在效率(即精度/FLOP)方面显著优于最近提出的工作。为了实现这一点,本文的模型对视频Transformer中使用的全时空注意力进行了两个方面的近似(如上图(d)):
a)它将时间注意力限制在一个局部时间窗口,并利用Transformer的深度来获得视频序列的全时间覆盖。
b)它使用有效的时空混合来联合建模空间和时间位置,并且不在仅空间注意的模型上产生任何额外的计算成本。
作者在本文中展示了如何集成两个非常轻量级的机制来实现全局时间attention,以最小的计算成本提供额外的精度提升。实验表明本文的模型在各种视频识别数据集(Something-Something-v2, Kinetics ,Epic Kitchens)上产生非常高的识别精度,同时比其他视频Transformer更加高效。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









