






关注公众号,发现CV技术之美
(本文阅读时间:21分钟)
编者按:2021年计算机视觉领域顶级会议 ICCV 于10月11日至17日在线上正式召开。此次大会共收到6236篇投稿,其中1617篇论文被接收,接收率为25.9%。在本届会议中,来自微软亚洲研究院的论文“Swin Transformer: Hierarchical Vision Transformer using Shifted Windows有多篇优秀论文入选,今天我们精选了其中的6篇来为大家进行简要介绍。

01
AutoFormer: 搜索用于视觉识别的 Transformer

论文链接:
https://arxiv.org/abs/2107.00651
代码链接:
https://github.com/microsoft/Cream
近来,Vision Transformer (ViT) 模型在诸多视觉任务中展现出了其强大的表达能力和模型潜力。但 Vision Transformer 模型的结构设计仍然比较困难,例如,如何选择最佳的网络深度、宽度和多头注意力中的头部数量。科研人员们通过实验发现,这些因素都和模型的最终性能息息相关。然而,由于搜索空间非常庞大,很难人为地找到它们的最佳组合。
对此,微软亚洲研究院的研究员们提出了一种专门针对 Vision Transformer 结构的网络结构搜索方法:AutoFormer。AutoFormer 大幅节省了人为设计结构的成本,并能够自动地快速搜索不同计算限制条件下 ViT 模型各个维度的最佳组合,这使得不同部署场景下的模型设计变得更加简单。
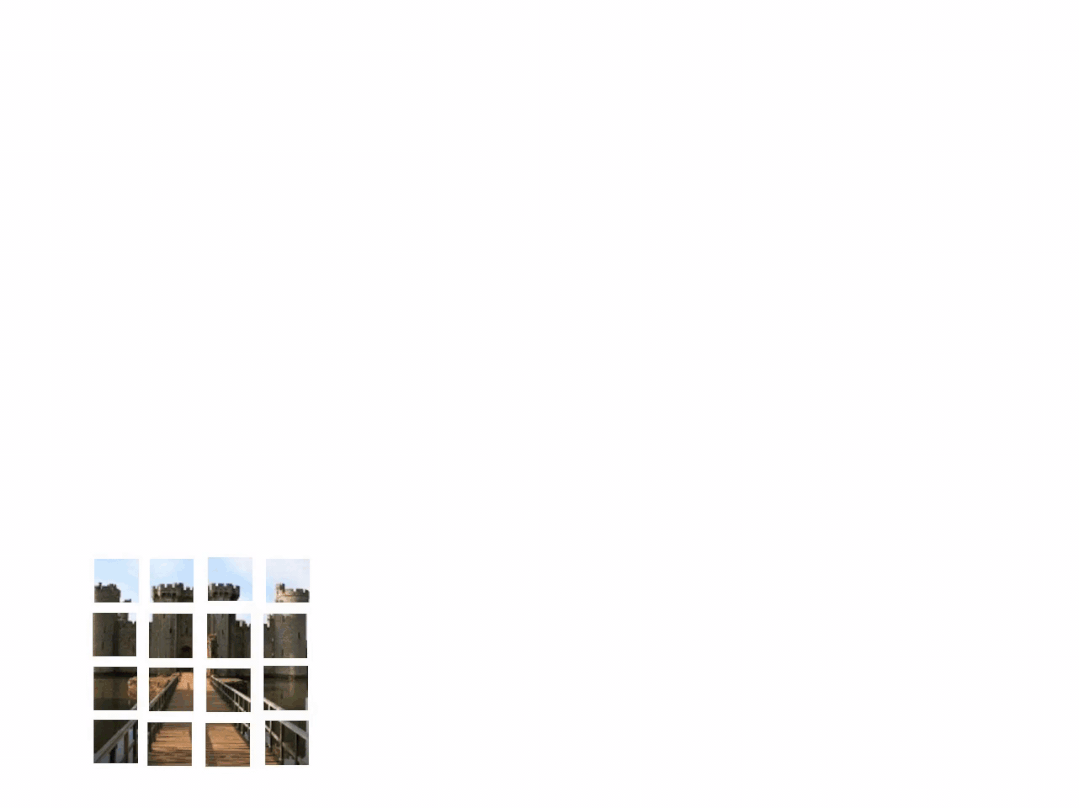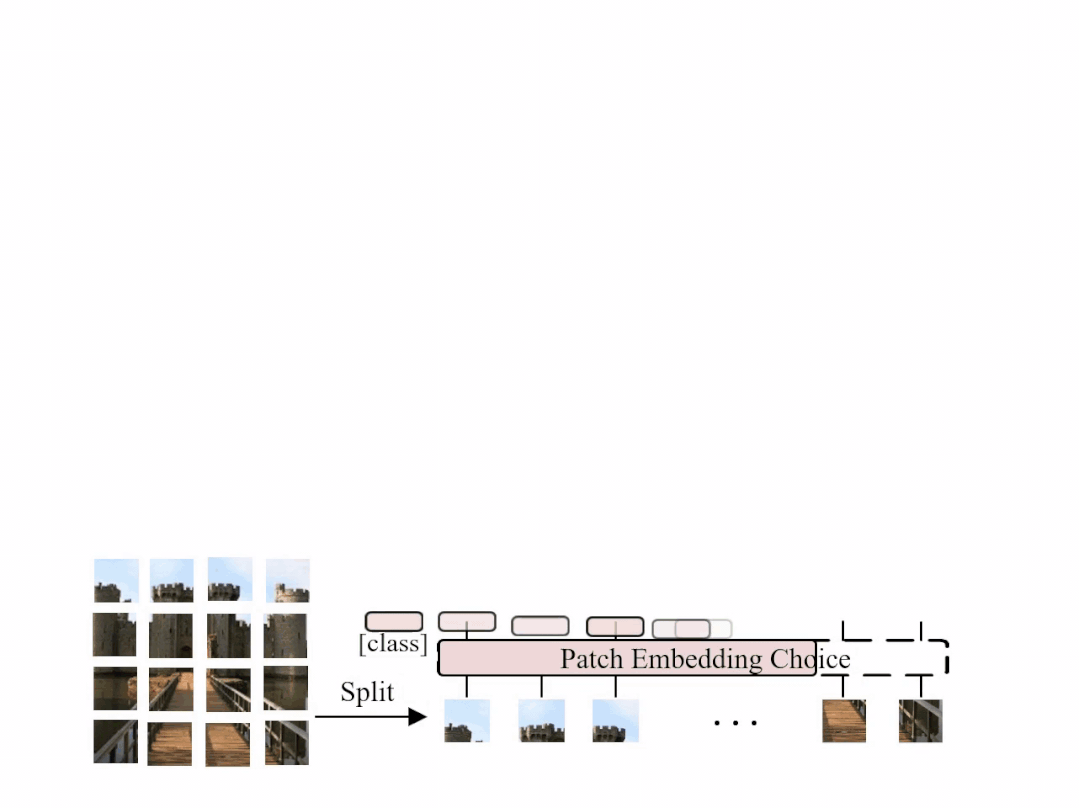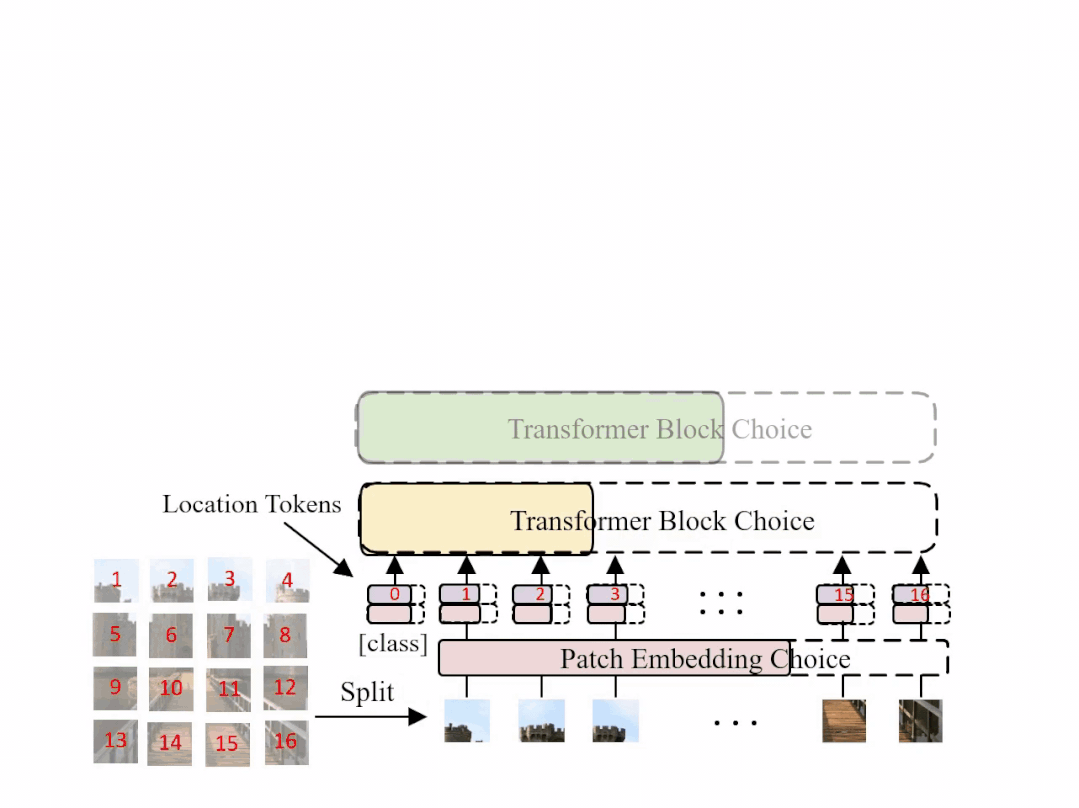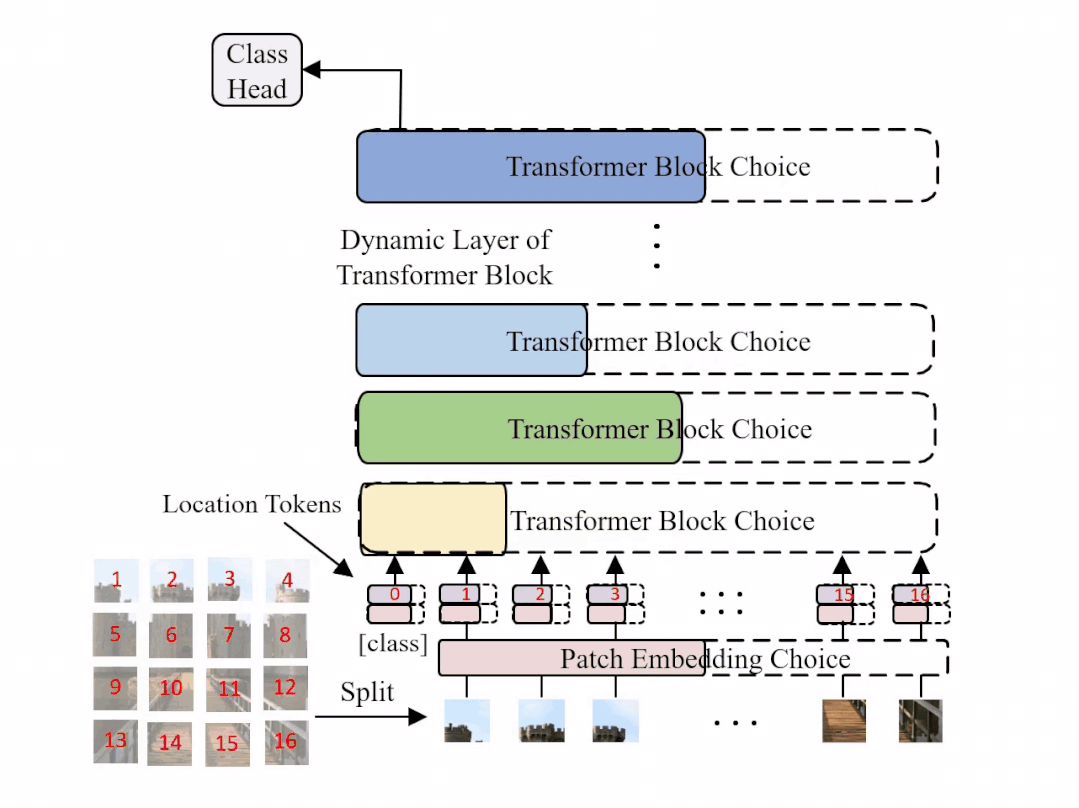
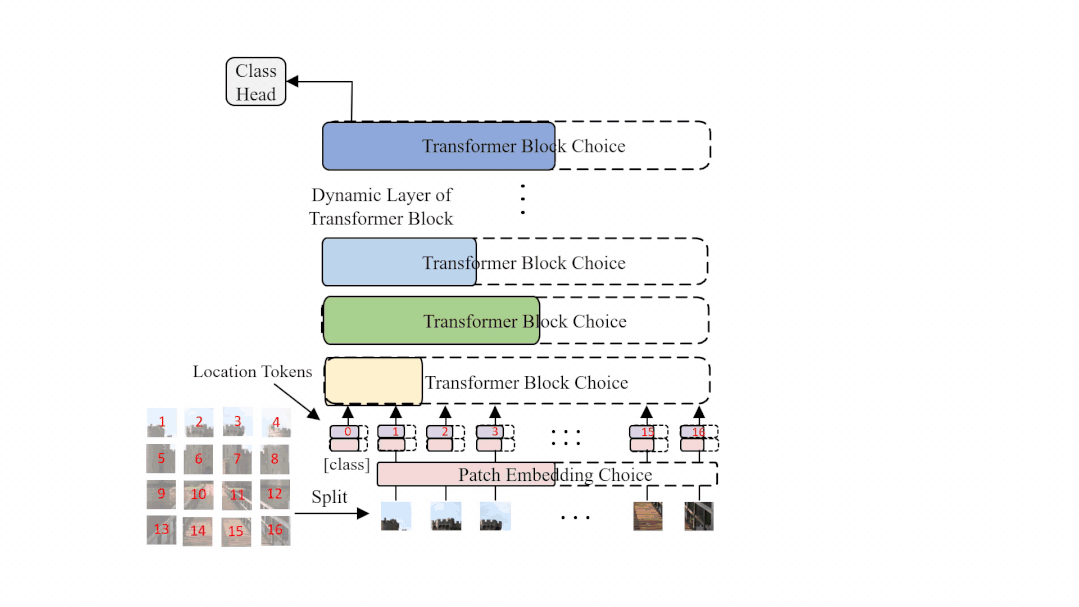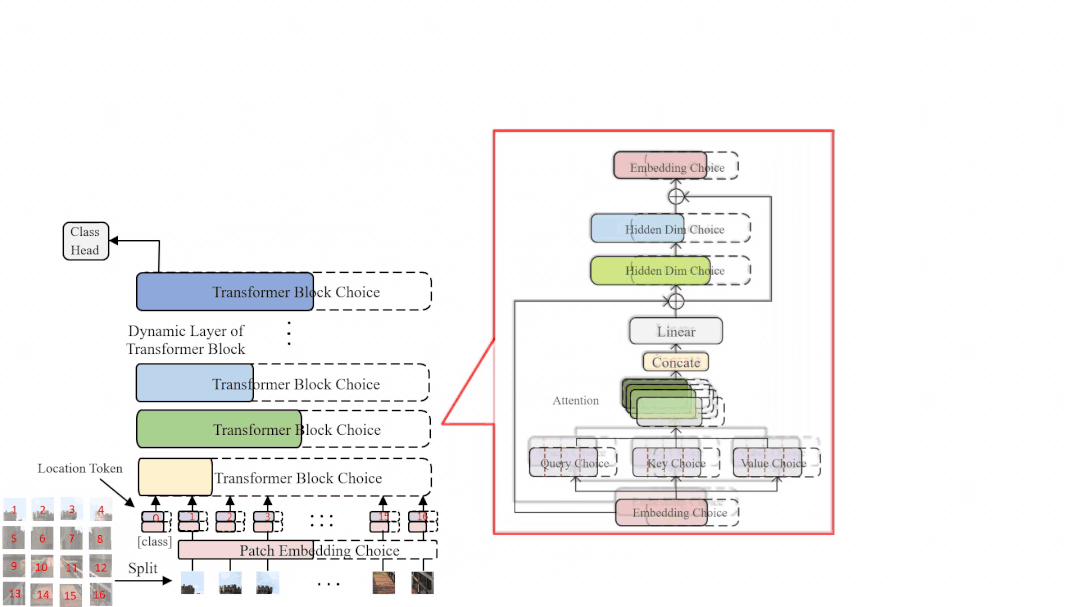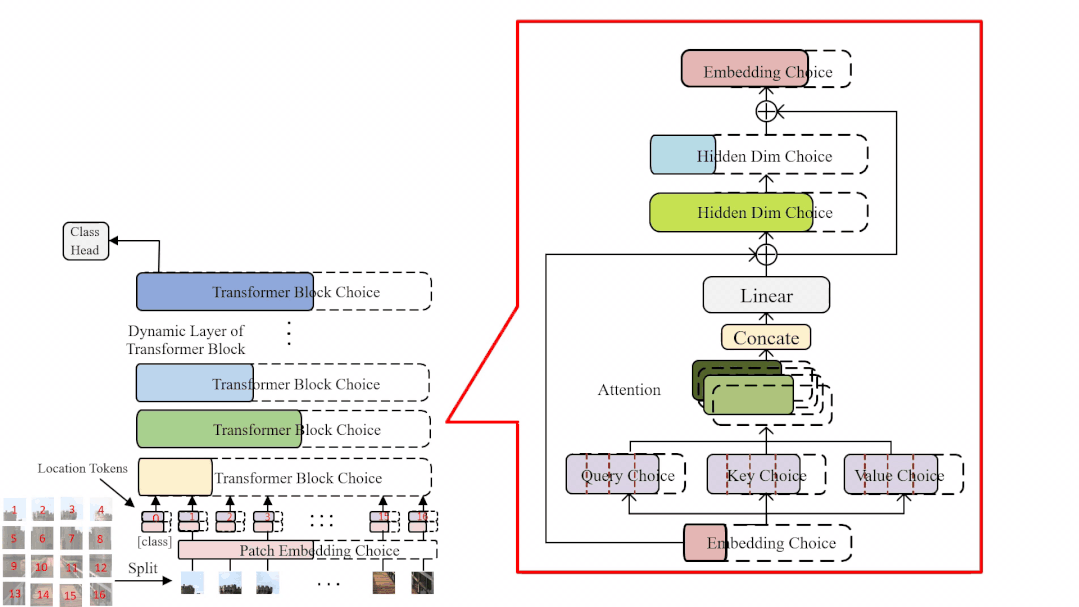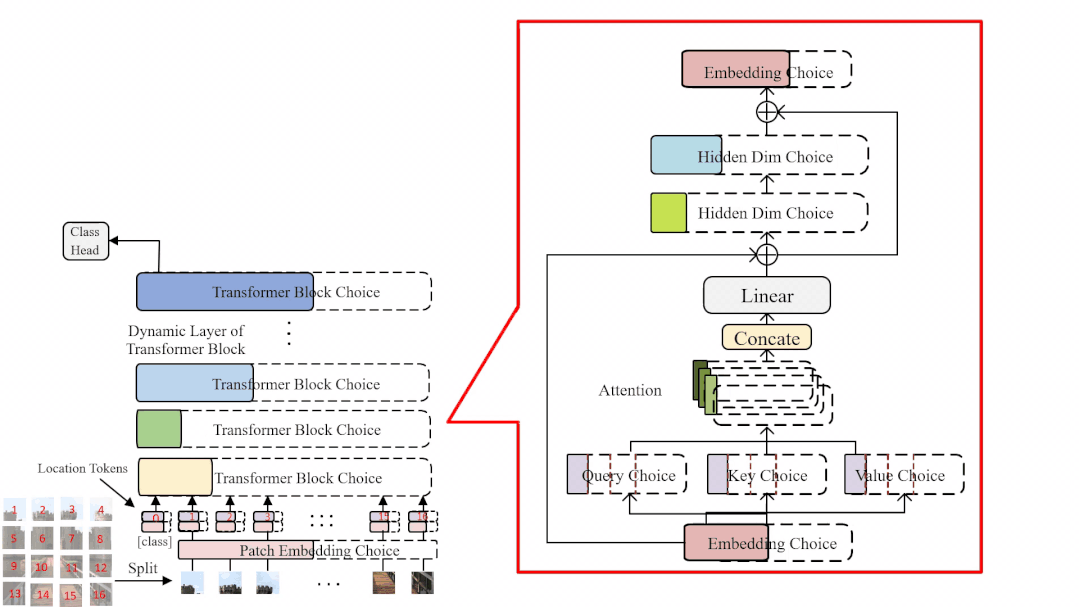
图1: AutoFormer 的结构示意图,在每一个训练迭代中,超网会动态变化并更新相应的部分权重
AutoFormer 方法亮点:
可同时训练大量 Vision Transformers 模型,使其性能接近每个模型单独训练;
简单有效,能够灵活应用于 Vision Transformer 的变种搜索;
性能较 ViT, DeiT 等模型有较明显提升。
在研究过程中,研究员们发现经典 One-shot NAS 方法的权重共享方式很难被有效地运用到 Vision Transformer 的结构搜索中。这是因为之前的方法通常仅共享结构之间的权重,而解耦同一层中不同算子的权重,如图2所示,在 Vision Transformer 的搜索空间中,这种经典的策略会遇到收敛缓慢和性能较低的困难。
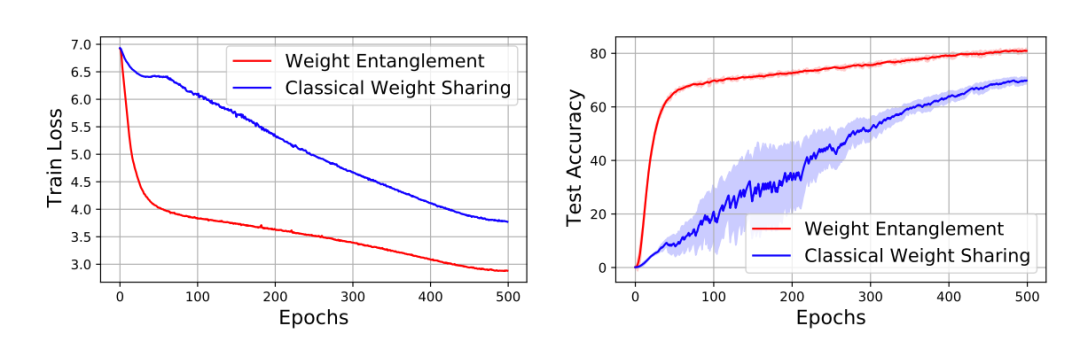
图2:权重纠缠和经典权重共享的训练以及测试对比
受到 OFA [4], BigNAS [5] 等工作的启发,研究员们提出了一种新的权重共享方式——权重纠缠 (Weight Entanglement)。如图3所示,权重纠缠进一步共享不同结构之间的权重,使得同一层中不同算子之间能够互相影响和更新,实验证明权重纠缠对比经典的权重共享方式,拥有占用显存少,超网收敛快和超网性能高的优势。同时,由于权重纠缠,不同算子能够得到更加充分的训练,这使得 AutoFormer 能够一次性训练大量的 ViT 模型,且使其接近收敛。
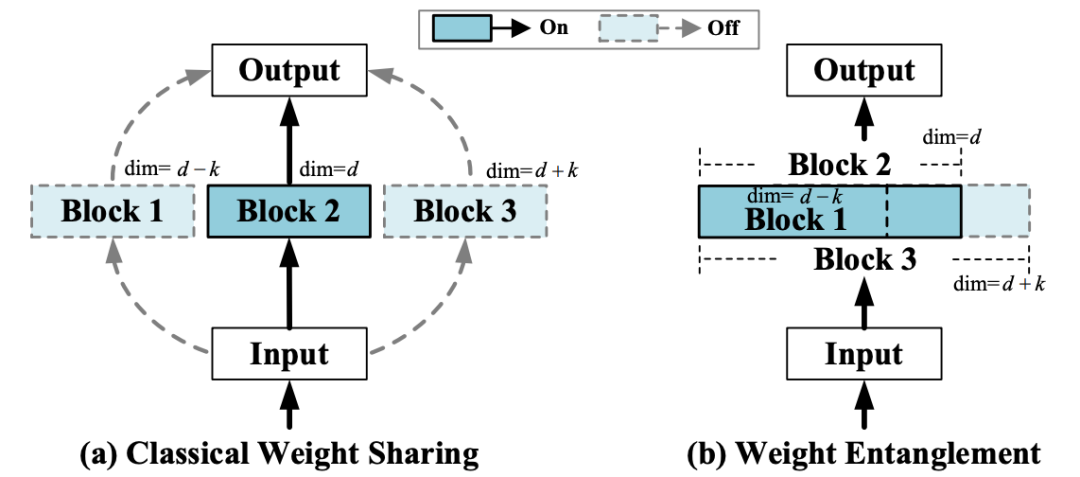
图3:权重纠缠和权重共享的对比示意图
研究员们设计了一个拥有超过1.7x10^17备选结构的巨大搜索空间,其搜索维度包括 ViT 模型中五个主要的可变因素:宽度 (embedding dim)、Q-K-V 维度 (Q-K-V dimension)、头部数量 (head number)、MLP 比率 (MLP ratio) 和网络深度 (network depth),详见表1。
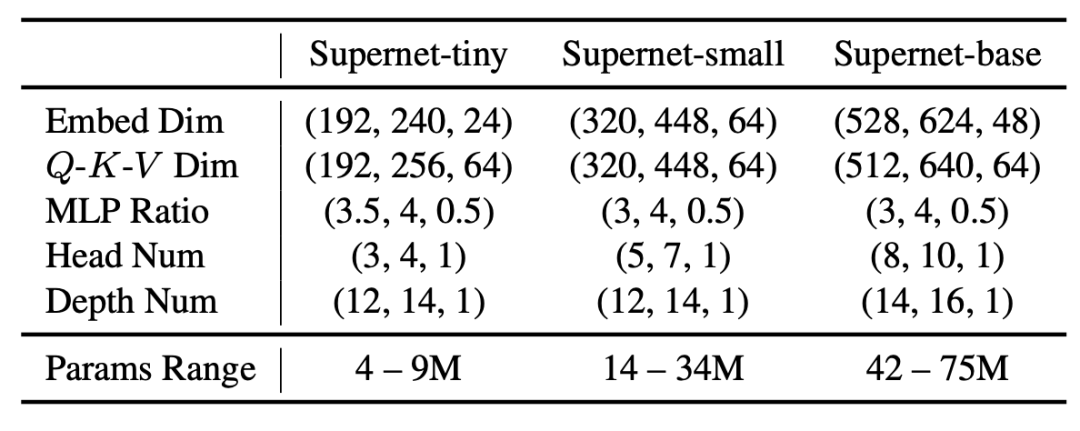
表1:AutoFormer 的搜索空间
为了验证方法的有效性,研究员们将 AutoFormer 搜索得到的结构和近期提出的 ViT 模型以及经典的 CNN 模型在 ImageNet 上进行了比较。对于训练过程,研究员们采取了 DeiT [6]类似的数据增强方法,如 Mixup, Cutmix, RandAugment 等。如图3和表2所示,搜索得到的结构在 ImageNet 数据集上明显优于已有的 ViT 模型。
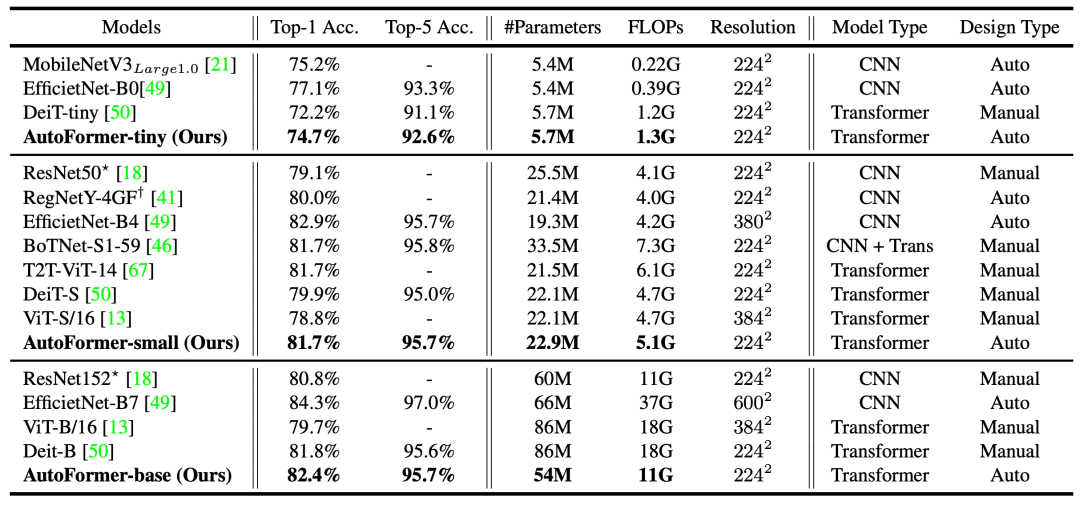
表2:各个模型在 ImageNet 测试集上的结果
在下游任务中,AutoFormer 依然表现出色,如表3所示,仅仅利用25%的计算量 AutoFormer 就超越了已有的 ViT 和 DeiT 模型,展现了其强大的泛化性能力。

表3:下游分类任务迁移学习的结果
如图4所示,利用权重纠缠,AutoFormer 能够同时使成千上万个 Vision Transformers 模型得到很好的训练(蓝色的点代表从搜索空间中选出的1000个较好的结构)。这不仅仅使得其在搜索后不再需要重新训练(retraining)结构,节约了搜索时间,也使得其能在各种不同的计算资源限制下快速搜索最优结构。
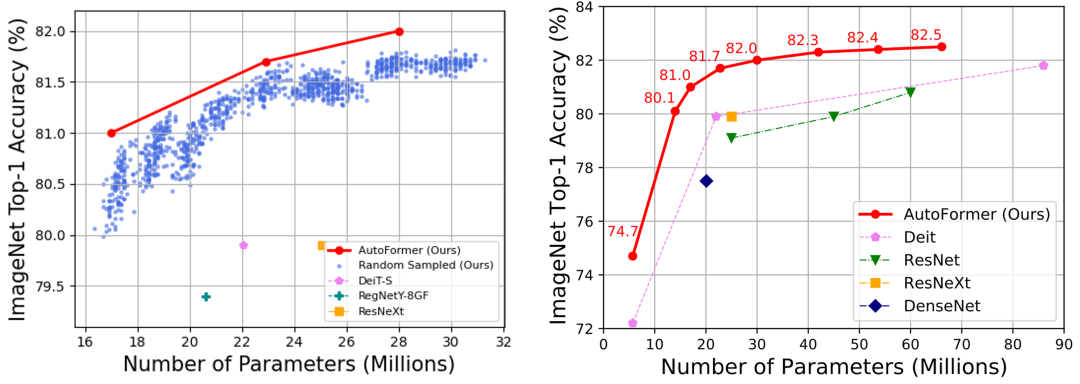
图4:左:AutoFormer 能够同时训练大量结构,并使得其接近收敛。右:ImageNet 上各模型对比
本文提出了一种新的专用于 Vision Transformer 结构搜索的 One-shot NAS 方法—— AutoFormer。AutoFormer 配备了新的权重共享机制,即权重纠缠 (Weight Engtanglement)。在这种机制下,搜索空间的网络结构几乎都能被充分训练,省去了结构搜索后重新训练(Retraining)的时间。
大量实验表明本文所提出的算法可以提高超网的排序能力并找到高性能的结构。在未来的工作中,研究员们将尝试进一步丰富搜索空间,以及给出权重纠缠的理论分析。
[1] Guo, Zichao, et al. "Single path one-shot neural architecture search with uniform sampling“. ECCV, 2020.
[2] Wu, Bichen, et al. "Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search." CVPR. 2019.
[3] Wan, Alvin, et al. "Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions." CVPR. 2020.
[4] Cai, Han, et al. "Once-for-All: Train One Network and Specialize it for Efficient Deployment." ICLR. 2019.
[5] Yu, Jiahui, et al. "Bignas: Scaling up neural architecture search with big single-stage models." ECCV, 2020.
[6] Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International Conference on Machine Learning, 2021
02
Soft-Teacher: 一个端到端的半监督物体检测算法

论文链接:
https://arxiv.org/abs/2106.09018.pdf
代码链接:
https://github.com/microsoft/SoftTeacher
数据是深度学习成功的基石。现代物体检测器往往依赖于大量的有标注数据,但是获取高质量且有标注的数据往往是困难且昂贵的。针对此问题,微软亚洲研究院的研究员与实习生们提出了一种全新的端到端半监督物体检测算法:Soft-Teacher。
该方法可以利用无标注数据来大幅度提升现有物体检测器的性能。例如:通过使用123K的无标签图像(unlabeled2017),Soft-Teacher 可将基于 ResNet-50 的 Faster R-CNN 的检测精度从 40.9mAP 提升至 44.5mAP。
Soft-Teacher 方法还推进了物体检测与实例分割性能的上界。如表4所示,通过使用 Soft-Teacher,基于 Swin-L 的 HTC++ 检测器在物体检测和实例分割性能分别可以达到 60.4mAP 与 52.4mAP,分别提升 1.5mAP 和 1.2mAP,这也是首个在 COCO test-dev set 上超过 60mAP 的物体检测结果。

表4:Soft-Teacher 可以提升 SOTA 物体检测器 HTC++(Swin-L) 的性能
研究员们还将该方法与此前最先进的半监督检测算法 STAC[1] 进行了比较。如表5所示,本文提出的方法比 STAC 在使用不同比例的标记数据设定下取得了 6mAP 及以上的性能提升。

表5:Soft-Teacher 与 STAC 在 val2017 上使用不同比例的部分标注数据(Partial Labeled Data)设定下的系统级比较
同时,研究员们也在使用全部有标记数据(Fully Labeled Data)的设定下与其他方法进行了比较,比较的所有方法均使用了基于在 train2017 数据集上进行有监督训练的 Faster-RCNN(ResNet-50) 作为基线。结果如表6所示,Soft-Teacher 相较于有监督基线提升了 3.6mAP,远优于 STAC[1] 与 Self-training[2] 等方法。
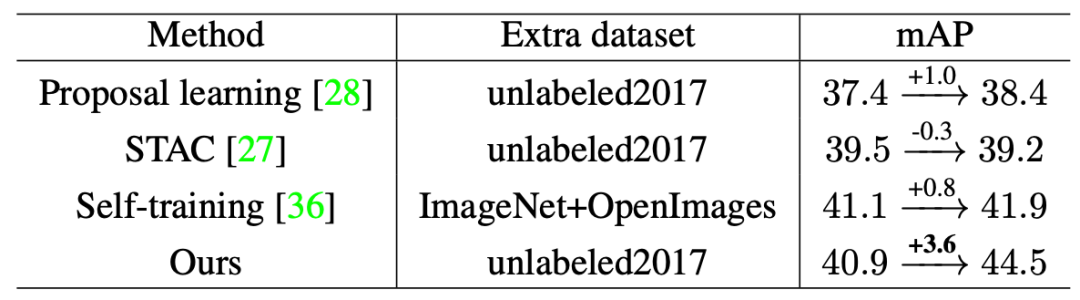
表6:Soft-Teacher 与其他最先进方法在使用全部有标记数据设定下的系统级比较
研究员们还在更广泛的物体检测器上测试了 Soft-Teacher,结果如表7所示,对与不同的物体检测器,Soft-Teacher 均可获得显著的性能提升。

表7:使用全部有标记数据设定下,Soft-Teacher 在不同的物体检测器均可以获得显著的性能提升
[1] A simple semi-supervised learning framework for object detection. Kihyuk Sohn, Zizhao Zhang, Chun-Liang Li, Han Zhang, Chen-Yu Lee, and Tomas Pfister.
[2] Rethinking pre-training and self-training. Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin D Cubuk, and Quoc V Le.
03
基于视频连续性的伪造人脸检测研究

论文链接:
https://arxiv.org/abs/2108.06693
随着 AI 换脸技术的不断发展,伪造人脸视频的质量也在不断提高,进而很难被人们识别。尽管当前的人脸操纵技术在质量和可控性方面取得了令人印象深刻的性能,但它们仍很难生成时序连续的换脸视频。这是因为大多数换脸视频都是逐帧独立生成的,不可避免地会导致视频人脸有明显闪烁和不连续性。
在这项工作中,微软亚洲研究院的研究员们探索了如何充分利用时序连续性进行更加通用的伪造人脸视频检测。检测时序不连续性是十分具有挑战性的,因为缺少了对视频中时序不连续的标注。通常最直接的做法是采用时空卷积网络,并期望模型学会通过时序不连续性来区分视频真伪。
但是实验发现,伪造人脸视频主要包括两种瑕疵,一种是空间瑕疵(如图像融合边界、棋盘格效应、模糊等),空间瑕疵在单张图像上即可观察到,它与换脸算法相关,且容易受到扰动的影响;另一种就是时序不连续性(如视频不同帧之间微小变化的不连续,如噪声、光照、运动等),时序不连续性只能在视频中观察到, 如图5所示。

图5:(a)行显示了在单张图像即可观察到的空间瑕疵 (b)行显示了在视频中才能观察到的时序不连续性
通常,空间瑕疵比时序不连续性更显著,简单的时空卷积网络倾向于通过空间瑕疵而不是时序不连续来判别真伪,这就使其泛化性能较差。为了检测时序不连续性,微软亚洲研究院的研究员们提出了一种新的端到端框架,它包括两个主要阶段:
第一阶段是全时序卷积网络(Fully Temporal Convolution Network, FTCN)。FTCN 的关键在于将空间卷积核大小减少到1,同时保持时序卷积核大小不变。研究员们发现这种特殊的设计可以使模型更有效地提取时序特征,同时提高泛化能力。
第二阶段是时序 Transformer,利用 Transformer 对长序列建模的能力进一步探索长期的时序连续性。相比于现有方法,研究员们所提出的框架具有通用性和灵活性,可以从头开始直接训练,无需任何预训练模型或外部数据集。
大量的实验表明,本文提出的框架优于现有的方法,并且在检测从未见过的换脸算法生成的人脸伪造视频时仍然有效,如表8所示。本文提出的框架仅在FF++数据集上训练,依然能够很好的泛化到其他数据集上,并优于现有方法。
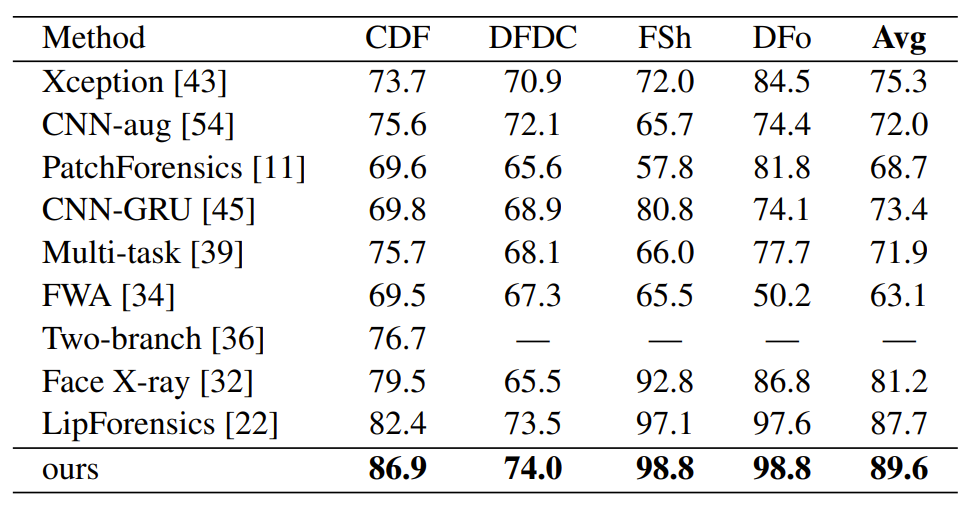
表8:在四种未见过的数据集(CDF, DFDC, FSh, DFo)上的实验结果
04
低质图像化军师:让图像复原测评摆脱高清依赖

论文链接:
https://arxiv.org/abs/2108.07948
代码/模型链接:
https://github.com/researchmm/CKDN
数字图像在处理、压缩、传输过程中,难免会发生质量亏损,因此图像复原(IR)算法应运而生(如图6所示)。图像复原算法旨在将低质量图像恢复成高质量图像,其中如何评估图像复原算法、衡量所恢复图像的质量是非常值得深入研究的话题。

图6:高清图像、低质量图像、所恢复图像
全参考图像质量评估(FR-IQA)方法是目前最有效的一种方式,也是被学术界广泛采用的方式,如 PSNR、SSIM、LPIPS 等。该方法是以质量亏损前的高清图像为参考,进而对比得到所恢复图像的质量分数。但是在实际应用中,高清图片往往无法获得,这时这些方法便不再适用。
无参考图像质量评估(NR-IQA)提供了另外一种解决思路:直接将待评估图像拟合到质量分数中,然而,参考信息的缺失导致问题难度变大,效果常常不尽人意。微软亚洲研究院的研究员们提出了低质参考图像质量评估(DR-IQA)的新思路(如图7所示),通过挖掘、利用图像恢复前的低质量图像,得到有用参考信息,从而更好地评估所恢复图像的质量。
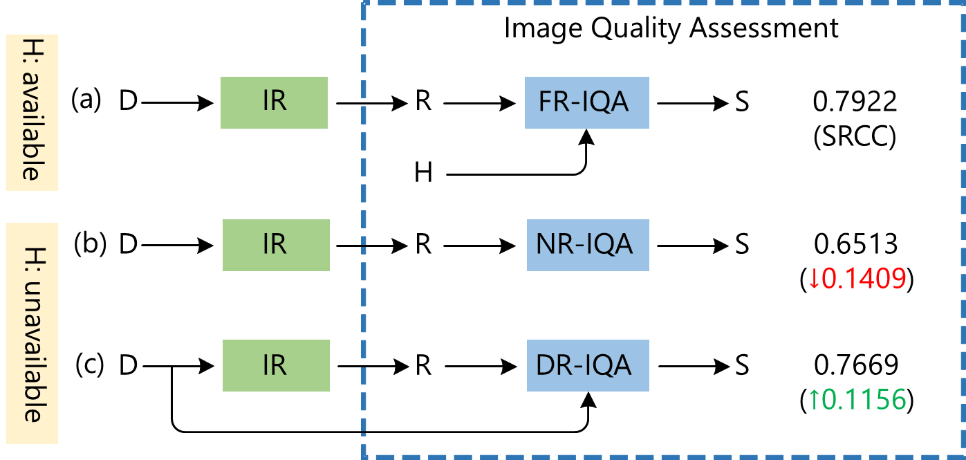
图7:FR-IQA、 NR-IQA、 DR-IQA对比图
如何从低质量图像中有效提取有用的参考信息?研究员们设计了一种条件知识蒸馏网络来完成这一任务,如图8所示。具体来讲,相对于低质量图像,从高清图像中提取有用参考信息更加容易。因此,研究员们将从高清图像中学到的参考信息,以知识蒸馏的方式指导低质量图像参考信息的提取过程。由于整个过程都是以提取对评估所恢复图像质量有帮助的参考信息为前提和条件的,所以本文提出的方法称作条件知识蒸馏。
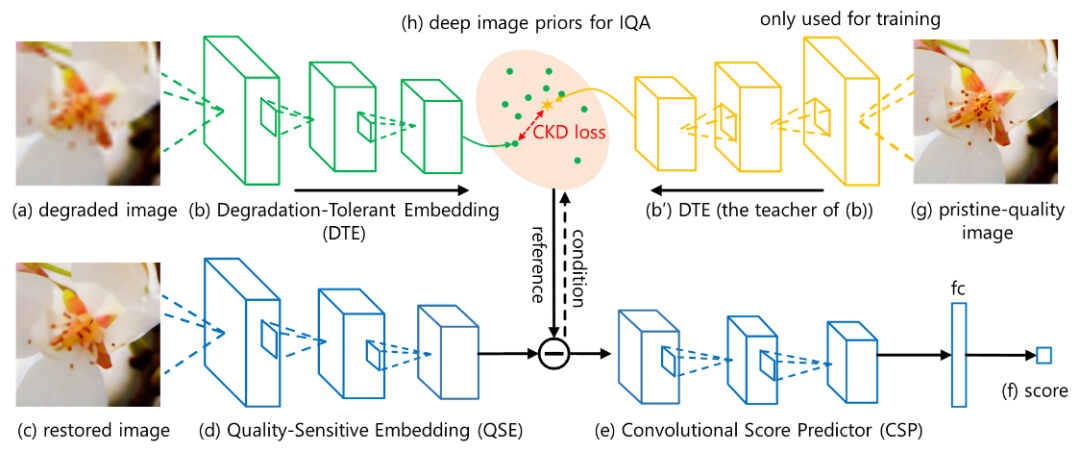
图8:条件知识蒸馏网络
研究员们在 PIPAL 数据集上进行了实验,通过与已有模型的 NR-IQA 模型比较可以发现,新提出的解决方案性能上有很大的提升。进一步地,研究员们还将已有的 FR-IQA 模型转化到低质参考的设定下和本文模型进行了对比,验证了本文模型的优越性。实验结果如表9所示。
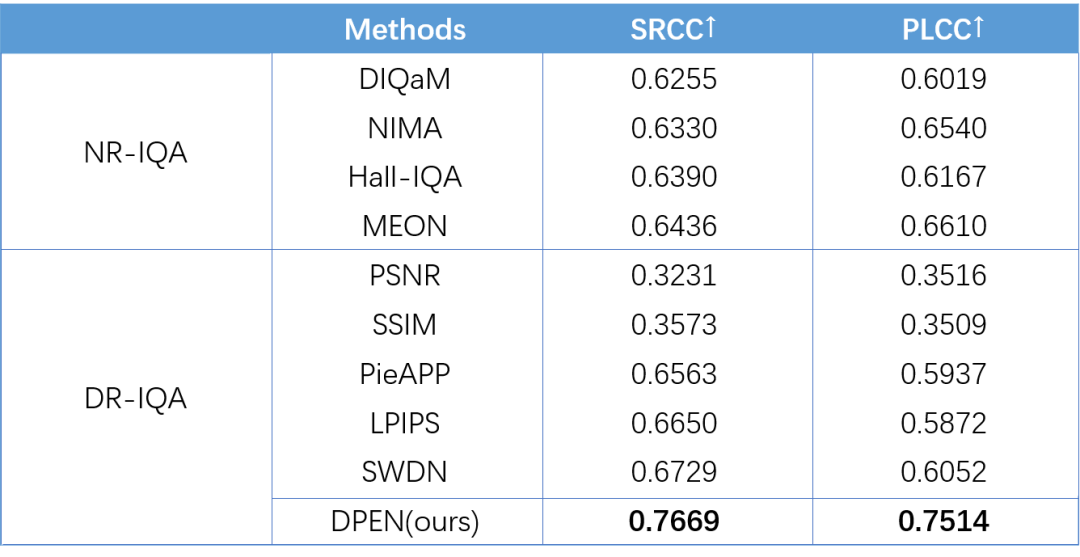
表9:对比实验结果
从图9可以看到,即使对质量亏损很严重的图像,本文的模型依然能够有效地从中提取出有用参考信息。

图9:低质量参考示例图
05
针对自监督视频表征学习的对比元学习网络

论文地址:
https://arxiv.org/abs/2108.08426
对比学习是目前自监督学习的主流方法之一。其过程是应用不同的数据增强方式产生出不同的 view,进而通过 view 和 view 之间的对比,让模型学到样本实例之间的异同点。目前性能最好的对比学习方法是将每个样本实例自身产生的 view 作为正样本,而其它实例产生的 view 则作为负样本进行训练。
然而,对于视频数据来说,这种方法存在明显的缺陷。视频数据具有更加丰富的空间和时间信息,往往存在两个不同的视频实例,它们的场景不同,但是描述的动作类似;或者场景相似,描述的动作差别很大。由于缺乏更细致的类别标签,这种实例会对模型的精度和泛化能力造成损伤,降低性能。
为了解决这一问题,微软亚洲研究院的研究员们提出了一种针对视频表征的对比元学习网络(Meta-Contrastive Network,MCN)。该方法首次利用元学习中对模型参数的导向性优势来优化对比学习的学习方向,让模型能够在众多的实例中学到应该学习的内容。在设计的过程中,研究员们进一步发现,单纯地将元学习和对比学习进行整合并不能提高太多的效率。
其原因在于,实例之间的对比损失无法彻底区分每一个实例,进而不能有效地构建元学习的子任务。因此,研究员们设计了一个分类预测分支,对两个表征是否来自于同一个实例进行了二值化预测。整个架构如图10所示。
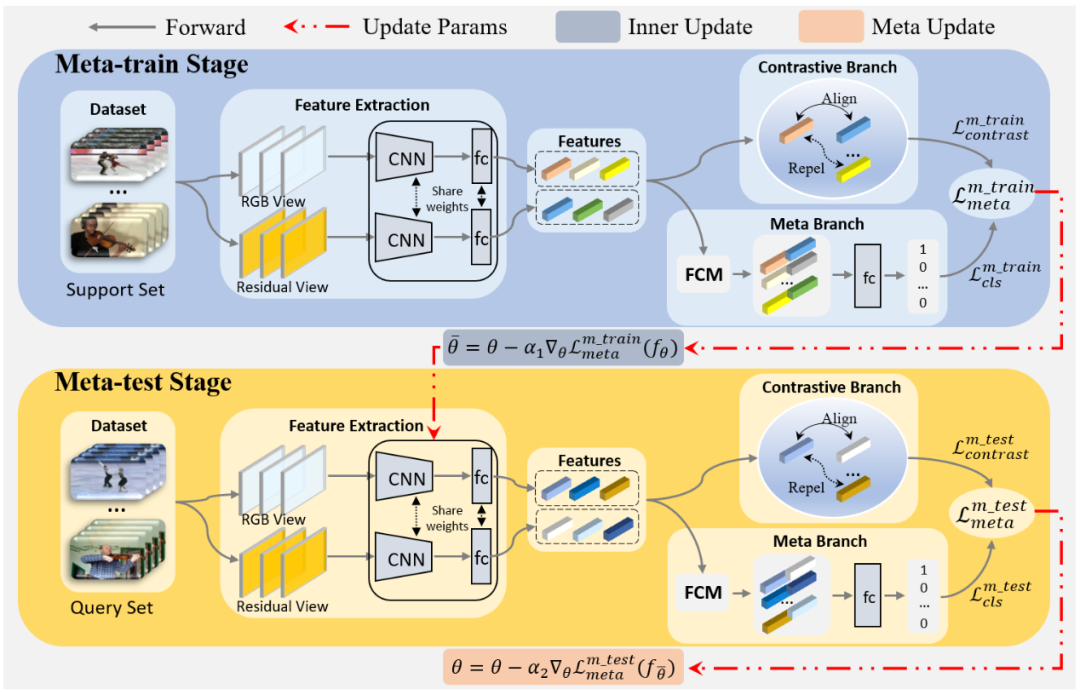
图10:对比元学习网络结构图
实验结果表明,MCN 在视频分类和检索两个下游任务上都取得了优异的效果,在 HMDB51 和 UCF101 数据集上都达到了 SOTA,结果如表10所示。可视化的结果显示,MCN 可以在很多情况下让网络更加关注视频的主要内容,例如,人和动作,从而增加了模型对下游任务的迁移能力。
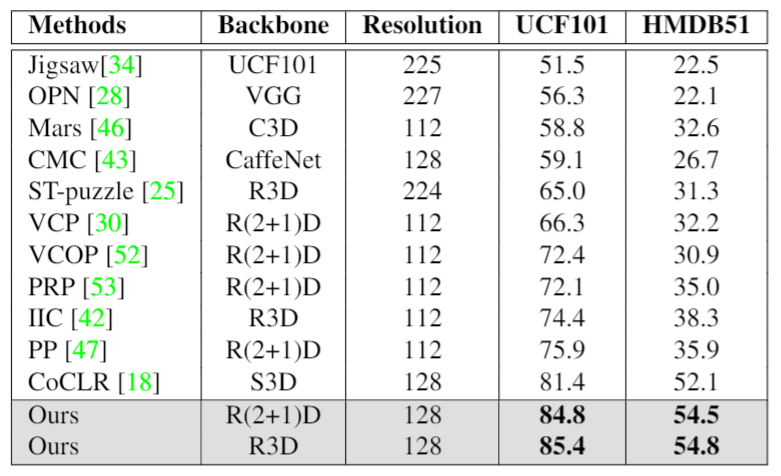
表10:MCN 视频分类结果的比较
06
利用对比式遮挡预测设计自监督学习

论文链接:
https://arxiv.org/abs/2108.07954
虽然基于实例判别任务 (Instance Discrimination, ID) 的自监督学习方法在过去一年来取得了爆发式的突破,但这些方法普遍是在 ImageNet 数据集上进行验证的。一些研究发现实例判别任务并不能很好地拓展到其他预训练数据集。
微软亚洲研究院的研究员们发现实例判别任务的弱拓展性来自于它对训练数据的语义一致性假设,即一张训练样本的任意位置包含一致的语义信息。这一假设对于 ImageNet 数据集恰好是成立的,而对其他数据集则不尽然。实验显示,选用不满足语义一致性假设的数据集(如MS COCO、Conceptual Captions)进行预训练,基于实例判别任务的自监督方法性能均有显著下降,如图11所示。
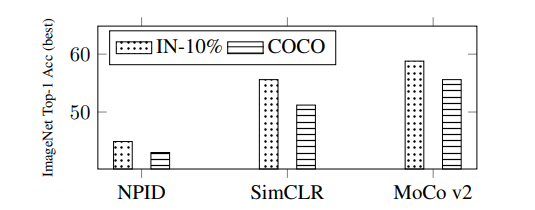
图11:三种基于 ID 的自监督学习方法在非 ImageNet 数据上性能均有显著下降
仅仅利用 ImageNet 数据集进行预训练显然和自监督学习的愿景是不一致的,设计一种不依赖于数据特性的预训练任务便成了亟待解决的问题。
研究员们注意到在自然语言处理领域存在一个非常成功的预训练任务,即BERT选用的掩码语言模型任务(Masked Language Model, MLM)。受此启发,微软亚洲研究院的研究员们设计了对比式遮挡预测任务(Contrastive Mask Prediction, CMP),如图12所示。
这一任务的目标是训练模型理解被遮挡的图像并预测出遮挡区域的语义内容,从而能够在一系列候选图片块中选出最佳答案。CMP 对数据的假设仅仅是图片块和其周边区域具有相关性,这一假设对自然图像均是成立的。

图12:对比式遮挡任务示例
研究员们基于 CMP 设计了一个被称作 Mask Contrast(MaskCo)的自监督学习方法,并在多个预训练数据集上进行实验,如图13所示。结果显示,摆脱了语义一致性假设的 MaskCo 尽管在 ImageNet 预训练上略逊于 MoCo V2 ,但在其他两个不满足语义一致性假设的数据集上取得了超越 MoCo V2 的结果,如表11所示。这一结果展现了 MaskCo 方法对更广泛预训练数据集的可观前景。
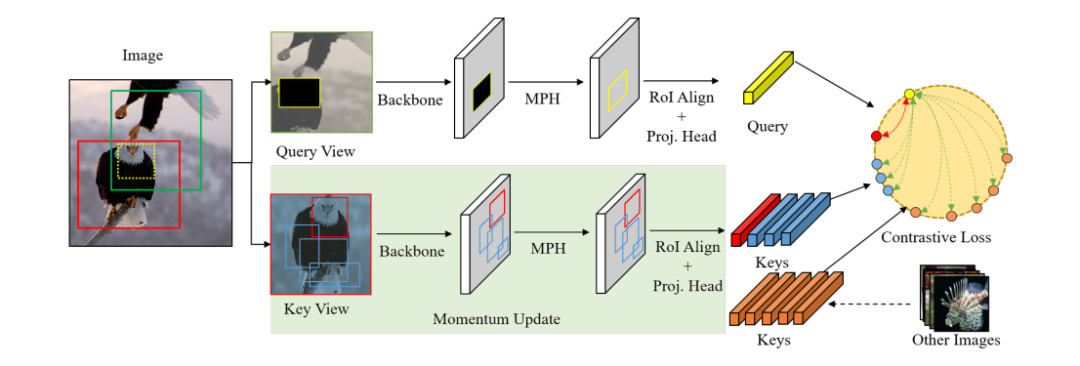
图13:MaskCo 方法概览
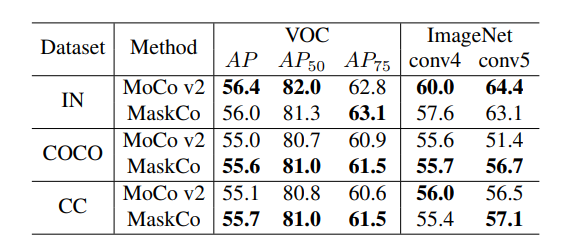
表11:MaskCo 与 MoCo V2 在多个预训练数据集上的结果比较

END
欢迎加入「计算机视觉」交流群👇备注:CV















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









