






prompt在视觉领域,也越来越重要,在图像生成,作为一种可控条件,增进交互和可控性,在多模态理解方面,指令prompt也使得任务灵活通用。视觉提示工程,已然成为CV一个前沿方向!
下面来看看最新的两篇论文,了解一下视觉提示的应用!
Visual Instruction Inversion: Image Editing via Visual Prompting
文本条件的图像编辑已经成为一种强大的图像编辑工具。
然而,在许多情况下,语言描述图像编辑具有歧义性和低效性。面对这些挑战时,视觉提示可以更直观和准确地传达所需的编辑内容。
本文提出了一种通过视觉提示进行图像编辑的方法。通过给定代表编辑的“之前”和“之后”图像的示例对,方法学习一个基于文本的编辑方向,用于在新图像上执行相同的编辑。利用文本到图像扩散模型的丰富预训练编辑能力,将视觉提示转化为编辑指令。
结果表明,即使只有一个示例对,也可以获得与最先进的文本条件图像编辑框架相竞争的结果。https://thaoshibe.github.io/visii/

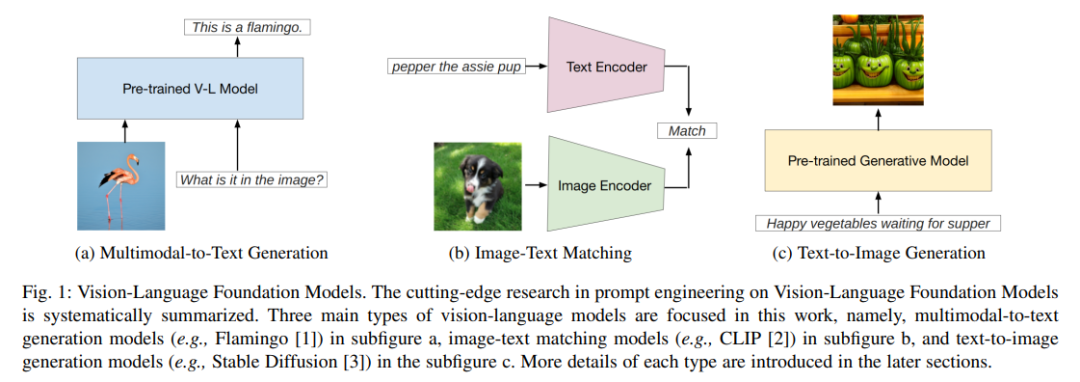
A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
Prompt engineering是一种技术,它通过增加大型预训练模型与针对特定任务的提示(即prompt)来适应新任务。提示可以手动创建为自然语言指令,也可以自动生成为自然语言指令或向量表示。
Prompt engineering使得仅依靠提示就可以进行预测,而无需更新模型参数,并且更容易将大型预训练模型应用于任务。
在过去的几年里,Prompt engineering在自然语言处理领域得到了广泛研究。然而,目前缺乏关于预训练视觉语言模型上Prompt engineering的系统综述。本文旨在对三种类型的视觉语言模型(包括多模态生成模型、图像-文本匹配模型和文本-图像生成模型)上的Prompt engineering的前沿研究进行全面的调查。对于每种模型,概述了模型简介、提示方法、基于提示的应用以及相关的责任和完整性问题。
此外,还讨论了视觉语言模型、语言模型和视觉模型上的Prompt engineering的共性和差异。总结了挑战、未来方向和研究机会,以促进未来关于这个方向研究。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









