






关注公众号,发现CV技术之美
本文分享论文『VLMo: Unifified Vision-Language Pre-Training with Mixture-of-Modality-Experts』,由微软提出《VLMo》,用“模态混合专家”进行统一的视觉语言预训练!即将开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2111.02358
项目链接:https://github.com/microsoft/unilm/tree/master/vlmo
导言:

在本文中,作者提出了一个统一的视觉语言预训练模型(VLMo),它用一个模块化的Transformer网络联合学习一个双编码器和一个融合编码器。
具体来说,作者引入了模态混合专家(MOME) Transformer,其中每个块包含一个特定于模态的专家池和一个共享的自注意层。由于MOME具有建模的灵活性,预训练好的VLMo可以作为视觉语言分类任务的融合编码器进行微调,或用作图像-文本检索的双编码器。此外,作者提出了一种阶段预训练策略,该策略除了图像-文本对外,还有效利用大规模的图像和文本数据。
实验结果表明,VLMo在各种视觉语言任务上都取得了SOTA的结果,包括VQA和NLVR2。
01
Motivation
视觉语言预训练从大规模的图像-文本对中学习通用的跨模态表示。以往的模型通常采用图像-文本匹配、图像-文本对比学习、mask区域分类/特征回归、单词-patch对齐和mask语言建模来聚合和对齐视觉和语言信息。然后,预训练好的模型可以直接对下游的视觉语言任务进行微调,如VL检索和分类(视觉问答、视觉推理等)。
两种主流的结构在以前的工作中被广泛使用。CLIP和ALIGN采用双编码器结构,分别对图像和文本进行编码。模态交互作用由图像和文本特征向量的余弦相似性来处理。双编码器结构对检索任务是有效的,特别是对大量的图像和文本。可以预先计算和存储图像和文本的特征向量。然而,图像和文本之间的浅层交互并不足以处理复杂的VL分类任务。ViLT发现CLIP在视觉推理任务上的准确性相对较低。
因此,另一系列工作依赖于一个具有跨模态注意的融合编码器来建立模型的图像-文本对。多层Transformer网络通常被用于融合图像和文本表示。融合编码器结构在VL分类任务上取得了SOTA的性能。但它需要联合编码所有可能的图像-文本对来计算检索任务的相似性分数。二次时间复杂度导致的推理速度比线性的双编码器模型的推理速度要慢得多。
为了利用这两种类型的架构,作者提出了一个统一的视觉语言预训练模型(VLMo ),可以作为双编码器分别编码图像和文本的检索任务,或者作为融合编码器来建模图像文本对的深度交互。这是通过引入模态混合专家(MOME) Transformer来实现的,该Transformer可以在Transformer块中编码各种模态(图像、文本和图像-文本对)。MOME使用了一群模态专家来取代标准Transformer中的前馈网络。它通过切换到不同的模态专家来捕获特定模态的信息,并使用跨模态共享的自注意来对齐视觉和语言信息。
具体来说,MOME Transformer由三个模态专家组成,即图像编码视觉专家、文本编码语言专家和图像-文本融合视觉语言专家。由于建模的灵活性,可以重用具有共享参数的MOME Transformer,用于不同的目的,即仅文本编码器、仅图像编码器和图像-文本融合编码器。
VLMo基于图像-文本对比学习、图像文本匹配和掩码语言建模三个预训练任务共同学习。此外,作者提出了一种阶段预训练策略,在VLMo预训练中除了图像-文本对外,还能有效地利用大规模的仅图像和仅文本语料库。作者首先利用BEIT中提出的mask图像建模,对MOME Transformer的视觉专家和自注意模块进行预训练。然后使用mask语言建模对语言专家进行仅文本数据的预训练。
最后,利用该模型来初始化视觉语言的预训练。通过摆脱有限的图像文本和其简单的文本描述,对大量图像和文本数据进行阶段预训练有助于VLMo学习更一般化的表示。
作者通过微调视觉语言检索和分类任务来评估VLMo。实验结果表明,在检索任务上,本文的模型作为双编码器的模型时,比目前基于融合编码器的模型性能更好,同时推理速度要快得多。此外,本文的模型在视觉问答(VQA)和视觉推理的自然语言(NLVR2)方面取得了SOTA的结果,其中VLMo被用作融合编码器。
02
方法
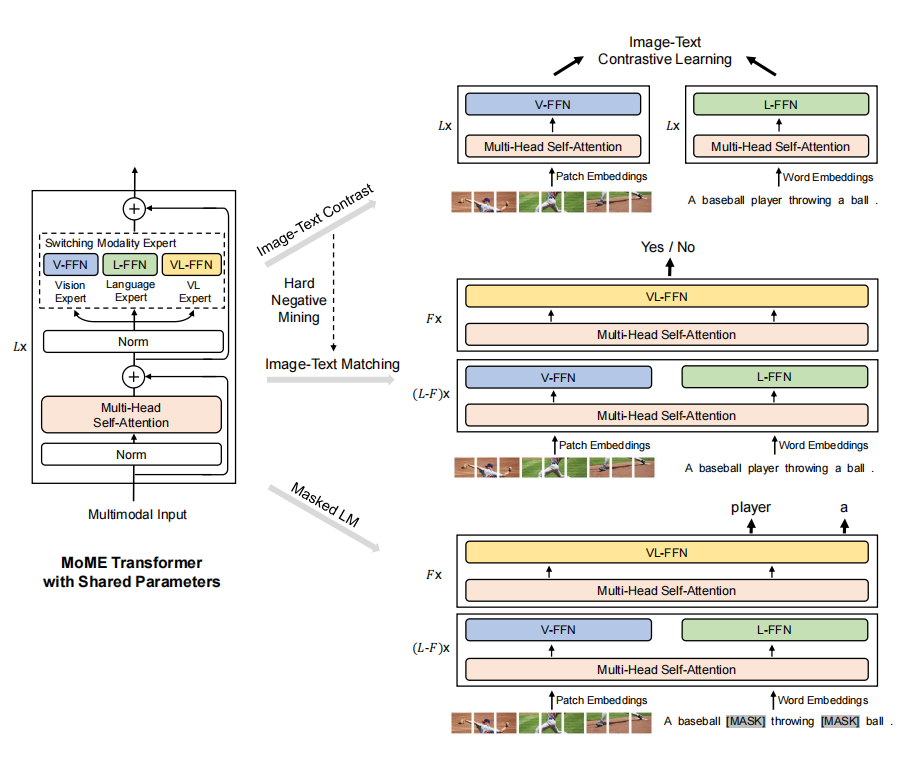
给定图像-文本对,VLMo通过MOME(Mixture-of-Modality-Experts) Transformer 网络获得仅图像、仅文本和图像-文本对的表示。如上图所示,统一的预训练优化了共享的MOME Transformer的图像-文本对比学习,图像-文本匹配和图像-文本对表示的mask语言建模。在微调过程中,该模型可以作为双编码器进行检索任务,对图像和文本进行分别编码。它还可以作为融合编码器进行微调,以为分类任务建模更深层次的模态交互。
2.1 Input Representations
Image Representations
对于图像表示,首先将二维图像分割为个patch,其中C为通道数,(H,W)为输入图像的分辨率,(P,P)为patch分辨率。然后将图像patch铺平到向量中,并线性投影以获得patch嵌入。
此外,作者还为序列准备了一个可学习的特殊token [I_CLS]。最后,通过相加patch嵌入、可学习的一维位置嵌入和图像类型的嵌入获得最终的图像表示,即,其中,为线性投影。
Text Representations
对于文本表示,作者通过WordPiece将文本token转换为为 subword。将在文本序列中添加一个序列开始token([T_CLS])和一个特殊的边界token([T_SEP])。文本输入表示是通过对相应的单词嵌入、文本位置嵌入和文本类型嵌入的求和来计算的,即。M表示subword token的长度。
Image-Text Representations
对于图像文本表示,作者concat了图像和文本的输入向量,形成图像-文本输入表示。
2.2 Mixture-of-Modality-Experts Transformer
受专家混合网络的启发,作者提出了一种用于视觉语言任务的通用多模态Transformer,即MOME Transformer,以对不同的模态进行编码。MOME Transformer引入模态专家混合作为标准Transformer前馈网络的替代。给定上一层的输出向量,每个MOME Transformer块通过切换到不同的模态专家来捕获特定于模态的信息,并使用跨模态共享的多头自注意(MSA)来对齐视觉和语言内容:
MoME-FFN根据输入向量的模态和输入Transformer层的索引,选择一名专家对输入进行处理。具体来说,有三个模态专家:视觉专家(V-FFN)、语言专家(L-FFN)和视觉语言专家(VL-FFN)。
如果输入是仅图像或仅文本向量,则使用视觉专家对图像进行编码,使用语言专家对文本进行编码。如果输入由多种模态的向量组成,如图像-文本对的向量,则使用视觉专家和语言专家在Transformer底层编码各自的模态向量。然后使用视觉语言专家在顶层来捕获更多的模态交互。给定这三种类型的输入向量,就得到了仅图像、仅文本和图像文本上下文化的表示。
2.3 Pre-Training Tasks
VLMo通过对图像和文本表示的图像-文本对比学习(image-text contrastive learning)、掩码语言建模(masked language modeling)和对具有共享参数的图像-文本对表示的图像-文本匹配(image-text matching)进行联合预训练。给定一个batch的N个图像-文本对,图像-文本对比学习的目标是从N × N个可能的图像-文本对中预测匹配的对。在训练batch中有个负图像-文本对。
Image-Text Contrast
[I_CLS] token和[T_CLS] token的最终输出向量分别被用作图像和文本的聚合表示。然后进行线性投影和归一化,就可以在一个训练batch中获得图像向量和文本向量,以计算图像到文本和文本到图像的相似性:
其中表示第i对图像和第j对文本的图像对文本的相似性,表示文本对图像的相似性。表示第i文本和第j个图像的归一化向量,σ是学习的温度参数。是Softmax标准化的相似性。利用图像到文本和文本到图像相似性上的交叉熵损失来训练模型。
Masked Language Modeling
与BERT相似,作者在文本序列中随机选择token,并将它们替换为[MASK] token。该模型被训练,从所有其他未mask的token和视觉线索中预测这些mask的token。作者使用了15%的mask概率,如在BERT中所述。将mask token的最终输出向量被输入整个文本词汇表的分类器,基于交叉熵损失进行分类。
Image-Text Matching
图像-文本匹配旨在预测图像和文本是否匹配。作者使用[T_CLS] token的最终隐藏向量来表示图像-文本对,并将该向量输入一个具有交叉熵损失的分类器中进行二分类。受ALBEF的启发,作者基于对比图像对文本和文本到图像的相似性来采样 hard negative的图像-文本对。
2.4 Stagewise Pre-Training
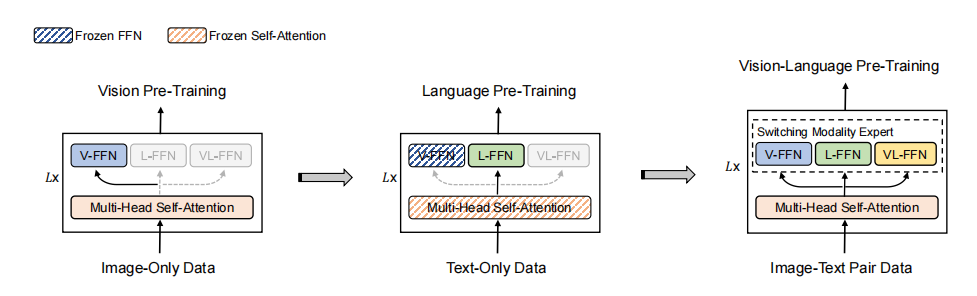
作者引入了一种阶段预训练策略,它利用大规模的仅图像和仅文本语料库来改进视觉语言模型。如上图所示,作者首先对仅图像数据进行视觉预训练,然后对只对文本数据进行语言预训练,以学习一般的图像和文本表示。该模型用于初始化视觉语言预训练,以学习视觉和语言信息的对齐。
对于视觉预训练,作者训练了MOME Transformer的视觉专家和注意力模块。作者直接利用BEIT的预训练参数来初始化注意模块和视觉专家。对于语言预训练,作者冻结了注意力模块和视觉专家的参数,并利用掩码语言建模来优化仅文本数据上的语言专家。与图像-文本对相比,仅图像和仅文本的数据更容易收集。图像-文本对的文本数据通常很短而简单。对仅图像和仅文本语料库的预训练提高了对复杂对的泛化性能。
2.5 Fine-Tuning VLMo on Downstream Tasks
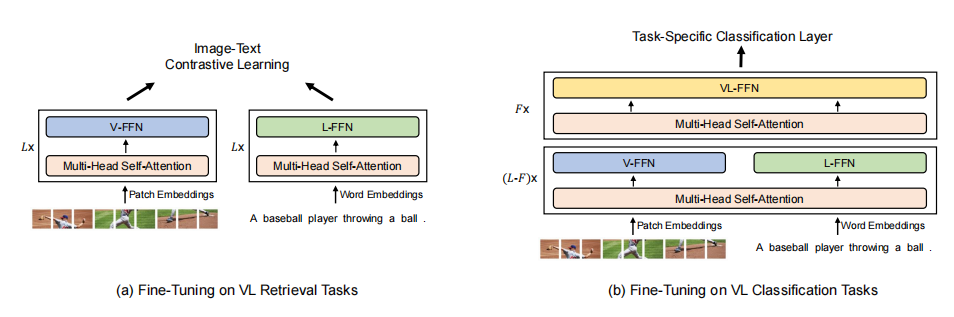
如上图所示,本文的模型可以进行微调,以适应各种视觉语言检索和分类任务。
Vision-Language Retrieval
对于检索任务,VLMo可以作为双编码器分别对图像和文本进行编码。在微调过程中,本文的模型对图像-文本的对比损失进行了优化。在推理过程中,需要计算所有图像和文本的表示,然后使用点积获得所有可能的图像-文本对的图像到文本和文本到图像的相似性得分。单独的编码比基于融合编码器的模型能够实现更快的推理速度。
Vision-Language Classification
对于视觉问答和视觉推理等分类任务,VLMo被用作融合编码器来建模图像和文本的模态交互。作者使用[T_CLS] token的最终编码向量作为图像-文本对的表示,并将其输入一个特定于任务的分类器层来预测标签。
03
实验
3.1. Evaluation on Vision-Language Classification Tasks
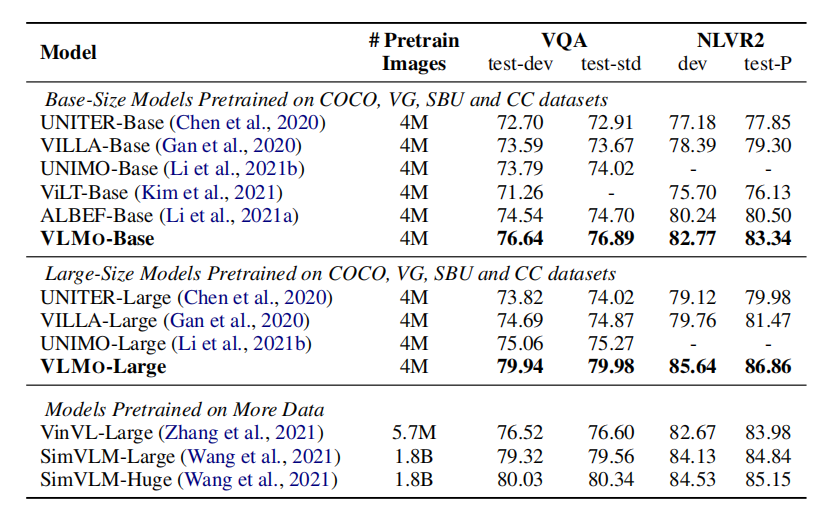
上表展示了在VL分类任务上(VQA和NLVR2),本文方法和SOTA的预训练方法的实验结果。可以看出相同的预训练数据量下,本文的方法能够取得比其他方法更好的性能。
3.2. Evaluation on Vision-Language Retrieval Tasks
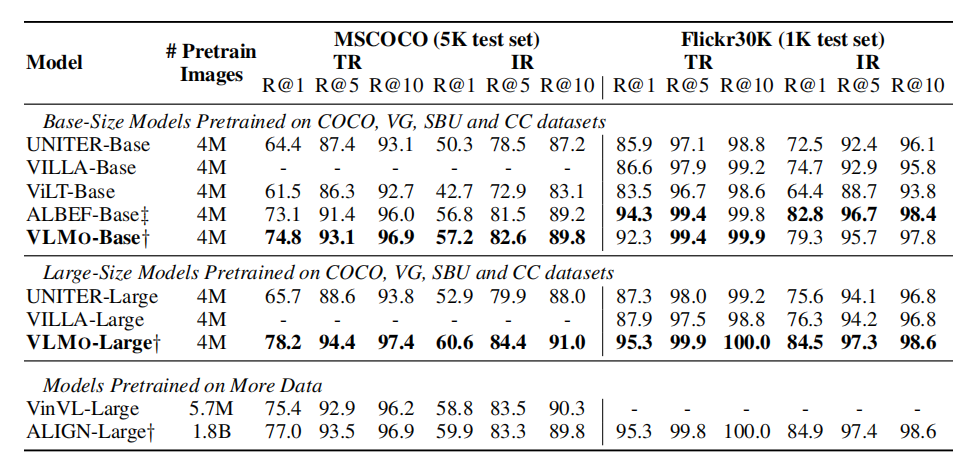
上表展示了在COCO和Flickr30K数据集上,本文方法和SOTA方法的图文检索实验结果对比。可以看出VLMo能够达到更好的实验结果。
3.3. Ablation Studies
Stagewise Pre-Training
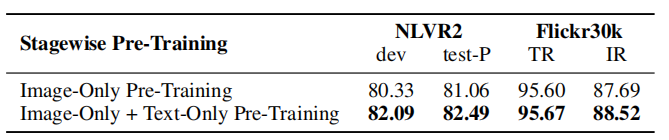
上表展示了VLMo在不同阶段预训练设置下的实验结果,可以看出,阶段预训练有效地利用了大规模的仅图像和仅文本语料库,从而改进了视觉语言预训练。
MOME Transformer & Pre-Training Tasks
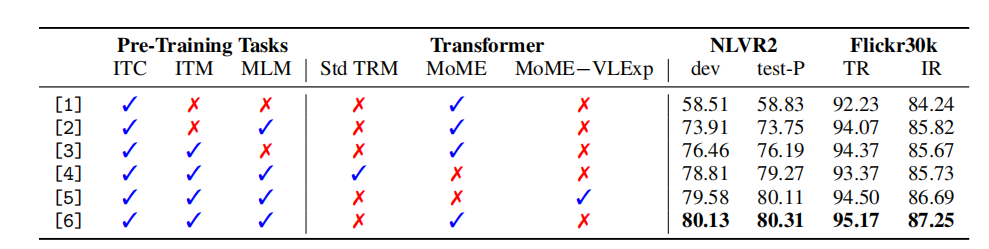
上表展示了VLMo不同结构和预训练任务下的消融实验结果。
04
总结
在这项工作中,作者提出了一个统一的视觉语言预训练模型VLMo,它用一个共享的MOME Transformer联合学习了一个双编码器和一个融合编码器。
MOME引入了一群模态专家来编码特定于模态的信息,并使用共享的自注意模块来对齐不同的模态。使用MOME的统一预训练使模型能够被用作高效视觉语言检索的双编码器,或者作为融合编码器来建模分类任务的交叉模态交互。
作者还表明,利用大规模仅图像和仅文本语料库的阶段预训练极大地改善了视觉语言预训练。VLMo在各种视觉语言基准测试上的性能都优于以前SOTA的模型。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视觉语言」交流群👇备注:VL















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









