









Background
深度神经网络在计算机视觉领域占据主导地位,但对理解复杂模型的推理有很高的要求。因此,可解释性和可解释性变得越来越重要。

原型(Prototype)在解释可解释模型中的含义是:
原型代表模型学习到的一组重要特征或模式,这些特征/模式可以用来解释和表示输入样本中的某些重要概念或特征。
比如在图像分类模型中,原型可以代表某个物体的具有代表性的某个部件,如狗的耳朵或眼睛。
原型具有以下特征:
1 学习自动提取,而不是人工指定。
2 可解释性强, correspond 到人眼可识别的实际概念。
3 可以用来解释模型如何对样本进行分类。
模型预测狗图片时,如果 Eyes 原型的权重高,表明模型通过检测眼睛这一特征作出判断。通过使用原型,模型可以用更直观和人性化的方式解释其内部运作机制,同时也可以对学习效果进行监督和评估。
总体来说,原型作为一组概念或模式,可视为是模型自动学习到的解释要素,有助于理解模型的决策逻辑。

基于prototypical patches 的可解释方法可以识别图像中的各种成分,以便向人类解释它们的推理。现有的基于原型的方法可以学习不符合人类视觉感知的原型,即同一个原型可以参考现实世界中的不同概念,使得解释不直观。
如下图所示

Related Research
ProtoPNet、ProtoTree、ProtoPShare和ProtoPool仅设计用于细粒度图像识别任务(鸟类和汽车类型),并且在学习到的原型和人类概念之间缺乏“语义对应”。ProtoPNet和ProtoTree,优化相同类的图像以具有相同的原型。学习一个代表太阳和狗的单一原型,特别是当模型被优化为只有很少的原型时(如下图所示)。因此,模型对补丁相似度的感知可能与人类的视觉感知不一致,从而导致感知到的“语义差距”。
主要现有原型部分解释模型的缺点如下:
a 仅针对细粒度图像分类任务设计,如鸟类或车辆种类,缺乏“语义对应的能力”。
b 模型假设同类图像对应同一原型,但这一假设并不一定成立,导致latent空间中的相似性与人眼感知不符。
c 存在所谓的“语义差距问题”:latent空间中的相似点在像素空间并不对应同一语义概念。
d 大多数模型需要预先指定每个类对应的原型数量,如ProtoPNet是2000个,解释难以理解。
e 学习出的原型质量差,同一个原型可能对应不同语义,解释性不强。
f 仅基于类标签训练,难优化原型本身的语义性,无法完全关闭“语义差距”。
解释大小固定,含有冗余原型,无法动态优化解释的紧凑程度。
g 无法处理分布外样例,无法给出“未见过”的解释。
h 大多为后验解释方法,无法保证与模型内部逻辑一致。
总之,现有模型在原型语义表达能力、解释大小与灵活性、异常检测等方面存在局限,难成为直观可解释的解决方案。
如下图所示
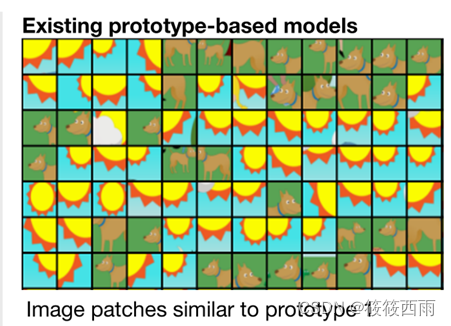
Motivation
人类视觉感知的相似度是指人类通过视觉判断的两幅图像之间的相似程度。例如,人类的视觉可以毫不费力地区分狗和太阳,而模型可以将它们学习为相似的语义。因此,人类感知到的相似性考虑了更广泛的视觉和高级认知因素,不同于模型学习到的相似性——被称为“语义差距”问题。

现有的模型可以学习与人类视觉感知的相似性不一致的原型的表示(中)。作者的目标是学习那些看起来与人类相似的概念的原型(右)。

Model Architecture
PIP-Net模型的结构主要包括以下部分:
卷积神经网络后端(如Resnet或ConvNext):用于提取输入图像的特征映射。
原型节点:通过对特征映射应用Softmax预测每个小patch属于哪个原型,得到原型存在分数表示。
自监督预训练:通过对图片 patch 对应的特征矢量应用对齐loss和均匀loss,使得相似patch分配到同一个原型上,此步不使用分类信息。
线性分类层:用非负权值将学习出的原型连接到分类,可以解释为一个稀疏的打分表。
训练:采用分类损失让线性层学习权重,同时通过自定义的函数优化稀疏性和 explanations 大小。
预测:直接使用原型存在分数与线性层权值相乘作为分类分数,保留连续打分表的解释性。
解释:以原型patch集和它们对类的贡献程度解释模型的决策过程。
特征提取后的卷积特征图经过一系列简单计算得到原型存在表示,并直接转化为解释模型结论的直观原型特征,这就是PIP-Net模型很容易理解的原因。

PIP-Net由CNN主干(例如ConvNeXt)组成,以学习原型表示z。特征表示汇集到原型存在分数p的向量。对比学习实现了在潜在特征空间(loss𝐿_tanh-loss 𝐿_𝑇防止了琐碎的解决方案,并使模型正则化,以利用所有可用的原型。因此,PIP-Net将潜在空间分解为与特定物体部分相关的神经元。学习到的零件原型和类通过一个稀疏线性层连接起来。𝐿c为标准的负对数似然损失。测试期间的模型输出没有规范化,并且允许将输出解释为简单的计分表。
Self-Supervised Pre-Training of Prototypes
PIP-Net在不使用分类标签的情况下以自监督的方式预训练原型。
目的是:
1 .学习原型之间的语义相似性:感知上不同的原型不应该在潜在空间中相似。
2 .只使用图像级标签,不使用额外的部分注释。
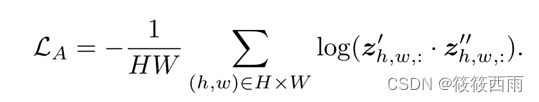
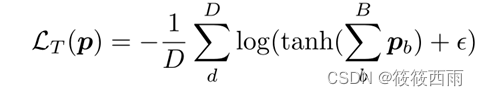
Training PIP-Net
1 冻结原型节点,解冻并训练线性分类层。
采用标准的分类损失函数LC,即这一阶段主要调整线性层的权重,帮助原型与分类任务联系起来。
2 解冻整个模型进行联合训练。
此时训练目标为:LC + LA + LT
3通过自定义的激活函数来实现三个目标:
(1)解释为打分表形式
(2)学习稀疏解以压缩解释大小
(3)能检测分布外数据
4具体是将(pωc)进行平方和对数处理,这同时起到正则化作用。
5训练过程采用Adam优化器,采用余弦退火学习率策略。
6预测时直接使用pωc作为分数,保留连续分数的解释性。
7 整体训练60个epoch,采用TrivalAugment数据增强。
这个阶段主要是联合训练将原型与分类任务关联起来,同时通过损失函数和激活函数实现高解释性。
Scoring Sheet Reasoning
1 将最后的线性分类层设计为可解释的打分表,通过汇总相关原型的 Weights 查找证据支持某个类别。
2 训练时使用Softmax将非归一化的logits转换为概率分布,提高学习效率。
3 但直接使用Softmax会有以下问题:
不利于学习稀疏解,无法实现解释的简洁性
初期分数高时类别概率很不平衡,后期分数低也很不平衡
无法实现模型识别分布外样本的能力
4 为了解决以上问题,模型提出了一种额外的归一化策略:
将得分进行平方和对数处理,使得0分保持不变,实现OoD检测能力。
同时正则化权重,使模型倾向于学习更稀疏的解空间。

Dataset


Results

上图展示了最近基于原型部件的模型的准确性和解释的紧凑性。用模型中至少有一个非零权重的原型的数量来衡量全局解释的大小。局部解释可以计算与任何类相关的所有现有原型,也可以只计算预测的类,如下图所示。

OOD dection

OOD detection意为out-of-distribution检测。
即检测输入样本是否来自模型训练时使用的数据分布,如果来自其他不同分布的数据,则将其检测为OOD(out-of-distribution)。
上表展示了PIP-Net在OOD检测方面的效果。
具体来说:
OOD:表示来自其他数据集的分布外样本。例如测试PIP-Net在PETS数据集时,OOD样本来自CUB和CARS数据集。
ID:表示模型在训练时使用的原始数据集,例如PETS。
FPR95指标:计算当真正样本检出率为95%时,误报率多高。
举例来说,当PIP-Net在PETS数据集上将95%的PETS样本(即ID样本)检出为内部分布时,同时它只将0.9%的CARS样本和12.9%的CUB样本错误检出为PETS分布内部。这表明PIP-Net具有很好的OOD检测能力,能区分不同源头的数据集,这也与模型设计保留0分数的目标相符。
下图显示了学习原型的前10个patch

总结
这篇文章的主要贡献包括:
1 提出了一种新型的可解释图像分类模型PIP-Net,它基于原型部分学习可解释的原型,实现内置解释性。
2 PIP-Net采用自监督学习的新正则化方法,学习原型之间的相似性,使得 latent 空间中的相似性能更好地与人类视觉感知相一致,从而减小了所谓的语义差距。
3 PIP-Net可解释为一个稀疏的打分表,它可以检测图像是否属于任何类,或是否属于多个类。它也可以对OOD数据进行分类并说“我没有看到过这个”。
4 PIP-Net在学习原型时不需要预先指定原型数量,它只需要一个原型数量的上限,并尽可能地学习少量但能达到良好分类精度的原型,实现了99%以上的稀疏度。
5经实验验证,PIP-Net学习出的原型与ground truth的对象部件紧密对应,表明它关闭了between latent space 和像素空间的“语义差距”。
6 PIP-Net提供了全局解释性和直观的本地解释性。它的解释相对于其他模型更简洁,同时保持了自省学习能力。
7 PIP-Net采用简单但高效的架构,仅需要图像级标签就可以学习原型,不需要其他标注,提高了适用范围。
PIP-Net通过解释性设计,学习出高质量且与人类视觉感知一致的原型,实现了简洁但深入的模型解释能力。















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









