







关注公众号,发现CV技术之美
本文分享 CVPR 2022 论文『Bridging Video-text Retrieval with Multiple Choice Questions』,港大&腾讯&UCBerkeley提出带有多项选择任务的视频文本检索模型,《BridgeFormer》,性能SOTA!
详细信息如下:

论文链接:https://arxiv.org/abs/2201.04850
项目链接:https://github.com/TencentARC/MCQ
01
摘要
近年来,对一个模型进行预训练,学习可迁移的视频文本表示以供检索,引起了人们的广泛关注。以前的主流作品主要采用两个单独的编码器进行高效检索,但忽略了视频和文本之间的局部关联。另一项研究使用联合编码器与文本进行视频交互,但效率较低,因为每个文本-视频对都需要输入到模型中。在这项工作中,作者实现了细粒度的视频-文本交互,同时通过一种新的借口任务(pretext task),即多项选择问题(MCQ),保持检索的高效性,在该任务中,参数化模块BridgeFormer经过训练,通过借助视频特征回答文本特征构造的“问题”。
具体而言,作者利用文本(即名词和动词)的丰富语义来构建问题,通过这些问题,视频编码器可以被训练来捕捉更多的区域内容和时间动态。在问答形式中,局部视频文本之间的语义关联可以正确建立。BridgeFormer可以被移除以进行下游检索,只需两个编码器即可提供高效灵活的模型。本文的方法在五个不同实验设置(即Zero-Shot和微调)的数据集中,在流行的文本到视频检索任务上优于最先进的方法,包括HowTo100M(一百万个视频)。
作者进一步进行了Zero-Shot动作识别,它可以看作是视频到文本的检索,本文的方法也明显优于其他方法。本文的方法在单模态下游任务(例如,带有线性评估的动作识别)上通过更短的预训练视频获得了有竞争力的结果。
02
Motivation
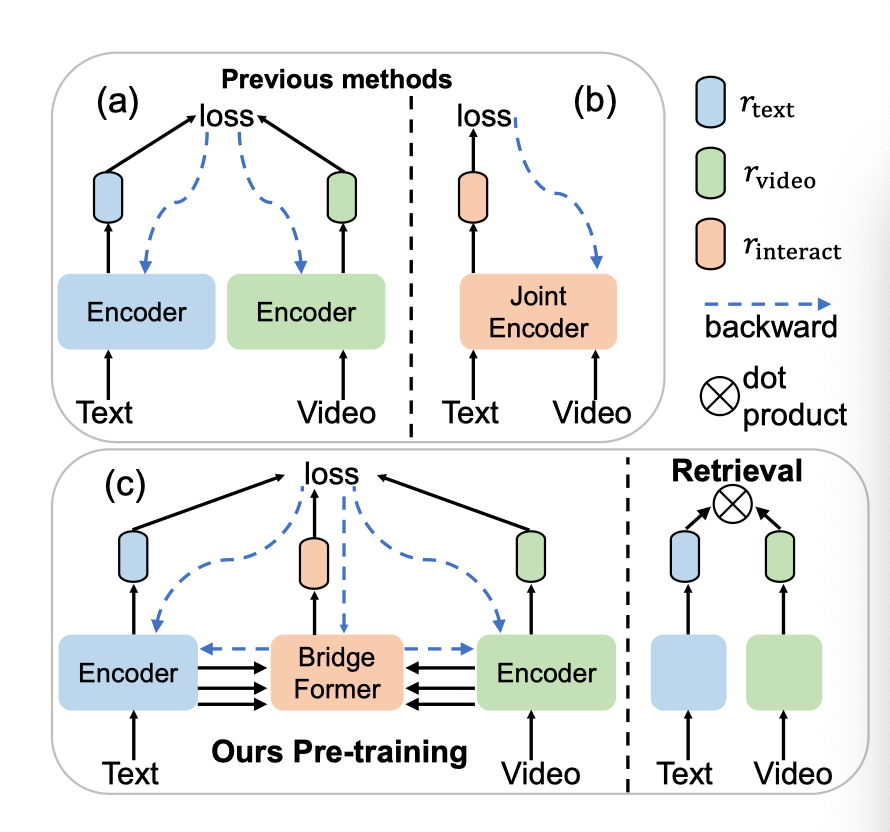
预训练一个学习视频文本检索可转移表示的模型需要理解视频概念、文本语义和视频-文本的关系。现有的视频文本预训练作品可分为两大类。“双编码器”方法(上图(a))采用两个单独的编码器分别对比视频级和句子级表示,忽略每个模态内的详细局部信息以及模态之间的关联。“联合编码器”方法(见上图(b))将文本和视频连接起来,作为联合编码器的输入,用于视频和文本的局部特征之间的交互,提高检索效率(推理过程中需要将每一个文本-视频对输入编码器),以实现细粒
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









