








目录
3.1、Dual-encoder for Video-text Pre-training: a revisit
问题与方案
问题:大多数VidL预训练模型采用两种不同的编码器分别对视频和文本编码以进行高效的视频文本检索,但是却忽略了视频和文本之间的局部关联性,另一部分研究使用联合编码器对视频和文本进行交互,但由于每个视频文本对都要输入到模型中,导致检索低效率的问题。
方案:通过一个新的预训练pretext task(多项选择问题(MCQ)),保持检索的高效性,实现细粒度的视频文本交互。包含一个新的参数化的模块BridgeFormer通过借助视频特征来回答由文本特征构建的“问题”,通过回答这些问题可以训练视频编码器来捕获更多的空间内容和时间信息。
一、Introduction
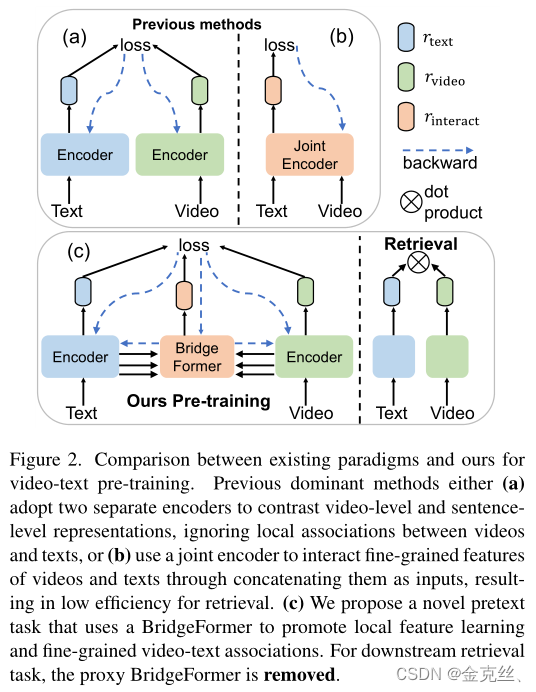
现有的视频文本预训练工作可分为两大类。
- “Dual-encoder”【6,13,15,24,28,31,36,46,50】(图2a)采用两个单独的编码器,忽略每个模态内的详细局部信息以及模态之间的关联。
- “Joint-encoder”【22、23、25、42、45、51】(图2b)将文本和视频连接起来,作为联合编码器的输入,用于视频和文本的局部特征之间的交互,牺牲了检索效率(每个文本-视频对需要在推理过程中输入编码器),以获得细粒度特征学习的好处。
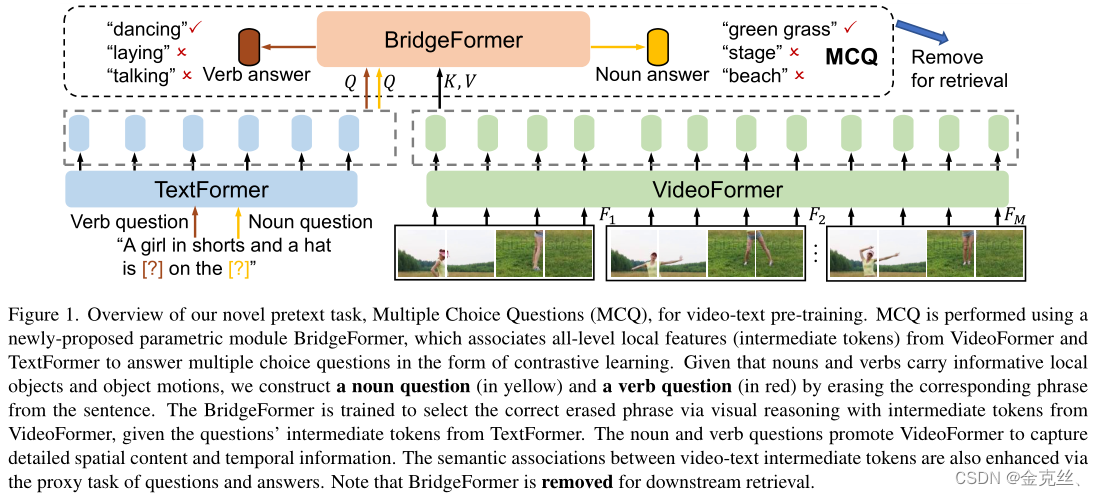
为了实现细粒度的视频文本交互,同时保持较高的检索效率,我们引入了一种新的用于视频文本预训练的参数化的pretext task,即多项选择问题(MCQ),它可以在所有特征级别(低级到高级的每一层的text/video token)上将文本与视频连接起来。如图1,BridgeFormer基于“dual-encoder”框架,通过对视频特征的视觉推理,训练其回答文本特征生成的“问题”,MCQ增强了每个模态内的局部特征学习以及跨模态的细粒度语义关联,并且在迁移到下游任务时,BridgeFormer可以很容易地移除。具体来说,我们通过从原始文本中删除内容短语来构建“问题”,正确的“答案”就是删除的短语本身,由于观察到文本中的名词和动词短语包含丰富的语义信息,可以分别反映视频中的局部对象和对象的运动信息,我们随机选择名词或动词作为内容短语,然后训练BridgeFormer以对比学习的形式,借助视频编码器编码的时空特征,从多项选择题(一个batch中删除的所有内容短语构成的答案集)中选择正确答案,这种训练目标强制视频编码器捕获准确的空间内容(回答名词)和时间信息(回答动词),提高局部特征的区分性以及局部视频patch和文本短语之间的语义关联。
BridgeFormer可以在所有特征级别上连接视频和文本特征(参考图5,例如低级、中级、高级的text/video token),即可以从视频和文本编码器中获取任何一个阶段的输出作为输入,直接应用于视频和文本特征,这不同于传统的“joint-encoder”对视频和文本特征进行聚合。因此,BridgeFormer仅用于预训练,可以无缝移除以进行下游检索任务,从而呈现出一个灵活高效的模型,就像传统的“Dual-encoder”方法一样,即视频和文本表示之间的相似性可以通过点积直接测量。
二、Related Work
Pre-training for video-text retrieval. 视频文本检索的主要预训练方法可分为两类。第一类【6、13、15、24、28、31、36、46、50】采用两个单独的编码器编码视频特征和文本特征,并投影到相同的潜在空间,然而,简单地对两种模态的最终特征([CLS] token)施加正则化会导致本地视频文本表示之间的交互不足。第二类【22、23、25、42、45、51】将文本和视频拼接作为联合编码器的输入,进行跨模态融合,然后训练二分类预测视频和文本是否对齐,尽管它们可以在视频文本标记之间建立局部关联,但在推理过程中,需要将每对视频和文本候选输入到模型中进行相似度计算,导致效率极低。相比之下,我们的方法获得了上述两种方法的优点,即实现细粒度视频文本交互,同时保持较高的检索效率。
The pretext task of masked word prediction. 先前的跨模态预训练工作[19,25,51]使用了 masked word prediction(MWP)的任务,它随机掩码句子中的一部分单词,并将网络正则化,以便在视觉输入条件下从固定词汇中预测掩码的词。我们引入的MCQ与MWP有两个不同之处:(1)MWP中的单词预测会对低级单词进行正则化,这可能会损害交互表征学习,因为网络还需要充当文本解码器。在我们的MCQ中,将答案与内容短语进行对比侧重于高级语义,显示出明显优于MWP的结果。(2) MCQ删除名词和动词短语来构建信息性问题,这反映了视觉特征中的显著语义信息,而MWP则随机掩码单词(例如,没有内容信息的虚词)。
Video question answering (VQA). 视频问答不能直接用于预训练,因为这仅仅是为了提高VQA准确性而特意优化的。相比之下,我们的工作旨在学习视频文本检索的下游不可知的泛型特征,以增强视频和文本之间的语义关联,我们是首次将VQA形式用作预训练。
Video-text retrieval with nouns and verbs. 【10,44,48,52】通过关注文本中的动词和名词来解决视频文本检索问题,这些动词和名词专门设计用于检索,以动词和名词作为精确的文本表示,直接与视频对齐。相比之下,我们利用文本中名词和动词的丰富语义来构建问题,以改进文本和视频编码器。
三、Method
3.1、Dual-encoder for Video-text Pre-training: a revisit
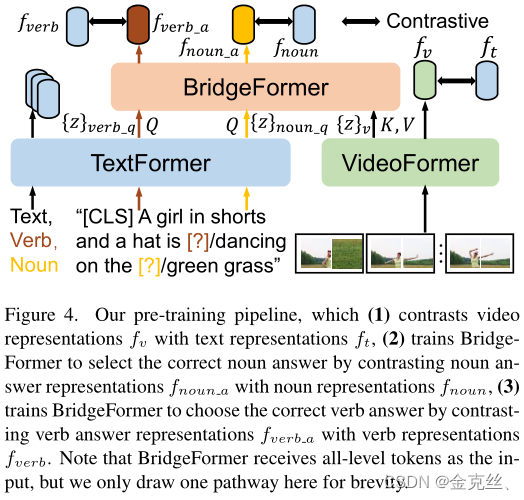
如图4所示,我们采用了dual-encoder结构,它包括一个用于从原始视频帧学习视频表示的VideoFormer和一个TextFormer。给定一个视频及其相应的文本描述(例如,“A girl in shorts and a hat is dancing on the green grass”),首先嵌入VideoFormer和TextFormer各自的表征,通过两个独立的线性层投影到fv和ft的公共嵌入空间,视频和文本之间的相似性通过fv和ft的点积计算,利用对比目标[18,30]最大化正对fv和ft之间的相似性,同时最小化负对fv和ft之间的相似性(视频及其相对应的文本描述被视为正对,否则视为负对),独立的双编码器路径只需要视频和文本表示之间的点积就可以进行检索中的相似性计算,从而保证了检索的高效性。
3.2、Multiple Choice Questions
如图1所示,使用BridgeFormer执行MCQ,将来自VideoFormer和TextFormer的所有级别中的token关联起来,以回答多项选择题。鉴于文本中的名词和动词短语携带着丰富的语义信息,可以分别反映视频中的局部对象和对象运动信息,我们随机删除一个名词或动词短语来构造名词或动词疑问句。然后训练BridgeFormer以对比学习的形式借助VideoFormer编码的视频特征,从多项选择(一个batch中删除的所有短语)中选择正确答案,MCQ涉及回答名词性问题和动词性问题的目标。
Answer Noun Question. 给定视频及其相应的文本描述(例如“A girl in shorts and a hat is dancing on the green grass”),随机删除一个名词短语(例如“grass”)作为名词问题(例如“A girl in shorts and a hat is dancing on the [?]”)。如图4所示,将名词问题输入到TextFormer得到中级text token
,中级的video token从VideoFormer中提取为
,BridgeFormer将名词问题token
和
,并通过点积计算其相似性。当
Answer V erb Question. 同上。
3.3、Pre-training Objectives
我们采用Noise-Contrastive Estimation(NCE)作为对比目标,并结合三个目标以端到端的方式优化整个模型,如下所示
![]()
其中,是视频表示
和文本表示
之间的NCE损失(3.1节所述),
是名词答案表示
和名词表示
之间的NCE损失(3.2节所述),
是动词答案表示
和动词表示
之间的NCE损失(3.2节所述),计算NCE损失如下:
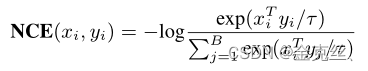
其中,B是batchsize,根据经验,τ设置为0.05。
3.4、Model Architecture
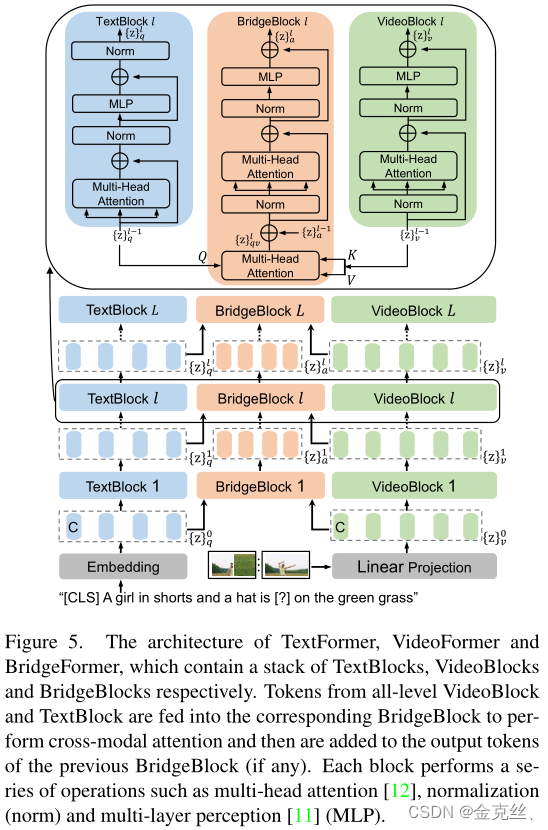
3.4.1、VideoFormer
Input. 视频输入
,经过划分patch,卷积展平得到序列video tokens
,D为编码维度,在序列首部添加[CLS] token用以获得视频表征,同时添加可学习的空间位置编码。
VideoBlock. 如图5,采用vit作为基础架构,进行一些修改以允许输入可变帧数量的视频。视频表征从最终视频的[CLS] token获得。
3.4.2、TextFormer
Input. TextFormer将三种自然语言作为输入,包括完整的文本描述、删除名词或动词短语的名词或动词疑问句、删除的名词或动词短语。[CLS] token连接到输入的开头,用于最终文本表示。
TextBlock. 我们采用multi-layer bidirectional transformer编码器[38]作为TextFormer,其由图5所示的文本块堆栈组成。
3.4.3、BridgeFormer
Input. BridgeFormer以TextFormer中的名词问题或动词问题token作为query,以VideoFormer中的video token作为key和value,获得具有跨模态的答案表示。
BridgeBlock. BridgeFormer基于vidion transformer构建,如图5所示。
四、Experiments
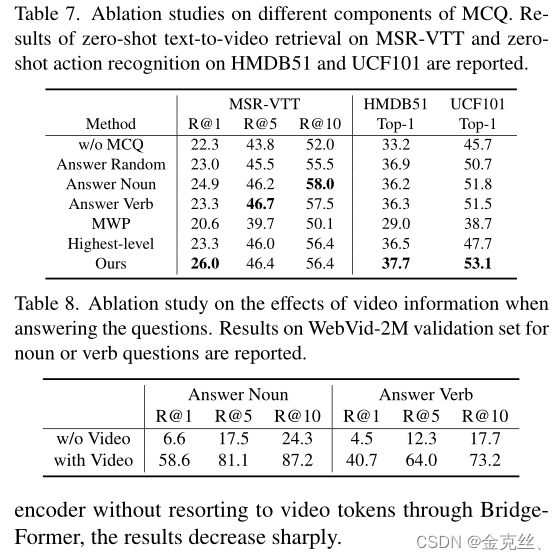
TextFormer采用DistilBERT[38]的架构。主要看下图的消融实验,还是效果还是挺显著的。
五、Conclusion
在这项工作中,我们引入了一种新的pretext task,用于视频文本预训练的多项选择问题(MCQ),它增强了局部视频和文本特征之间的细粒度语义关联,同时保持了检索的高效性。参数化的BridgeFormer经过训练,可以通过求助于视频特征来回答由文本特征构建的问题,并且可以很容易地删除以用于下游任务。
Limitation. (1) 现成的自然语言处理模型无法提取完全准确的名词和动词短语来构造问题。(2)在现有的视频文本数据集中,文本描述和相应的视频实际上可能错位,从而导致噪声监督。
Negative Social Impacts. 由于我们没有在预训练数据集中过滤出可能不合适的视频(例如,血液和暴力),因此我们的模型可以用于搜索传播的糟糕视频,利用预训练的模型过滤掉这些视频并重新训练模型会有所帮助。















 4427
4427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









