






关注公众号,发现CV技术之美

清明上河图
近日南方科技大学和腾讯ARC Lab开源了一款交互式图像描述工具, 基于Segment Anything, BLIP-2 Captioning和chatGPT实现, 通过视觉控制(鼠标点击)获取特定区域的object, 并以多样化的语言风格描述出来.
传统图像描述或密集描述通常以解析全图为目的, 如果遇到清明上河图等场景丰富且object交互特别复杂的图像, 一个简单的句子或非常长的段落, 对用户阅读很不友好. Caption Anything想看哪里即点击哪里, 根据用户需求定制化地关注局部区域, 进行细节描述及后续推理任务. 同时具有速度优势.
描述一幅图是一对多的映射, 不同用户对图像区域关注重点不同, 语言风格需求也不同. 面对如此多样的文本输出空间, 交互式控制模型输出可以与用户的需求更加对齐. 如下图所示, Caption Anything提供了视觉控制和语言控制.

Caption Anything支持视觉控制和语言控制
用户界面: 支持鼠标点击(连续或单次点击), 输出描述的语言风格控制(情感, 语种, 想象), 利用chatGPT输出物体对应的wiki知识, 同时支持chatGPT进行对话. 代码同时支持Linux和Windows平台.
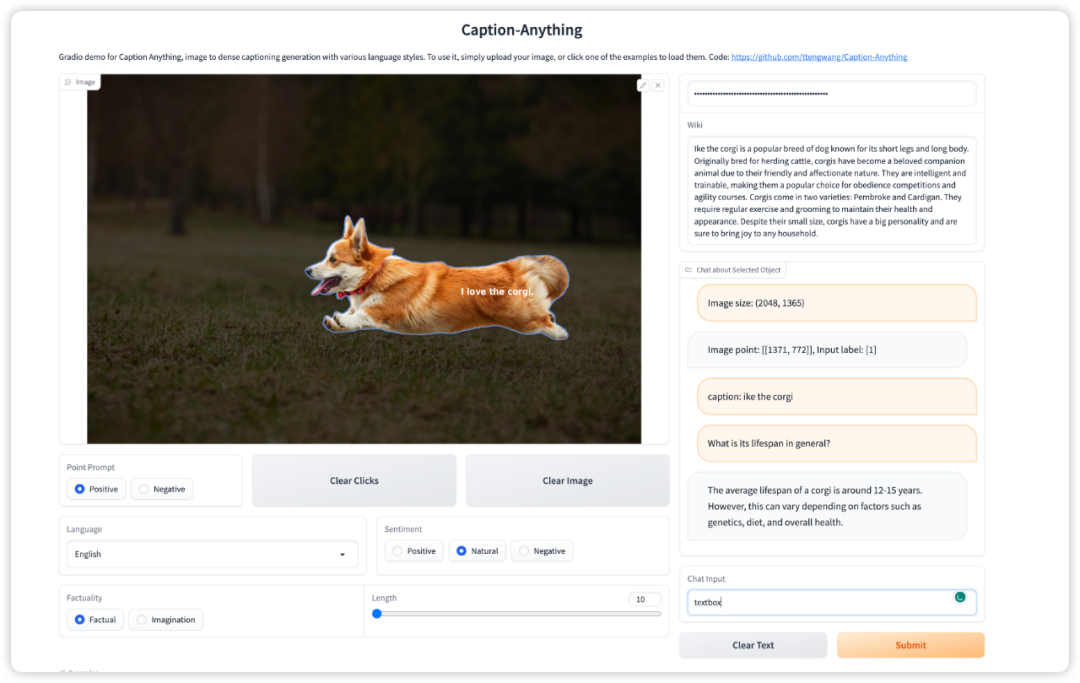
用户界面
Github: https://github.com/ttengwang/Caption-Anything
Hugging Face Demo: https://huggingface.co/spaces/TencentARC/Caption-Anything
本文为粉丝投稿。投稿邮箱 amos@52cv.net。
知乎链接:https://zhuanlan.zhihu.com/p/622314514

END
欢迎加入「图像字幕」交流群👇备注:IC



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









