






关注公众号,发现CV技术之美
本文由52CV粉丝投稿,原文地址:
https://zhuanlan.zhihu.com/p/650804162
本文是南方科技大学郑锋老师课题组(SUSTech, Visual Intelligence & Perception Lab)针对视觉-语言预训练模型的对抗鲁棒性的研究。文章名称为 『Set-level Guidance Attack: Boosting Adversarial Transferability of Vision-Language Pre-training Models』,发表在 ICCV 2023,收录为 Oral。

文章链接:https://arxiv.org/abs/2307.14061
开源代码:https://github.com/Zoky-2020/SGA
本文关注对抗样本在视觉-语言预训练模型之间的迁移能力。文中将单一的图像-文本对扩展为集合级别的图像-文本对,并使用跨模态数据为监督信息来生成对抗样本。该方法大幅度地提升了对抗样本的跨模型迁移能力。
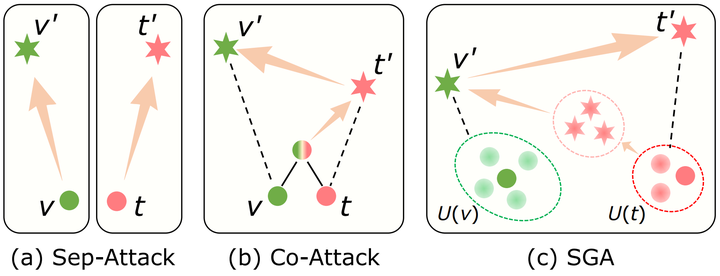
1.简介
视觉-语言预训练(VLP)模型在诸多任务上都取得了 SOTA 的性能。尽管如此,近期的工作[1][2]表明在白盒场景下VLP模型面对恶意攻击时仍然表现出脆弱性。然而,在贴近现实的黑盒场景下,VLP模型的鲁棒性仍有待进一步挖掘,这对于VLP模型在现实场景中的安全部署具有重要意义。
本文从对抗迁移性的角度出发,首次探索 VLP 模型在黑盒场景下的对抗鲁棒性。作者首先评估了现有方法在基于 VLP 模型的多模态场景下的对抗迁移性,实验结果表明,现有的单模态攻击和多模态白盒攻击方法,都不足以生成具有强迁移性的对抗样本。作者将这种迁移性差的问题归结为现有方法在多模态任务下的局限性:缺少模态间交互和样本多样性不足。
为进一步提升多模态对抗样本的跨模型迁移能力,作者提出了一种集合级引导攻击(Set-level Guidance Attack, SGA)方法。该方法将单一地图像-文本对扩展为集合级别的图像-文本对,并以跨模态数据为监督信息,从而生成具有强迁移性的对抗样本。实验结果表明,SGA 能大显著提升对抗样本的跨模型迁移能力。
2.观测现象
首先,本文评估了现有的对抗攻击方法(Sep-Attack, Co-Atttack)在基于 VLP 模型(ALBEF, TCL, CLIP)的多模态任务下的性能。其中 Co-Attack 为针对 VLP 模型的多模态对抗攻击方法,Sep-Attack 为现有的单模态对抗攻击方法(PGD + Bert-Attack)的组合。以下实验在图-文检索任务上进行,数据集为 Flickr30k。更多实验及分析请参见原文。
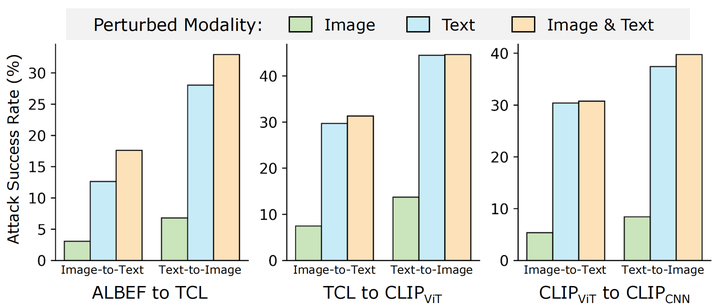

本文观察到:(1)同时攻击图像和文本相较于单独攻击图像或文本具有更好的迁移性(如图1);(2)白盒场景下具有高攻击性的对抗样本迁移到黑盒模型时,其攻击性会大幅下降(如图2)。
基于实验观察,本文认为这种迁移性的降低主要源于现有方法对多模态数据的不充分利用:(1)不同于单模态任务,VLP 模型依赖多模态数据间的交互。(2)多模态任务中,通常存在一对多、多对多的跨模态数据对齐(例如,一张图像对应多个文本描述)。Sep-Attack 等简单地结合单模态攻击方法的策略,并没有充分利用到多模态间的交互信息。对抗样本在多模态任务中的攻击效果应该体现在对于模态交互的破坏。而 Co-Attack 虽然考虑了多模态交互,但其使用单一的图像-文本对生成对抗样本,忽视了多对多的跨模态交互。因此,尽管现有方法生成的对抗样本在白盒模型上具有攻击性,但很难迁移到其他模型。
3.方法介绍
本文提出集合级指导攻击(Set-level Guidance Attack, SGA),该方法包含两个部分:集合级数据增强和跨模态引导攻击。
3.1 集合级数据增强
对于干净的图像-文本样本对 (,t),本文在保持语义对齐的前提下,将其扩展为集合级的图像-文本对 (v,t)。对于图像,首先将其缩放到不同的尺度 S={,,...,},随后添加高斯噪声以引入随机性,得到多尺度的图像集合 V={,,...,}。对于文本描述 t,直接从数据集中选取与图像 最匹配的M个文本描述,得到文本描述集合 t={,,...,}。(v,t) 中任意一组图像-文本对都保持了语义对齐。图像-文本集合 (v,t) 用于生成对抗样本 (',t')。
3.2 跨模态引导攻击
为进一步提升对抗样本的迁移性,本文提出跨模态引导攻击的策略,以充分利用集合级数据中的模态交互。具体来说,本文使用来自不同模态的配对数据作为监督信号来引导对抗样本的优化方向。在迭代优化对抗图像和对抗文本的过程,该策略逐步拉远图像和文本在特征空间中的距离,从而破坏跨模态交互,达到攻击效果。
首先,为文本集合 t 中的每一个文本描述生成对应的对抗文本,得到对抗文本集 t'={',',...,'},
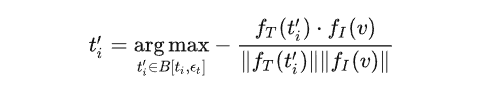
首先,为文本集合 t 中的每一个文本描述生成对应的对抗文本,得到对抗文本集 t'={',',...,'},
其中 B[,] 指 的 邻域,为对抗样本 ' 的搜索空间。该过程约束每一个对抗文本在特征空间中远离图像 。随后,基于对抗文本集生成对抗图像 ' ,
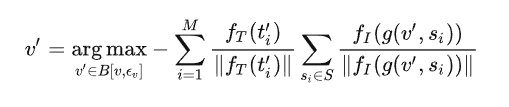
其中 B[,] 指 的 邻域,为对抗样本 ' 的搜索空间。该过程约束图像集 v 中的所有图像在特征空间中远离对抗文本集 t' 中的所有对抗文本。基于对抗图像 ' 生成对抗文本,
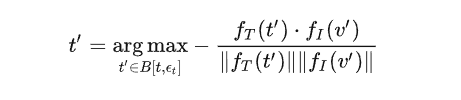
该过程约束 t' 在特征空间中远离对抗图像 v' 。
4.实验
4.1 迁移性分析
为了评估现有的方法基于 VLP 模型所生成的对抗样本的迁移性,本文选取了 Sep-Attack 和 Co-Attack 两种方法作为基准,同时尽可能地结合已有的、针对对抗迁移性的单模态攻击方法(MI[3], DIM[4], PNA_PO[5])。
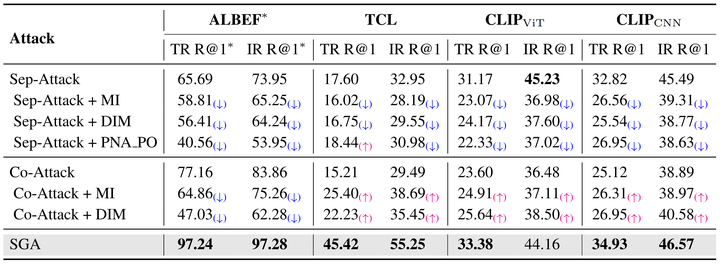
实验结果如表1所示,现有的对抗攻击方法虽然在白盒场景下能取得很好的攻击效果,但是其生成的对抗样本很难迁移到其他的黑盒模型。尽管结合不同的单模态迁移攻击方法,所生成的对抗样本的迁移性的提升依然有限。
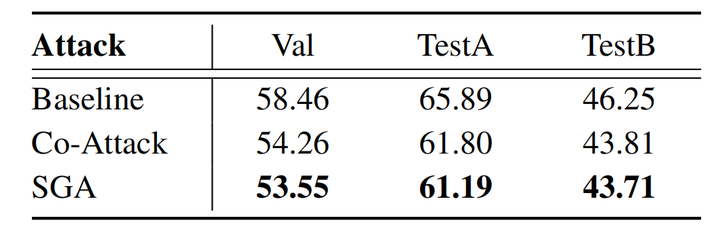
4.2 SGA跨模型迁移性
为了验证 SGA 生成的对抗样本在 VLP 模型上的迁移能力,本文在四个 VLP 模型(ALBEF, TCL, CLIP-ViT和CLIP-CNN),两个多模态数据集(Flickr30k 和 MS COCO)上进行了实验。实验结果如下表所示,
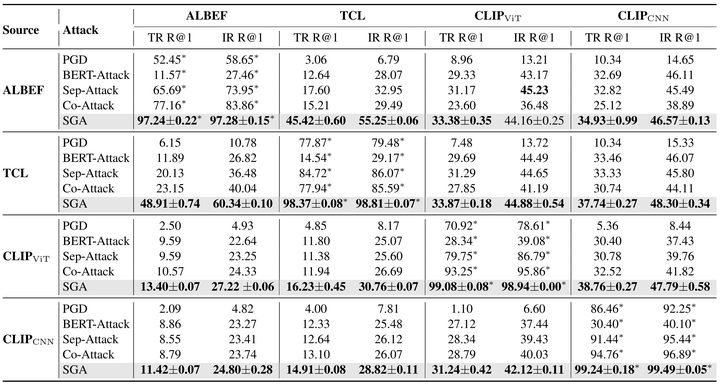
实验结果表明,相较于现有的对抗攻击方法,SGA 能够大幅度提升对抗样本在 VLP 模型之间的迁移性,特别是同类型的 VLP 模型之间的迁移性,例如从 ALBEF 到 TCL。
4.3 SGA跨任务迁移性
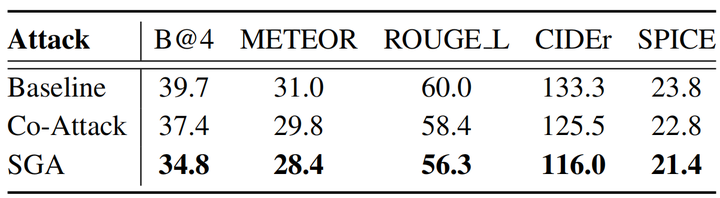
此外,本文验证了基于 SGA 所生成的对抗样本的跨任务迁移能力,例如源模型用于图-文检索任务,而目标模型用于图片描述任务。如表3, 4所示,SGA 基于图文检索模型索生成的对抗图片迁移到其他任务模型时,仍然具有攻击性,进一步表明 SGA 有效地破坏了多模态数据之间的信息交互。
4.4 消融实验
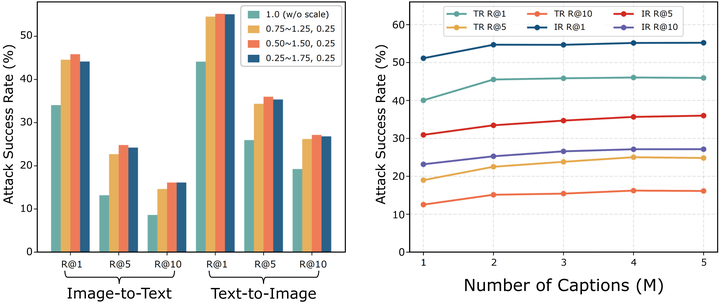
本文对 SGA 中图像集和文本集的大小进行了消融实验。实验结果如图3(左)所示,逐步增加集合中图像尺度的多样性时,能够提升最终生成的对抗样本的迁移性。如图3(右),相较于单张图像表述,使用集合级的图像文本描述来生成对抗样本能显著提升迁移性。
4.5 对抗样本可视化
对抗样本的可视化如图4所示。为了可视化效果,本文将对抗图像的扰动做了×50 的放大处理。

5.总结
本文首次探索了视觉-语言预训练(VLP)模型中的对抗迁移性。文中通过实验观测到现有方法生成的对抗样本在 VLP 模型间迁移性不足,并揭示了当前对抗攻击方法在多模态场景中的局限性。进而,本文提出集合级引导攻击,引入集合级数据增强和跨模态引导攻击。实验结果表明,该方法大幅度地提升了对抗样本在 VLP 模型间的迁移性。
[1] Jiaming Zhang etc. Towards Adversarial Attack on Vision-Language Pre-training Models.
[2] Jielin Qiu etc. Are Multimodal Models Robust to Image and Text Perturbations?
[3] Yinpeng Dong etc. Boosting Adversarial Attacks with Momentum.
[4] Cihang Xie etc. Improving Transferability of Adversarial Examples with Input Diversity.
[5] Zhipeng Wei etc. Towards Transferable Adversarial Attacks on Vision Transformers.

END
欢迎加入「视觉语言」交流群👇备注:VL



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









