






关注公众号,发现CV技术之美
本文转自机器之心。
第一个针对「Segment Anything」大模型的域适应策略来了!相关论文已被CVPR 2024 接收。
引言
大语言模型(LLMs)的成功激发了计算机视觉领域探索分割基础模型的兴趣。这些基础分割模型通常通过 Prompt Engineer 来进行 zero/few 图像分割。其中,Segment Anything Model(SAM)是最先进的图像分割基础模型。

图 SAM 在多个下游任务上表现不佳
但是最近的研究表明,SAM 在多种下游任务中并非具有很强的鲁棒性与泛化性,例如在医学图像、伪装物体、添加干扰的自然图像等领域表现较差。这可能是由于训练数据集与下游的测试数据集之间存在较大的域差异(Domain Shift)所致。因此,一个非常重要的问题是,如何设计域自适应方案,使 SAM 在面对现实世界和多样化的下游任务中更加鲁棒?
将预训练好的 SAM 适应到下游任务主要面临三个挑战:
首先,传统的无监督域自适应范式需要源数据集和目标数据集,由于隐私和计算成本较为不可行。
其次,对于域适应,更新所有权重通常性能更好,同时也受到了昂贵的内存成本的限制。
最后,SAM 可以针对不同种类、不同颗粒度的提示 Prompt,展现出多样化的分割能力,因此当缺乏下游任务的提示信息时,无监督适应将非常具有挑战性。
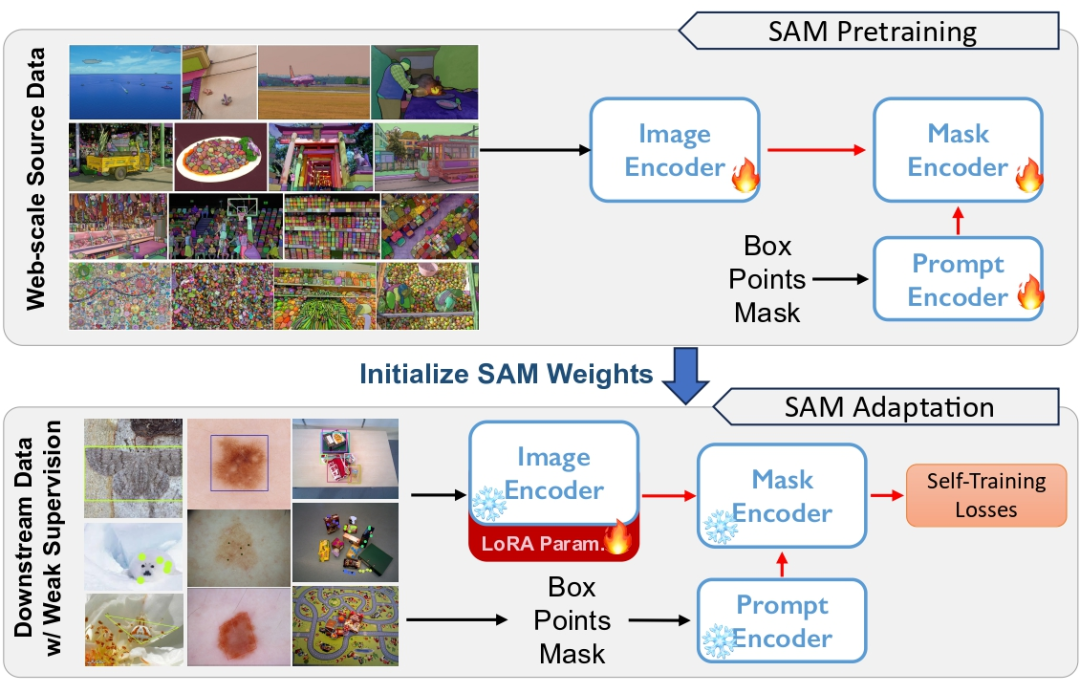
图 1 SAM 在大规模数据集上进行预训练,但存在泛化性问题。我们使用弱监督的方式在各种下游任务上对 SAM 进行自适应
为了应对上述挑战,我们提出了一种具有锚点正则化和低秩微调的弱监督自训练架构,以提高自适应的鲁棒性和计算效率。
具体而言,我们首先采用无源域的自训练策略,从而避免对源数据的依赖。自训练产生伪标签,用于监督模型的更新,但是容易受到错误伪标签的影响,我们引入冻结的 source model 作为锚定网络,以规范模型的更新。
为了进一步减少更新完整模型权重的高计算成本,我们对编码器应用低秩权重分解,并通过低秩快捷路径进行反向传播。
最后,为了进一步提高无源域自适应的效果,我们在目标域引入了弱监督(weak supervise),例如稀疏的点注释,以提供更强的域适应信息,同时这种弱监督与 SAM 中的提示编码器自然兼容。
借助弱监督作为 Prompt,我们获得了更局部、更明确的自训练伪标签。经过调整的模型在多个下游任务上表现出了更强的泛化能力。
我们总结本工作的贡献如下:
1. 我们受到 SAM 在下游任务中泛化问题的启发,提出了一种与任务无关且无需源数据的解决方案,通过自训练来适应 SAM。
2. 我们利用弱监督,包括 box、point 等标签,以提高自适应效果。这些弱监督标签与 SAM 的提示编码器完全兼容。
3. 我们对 5 种类型的下游实例分割任务进行了大量实验,证明了所提出的弱监督自适应方法的有效性。

论文地址:https://arxiv.org/pdf/2312.03502.pdf
项目地址:https://github.com/Zhang-Haojie/WeSAM
论文标题:Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
方法
方法介绍分为四个部分:
Segment Anything 模型
基于自训练的自适应框架
弱监督如何帮助实现有效的自训练
低秩权重更新
1.Segment Anything Model
SAM 主要由三个组件构成:图像编码器(ImageEncoder)、提示编码器(PromptEncoder)、和解码器(MaskDecoder)。
图像编码器使用 MAE 进行预训练,整个 SAM 在拥有 11 亿标注的训练集 SA-1B 上进一步进行微调,训练时使用了 Focal loss 和 Dice loss 的组合。推理时,测试图片 x 首先由图像编码器进行编码,然后给定提示 Prompt,轻量级的解码器将进行三个级别的预测。
2.Source-Free 域适应自训练
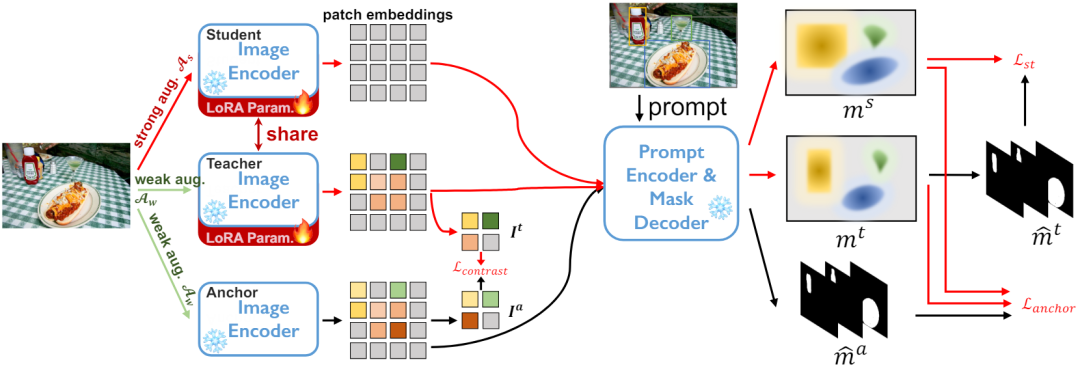
图 2 所提出的具有锚定网络正则化和对比损失正则化的自训练架构
针对未提供标记的目标数据集 DT={xi} 和预训练的分割模型。我们采用了 student-teacher 架构进行自训练。如图 2 所示,我们维护三个编码器网络,即 anchor model、student model、teacher model,其中 student 和 teacher model 共享权重。
具体来说,对于每个样本 xi,应用一个随机的弱数据增强作为 anchor 和 teacher model 的输入,应用一个随机的强数据增强作为 student model 的输入,三个编码器网络编码产生三个特征图。
在解码器网络中,给定一定数量 Np 的提示 prompt,例如 box、point 或 coarse mask,将推理出一组实例分割的 masks。
基于以上知识,我们下面详细阐述用于自训练的三组优化目标。
1) Student-Teacher 自训练
我们首先使用与训练 SAM 时相同的损失函数作为自训练优化目标来更新 student/teacher model。自训练广泛应用于半监督学习,最近还被证明了对无源域自适应非常有效。具体而言,我们使用 teacher model 产生的预测结果,作为伪标签(Pseudo label),并使用 Focal loss 和 Dice loss 来监督 student 的输出。
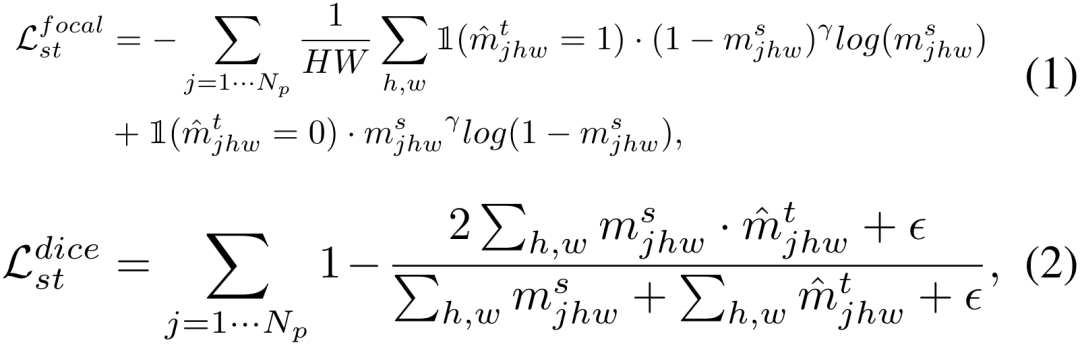
2) Anchor 损失用于鲁棒正则化
仅使用自训练损失进行网络训练容易受到 teacher 网络预测的错误伪标签积累的影响,即所谓的确认偏差。观察也表明,仅使用自训练长时间迭代后性能会下降。现有的无源域自适应方法通常采用额外的约束来防止自训练的负面影响,例如对预测进行均匀分布。
我们通过 anchor 损失来进行正则化,如公式 3 所示,分别最小化了 anchor model 与 student/teacher model 之间的 Dice loss。冻结的 anchor model 作为从源域(source domain)继承的知识,不鼓励源模型和自训练更新模型之间出现过大的偏差,可以防止模型崩溃。
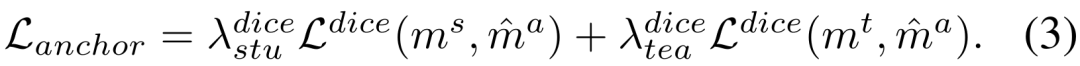
3) 对比损失正则化编码器特征空间
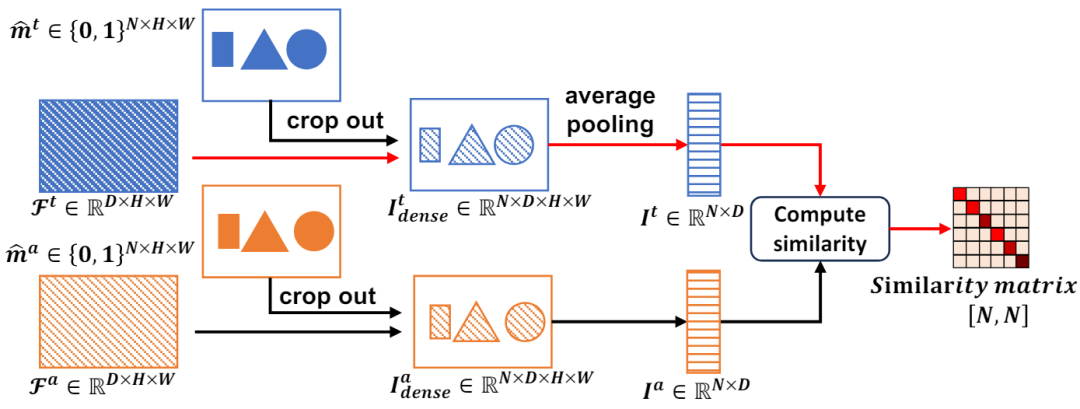
图 3 两个分支下的对比损失
以上两个训练目标是在解码器的输出空间中执行的。实验部分揭示出,更新编码器网络是适应 SAM 最有效的方法,因此有必要直接对从编码器网络输出的特征应用正则化。具体如图 3 所示,我们根据 anchor 和 teacher 分支中预测 mask 从特征图中裁剪出每个实例的特征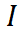 。
。
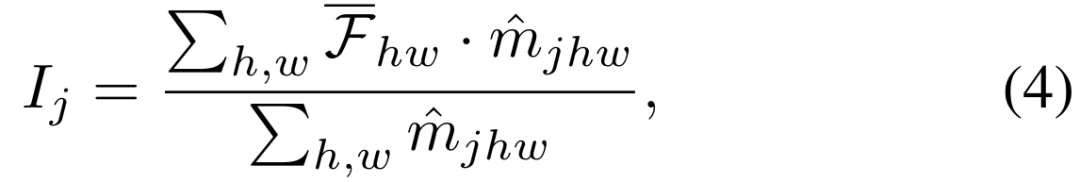
我们进一步定义对比损失中的正负样本对,正样本对是由两个分支中使用相同的 prompt 对应的实例特征构建,而负样本对是由不同 prompt 对应的实例特征来构建的。最终的对比损失如下所示,其中 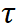 是温度系数。
是温度系数。
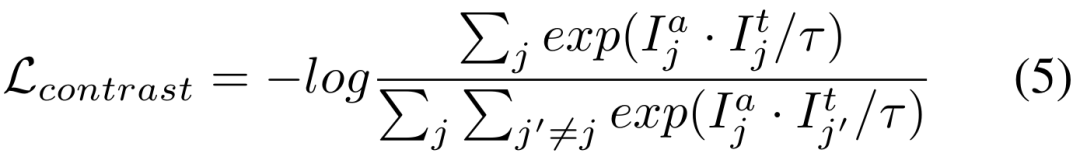
4) 总损失
我们将上述三个损失函数组合成最终的 Source-Free 自适应损失。
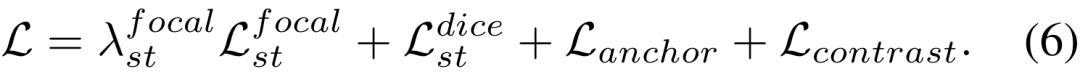
3. 自训练的 Prompt 生成
SAM 分割需要 Prompt 输入来指示出待分割的目标对象,但可能会存在颗粒度模糊的问题。Prompt 工程可以以完全自动化的方式实现,也可以通过人工交互实现。
1) 完全自动生成 Prompt
我们首先使用网格密集采样点作为 prompt 输入,通过 Anchor model 生成初始阶段分割的 masks,剔除 IoU 和稳定性得分低的 mask,然后进行非极大值抑制来获得分割结果。接下来从最终的 masks 中产生一组固定的 prompts,作为所有三个分支的 prompt 输入。因此,三个网络分割输出的 mask 长度相同,并且具有精确的一对一对应关系。
2) 弱监督作为 Prompt
尽管可以通过在图像上使用网格采样获得 prompts,并过滤掉质量低和重复的 mask 来进行自动分割。但这些分割质量相对较差,可能包含许多误报预测,并且颗粒度不明确。由此产生的 prompt 质量参差不齐,使得自训练效果较差。
因此,借鉴先前的弱监督域自适应工作,我们提出使用三种弱监督方式,包括边界框 box、稀疏点标注 point 和粗分割多边形 coarse mask。在 SAM 中,这些弱监督方式与 prompt 输入完美匹配,可以无缝集成弱监督以适应 SAM。
4. 低秩权重更新
基础模型庞大的编码器网络使得更新所有模型的权重变得异常困难。然而,许多现有研究表明,更新编码器网络权重是调整预训练模型的有效方法。
为了能够更加有效且低成本地更新编码器网络,我们选择了一种计算友好的低秩更新方法。对于编码器网络中的每个权重 θ,我们使用低秩近似 ω = AB,并设定一个压缩率 r。只有 A 和 B 通过反向传播进行更新以减少内存占用。在推理阶段,通过将低秩近似和原始权重组合来重构权重,即 θ = θ + AB。
实验
在实验中,我们提供了与最先进方法的详细比较和定性结果。最后,我们分析了各个部分的有效性以及网络的具体设计。
1. 数据集
在这项工作中,我们对五种不同类型的下游分割任务进行评估,其中一些与 SA-1B 存在明显的分布偏移。数据集涵盖了清晰的自然图像、添加干扰的自然图像、医学图像、伪装物体和机器人图像,总计 10 种。
数据划分:每个下游数据集被划分为互不重叠的训练集和测试集。
表 1 中列出了每种类型下游任务所评估的数据集,以及训练和测试数据集的划分。

2. 实验细节
Segment-Anything 模型:由于内存限制,我们采用 ViT-B 作为编码器网络。采用标准提示编码器和 mask 解码器。
Prompt 生成:训练和评估阶段的 Prompt 输入均是由从实例分割 GT mask 计算而来,模拟人类交互作为弱监督。
具体来说,我们从整个 GT mask 的最小边界框中提取 box。Point 是通过在 GT mask 内随机选择 5 个正样本点和 5 个 mask 外的负样本点创建的。Coarse mask 是通过将多边形拟合到 GT mask 来模拟的。
3. 实验结果
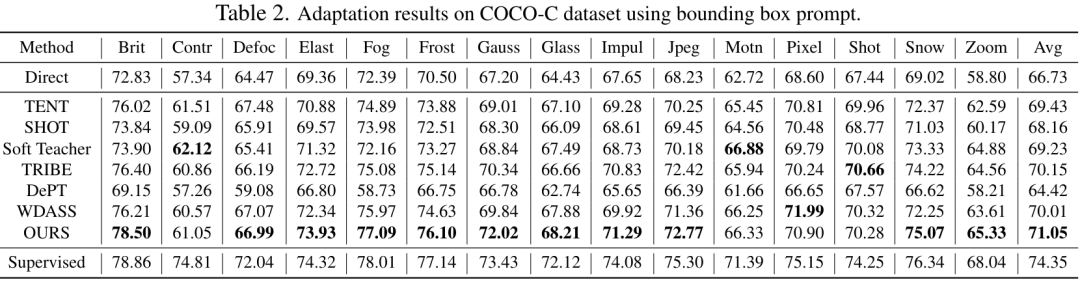
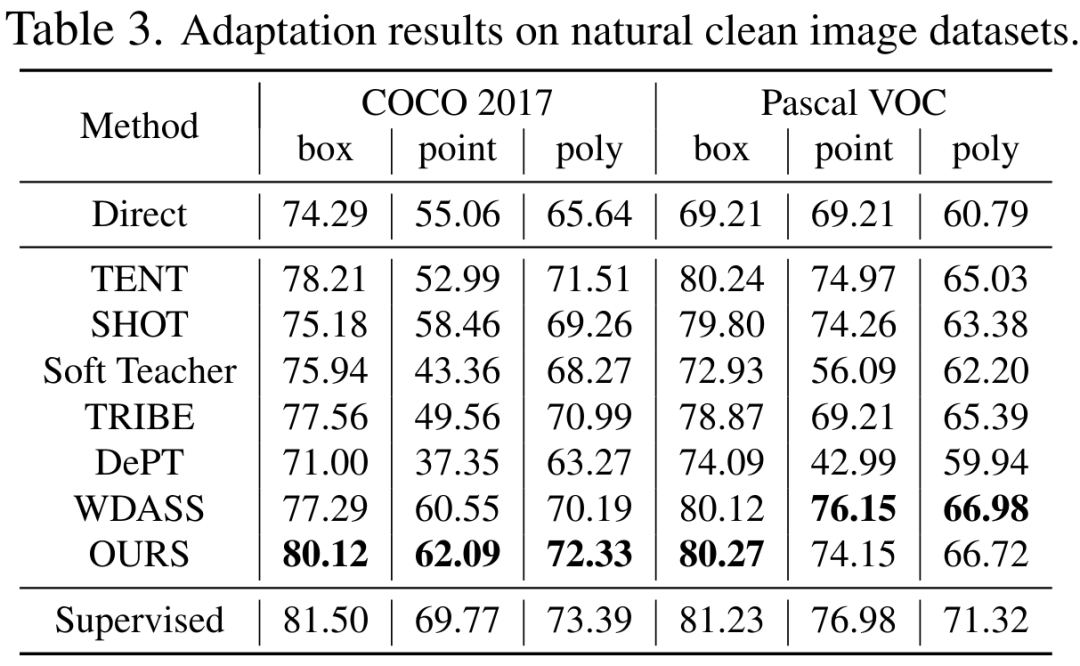
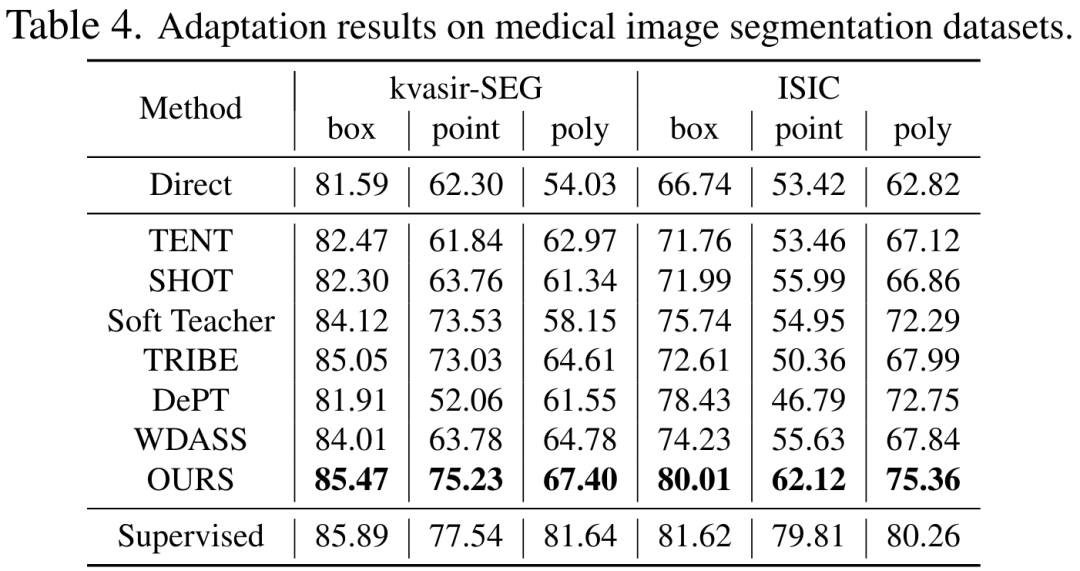
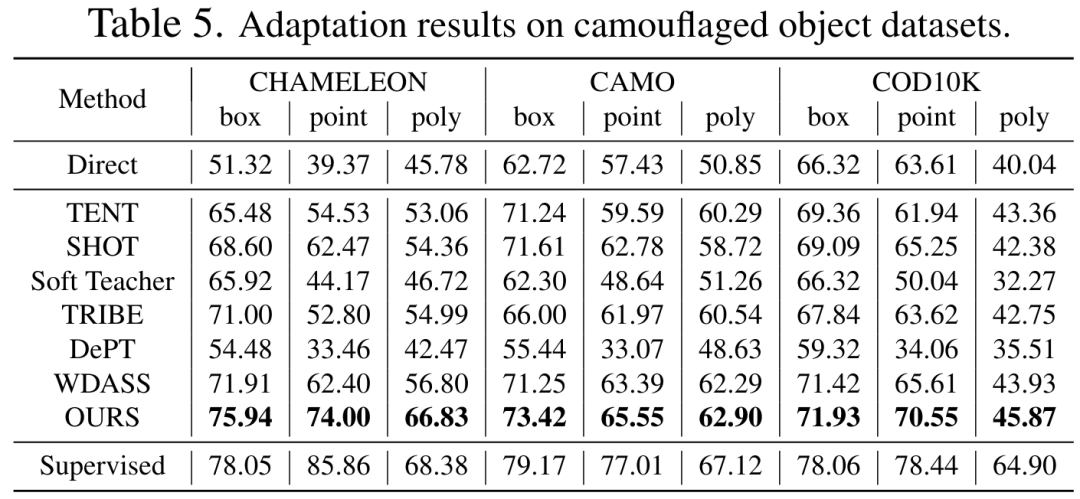
表 2、3、4、5 分别是在添加干扰的自然图像、清晰的自然图像、医学图像、伪装物体数据集上的测试结果,完整的实验结果可以在论文中找到。实验证明了我们的方案在几乎所有的下游分割数据集上都优于预训练的 SAM 和最先进的域适应方案。
4. 可视化结果
部分可视化结果如图 4 所示,更多的可视化结果可以在论文中找到。


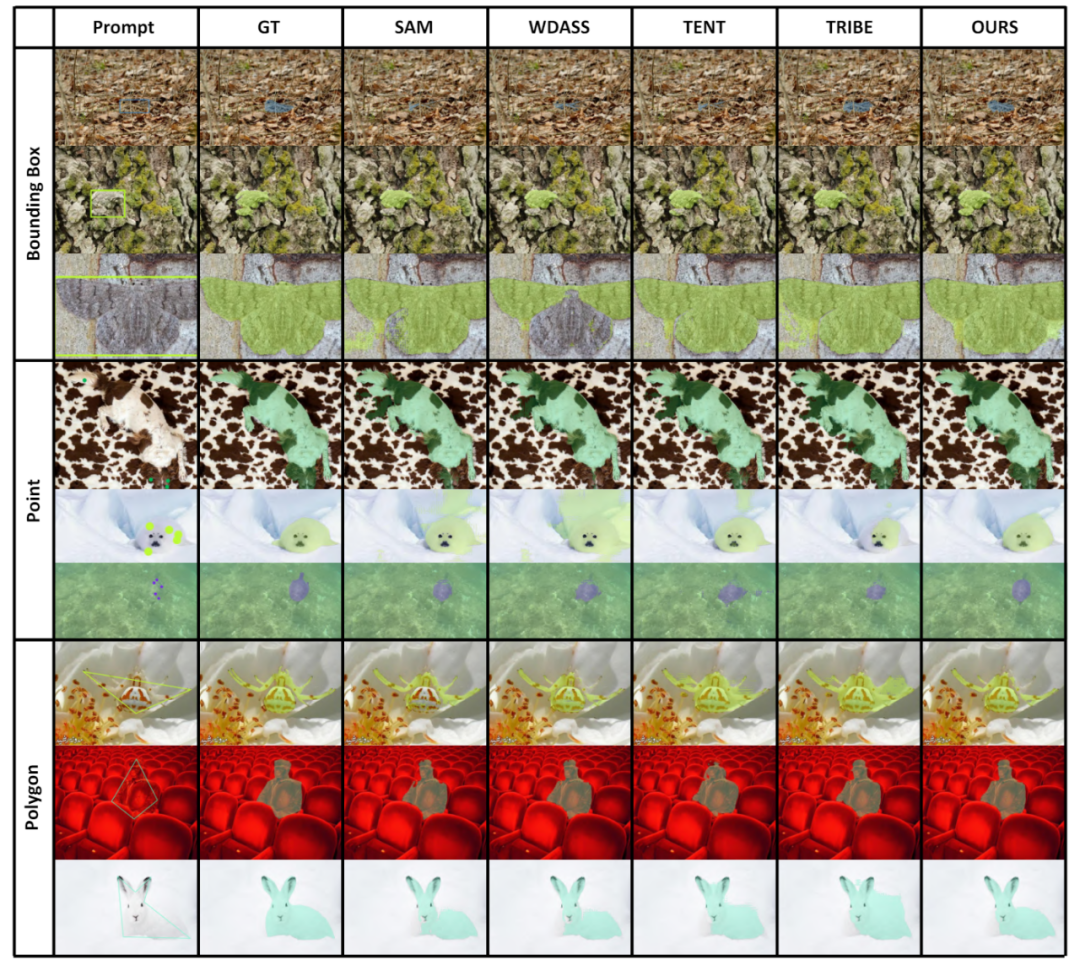
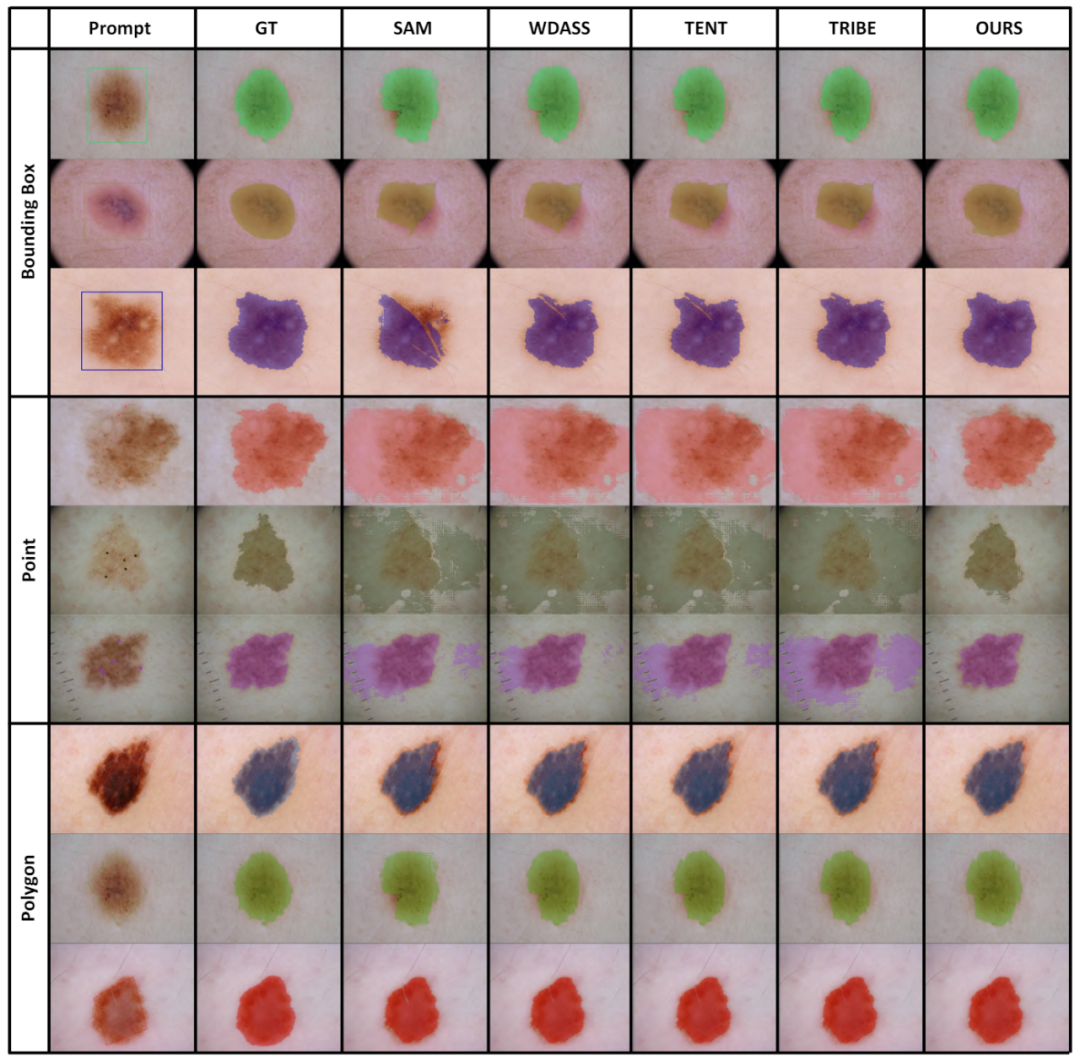
图 4 部分实例的可视化结果
5. 消融实验和额外分析
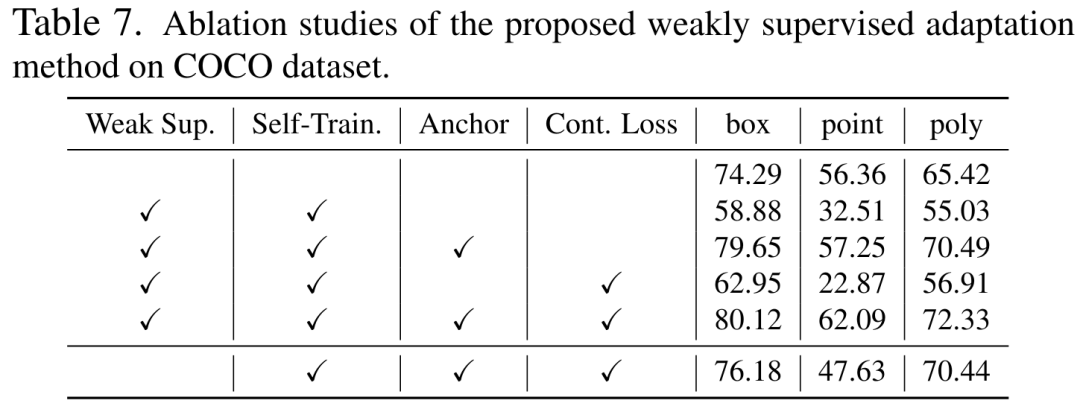
我们在 COCO 数据集上分析了三个自训练优化目标各自的有效性,如表 7 所示。表 7 中,我们还分析了所提出方法在不使用任何弱监督信息时进行自适应的效果。
我们分析了训练和测试使用不同类别的 prompt 的性能差异,如表 8 所示。实验表明我们的方案在 cross-prompt 条件下依然表现良好。

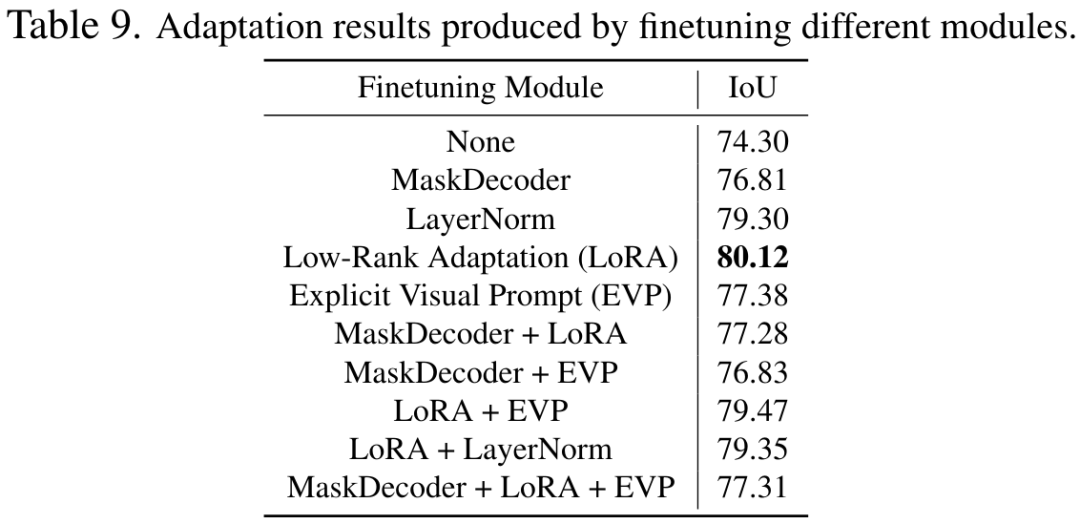
此外,我们还分析了优化不同模块,包括解码器、LayerNorm 和不同的 finetune 方案以及他们的组合的实验结果,实验证明了 finetune 编码器的 LoRA 方案效果最佳。
总结
尽管视觉基础模型可以在分割任务上表现出色,但其在下游任务中仍会存在性能不佳的情况。我们研究了 Segment-Anything 模型在多个下游图像分割任务中的泛化能力,并提出了一种基于锚点正则化和低秩微调的自训练方法。该方法无需访问源数据集、内存成本低、与弱监督自然兼容,可以显著提升自适应效果。经过广泛的实验验证,结果表明我们提出的域适应方法可以显著改善 SAM 在各种分布迁移下的泛化能力。

END
欢迎加入「SAM」交流群👇备注:SAM















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









