






关注公众号,发现CV技术之美
本篇分享论文From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation。
导⾔
在⼈体图像可控⽣成领域,尽管在控制姿态和⼈物⾝份等⽅⾯取得了显著进展,但要通过不同⼈体部位实现精准控制仍⾯临重⼤挑战,尤其是在涉及多重可控条件时,控制效果往往难以保证。
针对这⼀问题,北京航空航天⼤学的研究团队提出了⼀种新颖的研究⽅法“从部分到整体”(Parts2Whole)。这项技术能够利⽤多个参考图像,包括姿势图和不同的⼈体部位外观,⽣成⾼度可控的⼈体图像。
该研究⽅法的核⼼在于其创新的语义感知外观编码器,共享⾃注意⼒机制和掩膜引导的主题选择机制,使得从多个参考图像中精确抽取⽬标特征成为可能。

项⽬主⻚:https://huanngzh.github.io/Parts2Whole/
Github链接:https://github.com/huanngzh/Parts2Whole
Parts2Whole做的任务是什么?
在图像⽣成领域,可控的⼈体⽣成技术正逐步展现其重要性。这⼀技术不仅能够按照特定的⽂本描述或结构信号(⽐如姿态等信息)来合成⼈像,还能够根据更精确的外观条件(⽐如⼈脸)进⾏调整,从⽽为⽤户提供了⼀种全新的定制化肖像解决⽅案。
然⽽,当前的研究主要集中在使⽤单⼀图像或⽂本条件进⾏⽣成,难以同时控制多种⼈体外观特征的合成,这些⽅法往往忽视了如发型、服装等其他关键外观特征的综合控制,且在保持⽣成图像与多部分条件⼀致性上仍存在挑战。

针对以上问题,研究者们提出了⼀个全新的框架:Parts2Whole。该框架旨在实现从多个参考图像中⽣成⾼质量、⾼⼀致性的完整⼈体图像,这些参考图像可以包括不同的⼈体部分,如头发/头饰、⾯部、服装和鞋⼦等。
Parts2Whole不仅可以从多个不同⼈体部分来进⾏完整⼈体图像的⽣成,还可以使⽤不同数量的⼈体部分进⾏⽣成,⽐如可以只根据⼀张⼈脸的参考图像进⾏⽣成,也可以使⽤⼀个⼈脸加衣服的参考图像作为控制条件来进⾏⽣成。
总的来说,Parts2Whole可以根据不同数量的⼈体部分图作和给定的⽬标姿态图,⽣成与控制条件⾼⼀致性,⾼质量的⼈体图像。
Parts2Whole是如何构建数据的?

研究者在开源数据集 DeepFashion-MultiModal 的基础上进⾏了后处理操作,主要包括:
对数据集进⾏id清洗;
使⽤清洗后的同⼀id,同⼀⾐服,不同姿态的⼈体图像来构建训练对(pair);
提取对应图像的⼈体姿态(pose)图;
根据⼈体解析图(human parsing) 来指导分割;
分割后的参考图像进⾏图像超分。
最终构建出约41,500条数据。
Parts2Whole的关键技术是什么?
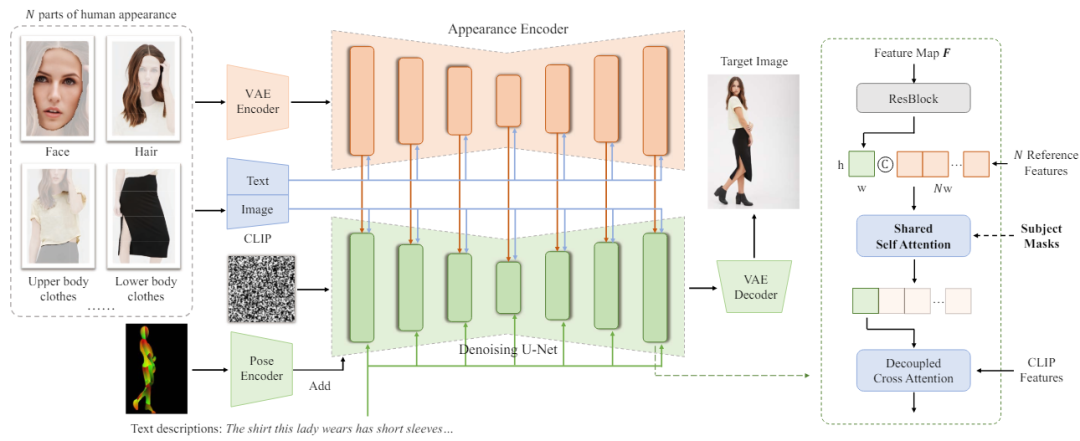
Parts2Whole采⽤了⼀种独特的语义感知外观编码器,该编码器能够将每个参考图像及其⽂本标签编码成多尺度的特征图,保留了丰富的外观细节和空间信息。此外,通过在扩散过程中使⽤共享⾃注意⼒机制,该框架能够在保持参考特征的位置关系的同时,将这些特征精确地注⼊到图像⽣成过程中。同时,为了更精确的从参考图像中选取关键特征,Parts2Whole还提出了增强的遮罩引导主体选择机制。
语义感知外观编码器(Semantic-Aware Appearance Encoder)
语义感知外观编码器是框架的⼀个关键部分,它可以处理多个参考图像,每个图像对应不同的⼈体部分(如头发、⾯部、上⾝⾐物等)。每个参考图像及其对应的⽂本标签被编码成⼀系列多尺度的特征图。这种编码⽅式不仅保留了图像的细节和空间信息,还通过⽂本标签提供了类别指导,帮助编码器理解不同部分的语义信息,从⽽更好地保持图像的细节和现实感。这⼀过程采⽤了与去噪U-Net相同的⽹络结构,并使⽤了预训练的权重。
共享⾃注意⼒机制(Shared Self-Attention)
在获取了N个参考图像的多层特征图之后,框架并不是简单地将这些特征直接加⼊去噪UNet,⽽是采⽤共享的键(keys)和值(values)在⾃注意⼒层中进⾏特征注⼊。这种设计允许每个特征位置不仅关注⾃⾝的特征,还能关注其他参考图像的特征,且该注意⼒操作在图像维度开展,能够保留参考图像的外观细节。此外,通过借鉴IP-Adapter在Stable Diffusion模型中额外加⼊的交叉注意⼒层,可以进⼀步引⼊参考图像的CLIP特征和⽂本输⼊,增强⽣成图像的控制能⼒。
增强的遮罩引导主体选择(Enhanced Mask-Guided Subject Selection)
为了从多个参考图像中精确选择⽬标部分,框架增加了⼀个遮罩引导的⾃注意⼒机制。这个机制通过引⼊参考图像中的主体遮罩,可以更准确地将注意⼒限定在特定的部分,避免由于背景或其他不相关元素的⼲扰导致⽣成的⼈体图像出现不⾃然的外观。这⼀设计不仅提⾼了⽣成图像的质量,也增强了对⽣成过程的控制性和精确性。
通过这个统⼀参考框架,Parts2Whole能够有效地处理和整合多个参考图像的特征,⽣成与输⼊条件⾼度⼀致且细节丰富的⼈体图像,显著提⾼了⼈像⽣成技术的灵活性和实⽤性。
Parts2Whole的效果怎么样?

研究者在构建数据中的测试集上进⾏了实验,可以看出Parts2Whole能够从多个参考图像中精准的提取出颜⾊、纹理和图案细节,具有较⾼的图像⽣成质量。
Parts2Whole还可以根据不同⼈物的图⽚部分来组合定制全⾝图像和⽀持任意的控制条件数量。
轻松定制全⾝图像

Parts2Whole能够有效地处理和整合多个不同⼈体的参考图像,⽐如想试试⾃⼰的外观搭配⼈物A的发型,⼈物B的上衣,⼈物C的裤⼦会是什么样⼦的,通过Parts2Whole,可以轻松的实现这⼀⽬标。
任意控制条件数量
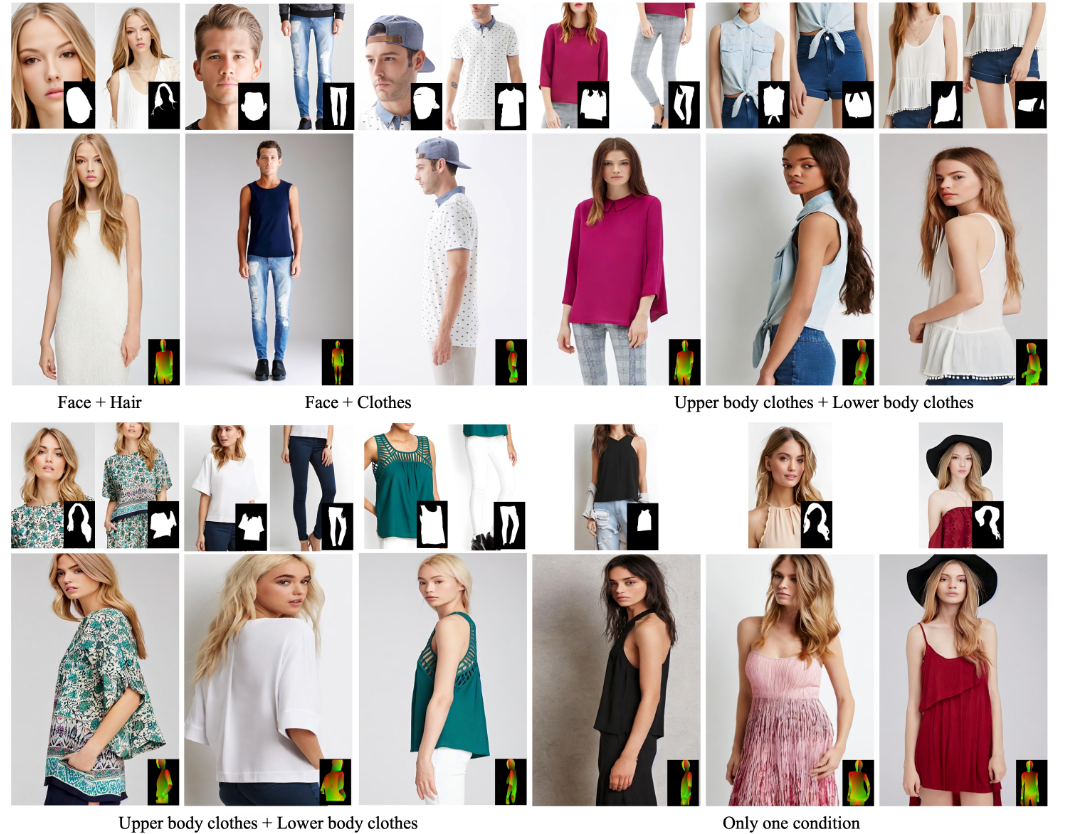
Parts2Whole不仅可以从多个不同⼈体部分来进⾏完整⼈体图像的⽣成,还可以使⽤不同数量的⼈体部分进⾏⽣成,⽐如可以只根据⼀张⼈脸的参考图像进⾏⽣成,也可以使⽤⼀个⼈脸加衣服的参考图像作为控制条件来进⾏⽣成。
更多的技术细节和实验结果请参阅论⽂:https://arxiv.org/pdf/2404.15267。

END
欢迎加入「图像生成」交流群👇备注:生成















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









