






关注公众号,发现CV技术之美

汪玉 宁雪妃 著
电子工业出版社-博文视点 2024-07-01
9787121480591 定价: 119.00 元
新书推荐
🌟今日福利
|关于本书|
本书系统地介绍了高效模型压缩和模型设计的方法,在编写上兼顾理论和实践。本书主体部分详细介绍了模型压缩的方法论,包括高效模块设计、模型剪枝、模型量化、模型二值化、神经网络架构搜索、知识蒸馏几大部分。另外,简要介绍了定制化硬件加速器的设计及大语言模型的加速和压缩。
|关于作者|
汪玉,清华大学电子工程系长聘教授、系主任,IEEE Fellow,国家自然科学基金杰出青年基金获得者,清华大学信息科学技术学院副院长,清华大学天津电子信息研究院院长。长期从事智能芯片、高能效电路与系统的研究,曾获得4次国际学术会议最佳论文奖及12次最佳论文提名。曾获CCF科学技术奖技术发明一等奖、国际设计自动化会议40岁以下创新者奖、CCF青竹奖等荣誉。2016年,知识成果转化入股深鉴科技,打造了世界一流的深度学习计算平台;2018年,深鉴科技被业内龙头企业赛灵思(现AMD)收购。2023年,推动成立无问芯穹,形成面向大模型的软硬件联合优化平台,在国内外10余种芯片上实现了业界领先的大模型推理性能。
宁雪妃,清华大学电子工程系助理研究员。主要研究方向为高效深度学习。支撑深鉴科技、无问芯穹的早期模型压缩和部署工具链工作;参与10余项高效深度学习相关项目;在机器学习、计算机视觉、设计自动化领域发表学术论文40余篇,其中包含在NeurIPS、ICLR、ICML、CVPR、ICCV、ECCV、AAAI、TPAMI上发表的学术论文共20篇;带领团队在NeurIPS18和CVPR20会议上获得国际比赛奖项。
限时折扣,点击购书 ▼
在大语言模型问世之前,尤其是在ChatGPT出现之前,人们几乎没有认真讨论过“人工智能是否具备自我意识”这个话题。
2024年,由AI驱动的GPT-4o等应用产品爆红。
这些热门产品的广阔应用前景令人振奋,吸引了大量资源投入AI的算法研究、数据清洗、算力等方面的基础建设中。
这些爆款应用是由大数据训练的大模型支撑的。
举例来说,近年来,大语言模型的训练数据和模型的体量迅速增长,从2017年发布的有1.65 亿参数量的Transformer,到2020年发布的有1750亿参数量的GPT-3,再到2022年发布的ChatGPT应用背后的模型也至少有数百亿参数量。
这样的训练数据和模型体量的增长带来了模型能力的提升,让大模型“涌现”出指令跟随、上下文学习等能力,展示出“通用”的生成能力。
有目共睹的是,生成式任务的智能算法模型扩大,对算力的需求急剧增加。
在这个背景下,高效深度学习领域显得尤为关键,得到了广泛关注。

如何将“大”模型(参数量大、计算量大)部署到“小”设备上(资源受限,计算和存储能 力低),同时尽量保持算法性能是各应用领域都非常关心的话题。

实际应用场景关心的硬件性能指标主要包括延时(Latency)、吞吐率(Throughput)、功率(Power)、能耗(Energy)和存储(Storage)。
对这些指标的要求反映出用户体验、场景限制、成本控制多方面的需求。例如:
延时和吞吐率影响了可用性和实时性;
热设计功耗(ThermalDesign Power,TDP,即最大负荷的能量释放)决定硬件冷却系统所需具备的散热能力水平;
能耗和存储均直接影响系统成本,等等。
为优化这些指标,研究者和工程师探索了多条路径,纵跨不同设计层次,包括算法设计、软件设计、硬件设计。
在硬件层次,根据算法特性定制化地设计硬件架构,其中可能涉及采用新型器件,代表性工作包括基于FPGA和ASIC的专用硬件架构设计、基于存算器件的专用硬件架构设计。
具体来说,这些工作根据神经网络的算法特性(例如,算子类型、数据的复用模式等)或新器件特性(例如,模拟域计算或存储的能力、器件的非理想特性等)设计专门的计算单元、数据流、指令等,从而用更低的能耗完成同样的计算,即达到更高能效(Energy Efficiency)。
在软件层次,开发者需要针对神经网络模型和硬件平台的特性实现计算算子或系统软件,并开发编译优化工具等,例如,编译优化工具可将神经网络计算流图进行优化、切分、映射,从而将其部署到硬件平台,典型工作包括机器学习编译框架TVM等。
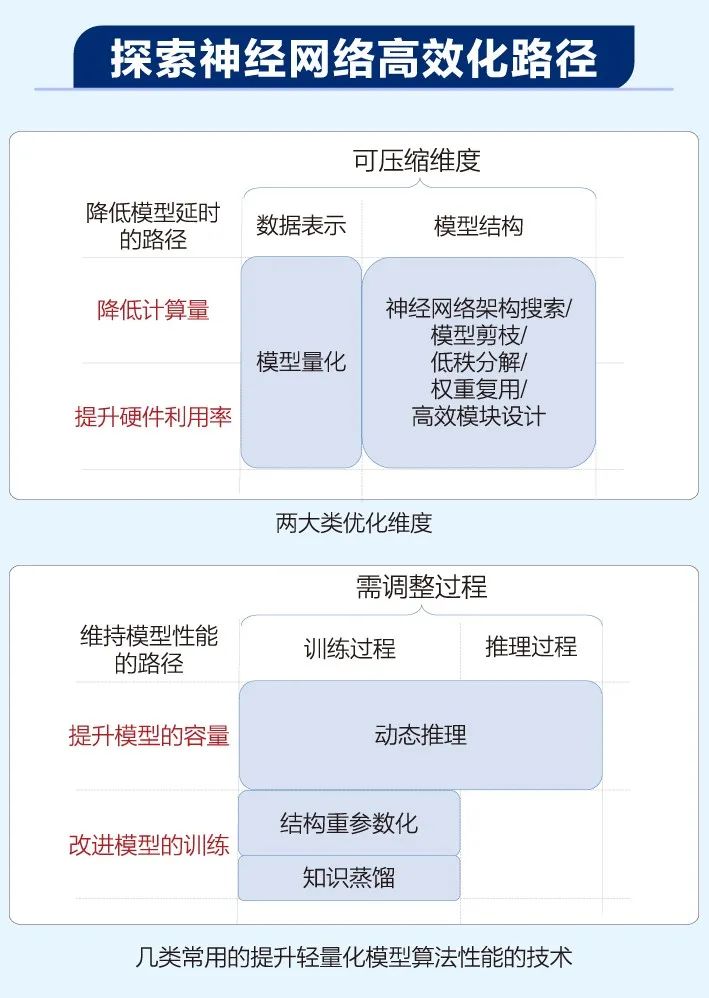
在算法层次,轻量化算法设计针对软硬件系统特性调整算法,通过调整神经网络的模型结构、数据表示等降低其计算开销(Computation Cost)、访存开销(Memory Access Cost)和存储开销(Memory Overhead)。计算开销、访存开销和存储开销的降低最终会体现在延时、吞吐率、功率、能耗、存储容量等指标上。
《高效深度学习:模型压缩与设计(全彩)》一书主体部分围绕“轻量化算法设计”这一思路展开,即通过从头设计或通过压缩已有模型得到更高效的轻量化模型。

书中详细介绍了模型压缩的方法论,包括高效模块设计、模型剪枝、模型量化、模型二值化、神经网络架构搜索、知识蒸馏几大部分。
另外,本书简要介绍了定制化硬件加速器的设计及大语言模型的加速和压缩。
目录
向上滑动阅览
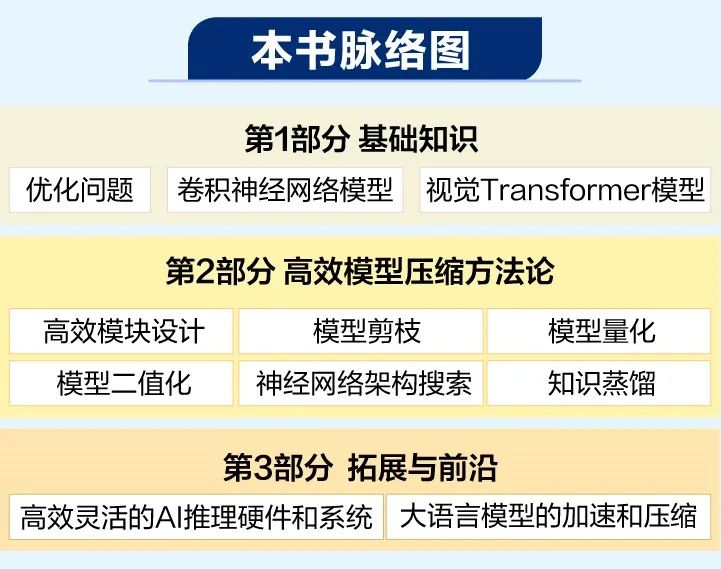
第1部分 基础
1 绪论 2
1.1 神经网络技术的发展 2
1.2 神经网络的高效化需求 3
1.3 神经网络的高效化路径 4
1.4 本书主要内容 6
2 基础知识 7
2.1 优化问题 7
2.1.1 优化问题的定义和分类 7
2.1.2 优化方法的分类 9
2.2 卷积神经网络模型 10
2.2.1 基础模块 10
2.2.2 代表性模型介绍 13
2.3 视觉Transformer模型 15
2.3.1 基础模块 16
2.3.2 模型分类与总结 18
第2部分 高效模型压缩方法论
3 高效模块设计 20
3.1 概述 20
3.2 代表性模型介绍 21
3.2.1 SqueezeNet 21
3.2.2 MobileNet系列 22
3.2.3 ShuffleNet系列 24
3.2.4 GhostNet 26
3.2.5 ConvNeXt 27
3.2.6 VoVNet系列 28
3.2.7 RepVGG 29
3.3 高效模块的5个设计维度 30
3.4 本章小结 31
4 模型剪枝 32
4.1 模型剪枝的定义和分类 32
4.2 模型敏感度分析方法 34
4.2.1 层内和层间敏感度分析 34
4.2.2 层内敏感度分析指标 35
4.3 结构化剪枝方法 37
4.3.1 基于权重正则的结构化剪枝方法 37
4.3.2 基于搜索的结构化剪枝方法 39
4.3.3 给定资源限制的条件下的结构化剪枝方法 44
4.4 近似低秩分解方法 47
4.5 非结构化剪枝方法 48
4.6 半结构化剪枝方法 51
4.7 针对激活值的剪枝方法 53
4.8 剪枝方法的经验性选择 55
4.8.1 剪枝流程的选择 55
4.8.2 剪枝稀疏模式的选择 56
4.8.3 关于任务性能的经验 56
4.9 Group Lasso 结构化剪枝的实践案例 57
4.10 本章小结 60
5 模型量化 61
5.1 模型量化的定义和分类 61
5.2 模型量化过程和量化推理过程 64
5.3 量化格式和操作 65
5.3.1 均匀量化格式 66
5.3.2 非均匀量化格式 68
5.3.3 三种量化操作 71
5.4 量化参数 73
5.4.1 缩放系数 73
5.4.2 零点位置 74
5.4.3 量化位宽 74
5.5 训练后量化75
5.5.1 训练后量化的流程 75
5.5.2 重参数化 76
5.5.3 缩放系数的选取方法 80
5.5.4 量化值调整 83
5.6 量化感知训练 87
5.6.1 基础与流程 87
5.6.2 调整模型架构的方法 90
5.6.3 量化器设计的技巧 92
5.6.4 常用的训练技巧 97
5.7 混合位宽量化 97
5.7.1 基于敏感度指标的混合位宽量化 97
5.7.2 基于搜索的混合位宽量化 99
5.8 量化方法的经验性选择 100
5.8.1 量化流程的选择 100
5.8.2 数据表示的设计和决定 100
5.8.3 算子的选择与处理和计算图的调整 102
5.8.4 关于任务性能的经验 104
5.9 拓展:低比特推理硬件实现 104
5.9.1 定点计算的硬件效率 104
5.9.2 浮点计算转定点计算的原理 105
5.9.3 非均匀量化格式的计算 111
5.9.4 典型的计算单元和加速器架构 112
5.10 拓展:低比特训练简介 115
5.10.1 应用背景 115
5.10.2 挑战分析 116
5.10.3 相关工作 116
5.11 本章小结 117
6 模型二值化 118
6.1 模型二值化的定义和分类 118
6.2 模型二值化的基础:以XNOR-Net为例 120
6.3 二值化方式 122
6.3.1 朴素二值化方式 123
6.3.2 间接二值化方式 127
6.4 训练技巧 131
6.4.1 修改损失函数 132
6.4.2 降低梯度估计误差 133
6.4.3 多阶段的训练方法 135
6.4.4 训练经验 136
6.5 架构设计 137
6.5.1 模型架构的调整 138
6.5.2 模型架构搜索 141
6.5.3 集成方法与动态模型 142
6.6 模型二值化在其他任务与架构中的应用 142
6.7 本章小结 144
7 神经网络架构搜索146
7.1 神经网络架构搜索的定义和分类 146
7.2 搜索空间 149
7.2.1 人工设计搜索空间 150
7.2.2 自动设计搜索空间 154
7.2.3 总结 156
7.3 搜索策略 157
7.3.1 基于强化学习的搜索策略 157
7.3.2 基于进化算法的搜索策略 159
7.3.3 随机搜索策略 160
7.3.4 基于架构性能预测器的搜索策略 160
7.3.5 总结 164
7.4 评估策略 165
7.4.1 独立训练策略 166
7.4.2 基于权重共享的单次评估策略 167
7.4.3 基于权重生成的单次评估策略 172
7.4.4 零次评估策略 172
7.5 可微分神经网络架构搜索 175
7.5.1 连续松弛方法 175
7.5.2 优化方法 176
7.5.3 搜索坍缩问题 177
7.5.4 更高效的可微分搜索算法 179
7.6 考虑硬件效率的神经网络架构搜索 180
7.6.1 考虑硬件效率的搜索空间设计 181
7.6.2 硬件效率指标的加速评估方法 182
7.6.3 考虑多种硬件效率目标的搜索策略 184
7.6.4 面向多种硬件设备及约束的神经网络架构搜索方法 186
7.7 本章小结 188
8 知识蒸馏 190
8.1 知识蒸馏的定义和分类 190
8.2 知识类型和知识分量:“学什么” 192
8.2.1 基于响应的知识 192
8.2.2 基于特征的知识 194
8.2.3 基于关系的知识 197
8.3 知识来源:“向谁学” 199
8.3.1 离线蒸馏 199
8.3.2 互学习 199
8.3.3 自蒸馏 200
8.4 本章小结 201
第3部分 拓展和前沿
9 相关领域:高效灵活的AI推理硬件和系统 203
9.1 概述 203
9.2 硬件加速器设计和软硬件协同优化 204
9.2.1 从CPU到硬件加速器 204
9.2.2 AI加速器中的软硬件协同优化 206
9.2.3 Roofline分析模型 207
9.2.4 基于指令集的AI加速器 210
9.3 神经网络计算资源虚拟化 211
9.3.1 虚拟化的概念 211
9.3.2 AI加速器的时分复用与空分复用虚拟化 212
9.3.3 相关工作简介 214
9.4 本章小结 215
10 前沿应用:大语言模型的加速和压缩 218
10.1 大语言模型的发展 218
10.2 大语言模型的架构和推理过程 219
10.3 大语言模型的高效性分析 220
10.3.1 效率瓶颈 220
10.3.2 优化路径 221
10.4 典型的大语言模型的压缩方法:量化 223
10.5 本章小结 226
后记 227
参考文献 229
适读人群
对于希望进入模型压缩领域的初学者,本书归纳了高效深度学习领域的整体框架,并注重阐述和辨析重要的基本概念,希望可以帮助读者快速获得对该领域的整体认知和掌握重要概念。
对于有一定科研经验、希望在相关科研方向进行探索的读者,本书在多个层次提供了框架性总结,定位多个子领域之间、同一子领域内多个方法之间的关系,希望可以帮助读者加强对知识的整合,利用框架更好地进行创新探索。
对于需要工具书辅助解决实际问题的读者,本书不仅包含对实践经验的总结,也包含对每个细分技术及其应用的逻辑的详细说明,希望可以帮助读者厘清分析和解决问题的思路,并快速定位到相关文献。
名家点评
本书系统地解析了压缩、设计与量化神经网络模型的技术,严谨地梳理了重要概念、逻辑与框架,理论结合实践,深入浅出。
对初学者而言,本书是快速掌握该领域的理想教材;对研究者与从业者而言,本书是深化理解、拓宽视野、启发创新的宝贵资源。无论求知或深耕,皆可借本书汲取知识、收获启迪,共探人工智能前沿。
ACM Fellow,IEEE Fellow,AAAS Fellow
香港科技大学讲席教授
阿里巴巴达摩院荣誉顾问
谢源
本书全面梳理了高效模型压缩和模型设计的方法论,结构逻辑清晰,内容紧跟前沿。书中提供的系统性的方法论总结和前沿性的知识介绍能为该领域的科研工作者提供许多启示。
AAAS Fellow,ACM Fellow,IEEE Fellow,NAI Fellow
杜克大学电气与计算机工程系教授
陈怡然
本书全面地总结了模型压缩方法论,同时分享了不少实践经验,这对模型压缩方法在工业界的实际应用提供了重要参考,是值得学习的优秀教材。
华为算法应用部部长
王云鹤


限时优惠,感兴趣的读者可以点击购买
互动赠书

在本文下方留言区推荐一篇近期所读论文以及简述推荐理由,如:
论文:Prediction Exposes Your Face: Black-box Model Inversion via Prediction Alignment
地址:https://arxiv.org/abs/2407.08127
将由CV君选取3位小伙伴(走心且要对别人有价值),赠送《高效深度学习》一书。
活动截止时间:2024.7.17 9:00

END
欢迎加入「模型压缩」交流群👇备注:部署



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









