







CAAI 副理事长刘成林研究员现场发布
本文转自中国人工智能学会。
2023年6月,中国人工智能学会(CAAI)成立专家组,开展了推荐学术会议/期刊目录的工作。专家组对智能科学与技术基础理论、智能科学与技术交叉、脑认知与类脑智能、机器学习、机器感知与模式识别、自然语言处理、知识工程与数据挖掘、跨媒体智能与人机交互、智能机器人与系统、智能芯片与计算系统以及人工智能伦理、安全与治理等领域的期刊和会议进行了分级。2024年1月,中国人工智能学会(CAAI)发布《中国人工智能学会推荐国际学术会议和国际/国内期刊目录》初稿,面向人工智能领域专家和学者征求意见,正式启动了学科领域学术会议、期刊分类完善工作。
在各位专家的积极参与、辛勤付出和大力支持下,目前形成了《中国人工智能学会推荐国际学术会议、国际/国内期刊目录》(以下简称“目录”),现予以公布。所推荐国际学术会议和国际/国内期刊目录信息可扫描文末二维码全文下载。
《目录》分为A类、B类、C类三档。A类通常被认为是该领域内最顶尖的学术会议或刊物,具有极高的学术标准和影响力;B类代表在国际上广泛认可的重要学术会议或刊物,在特定领域或子领域内具有较高的声誉;C类代表国际学术界所认可的重要学术会议或刊物,是学术交流的重要平台。
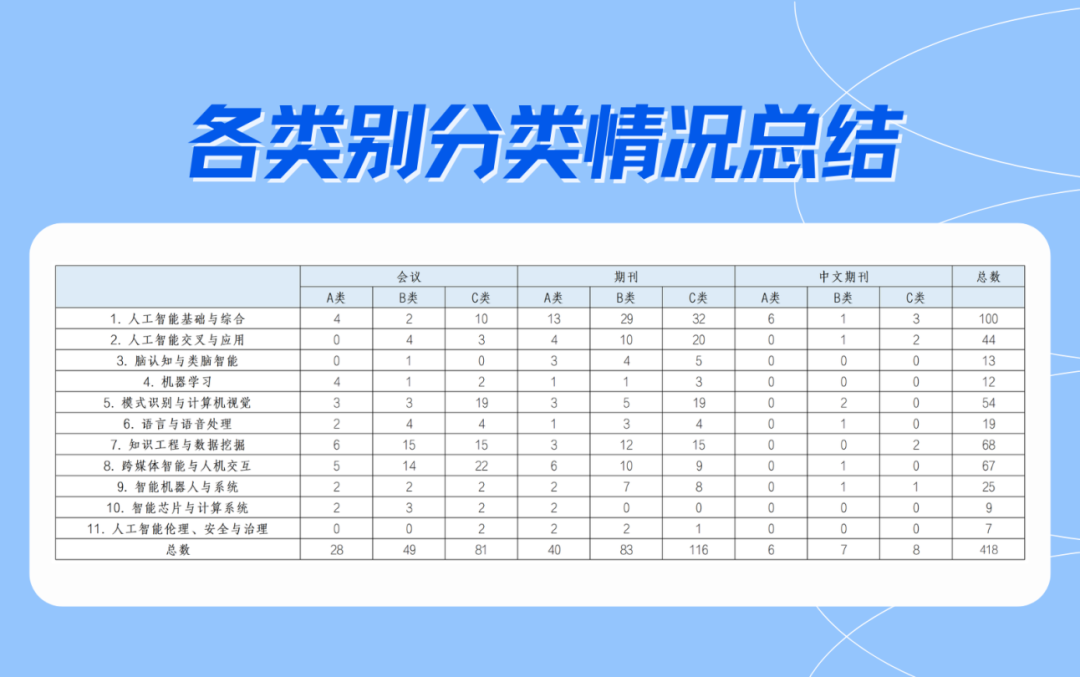
《目录》按照人工智能领域学科下11个细分领域,推荐了共计418个重要学术会议及刊物(部分符合分类标准的刊物因处于科睿唯安On Hold标识状态的原因本次暂未列入推荐目录),具体包括158个国际学术会议、239个国际期刊和21个国内期刊。11个细分领域分别为:(1)人工智能基础与综合;(2)人工智能交叉与应用;(3)脑认知与类脑智能;(4)机器学习;(5)模式识别与计算机视觉;(6)语言与语音处理;(7)知识工程与数据挖掘;(8)跨媒体智能与人机交互;(9)智能机器人与系统;(10)智能芯片与计算系统;(11)人工智能伦理、安全与治理。
特别说明:本《目录》是中国人工智能学会为人工智能领域的科研工作者提供的一个学术交流和发表科研成果的推荐资源列表,并非旨在成为学术评价的单一标准,而是作为学会一个建议性的参考,仅供业界人士参考使用。中国人工智能学会将定期对目录列表进行更新,以确保其准确性、公正性和全面性。我们诚挚地邀请学术界的专家和学者对《目录》提出宝贵的反馈和建议,以助于其不断的改进和完善。


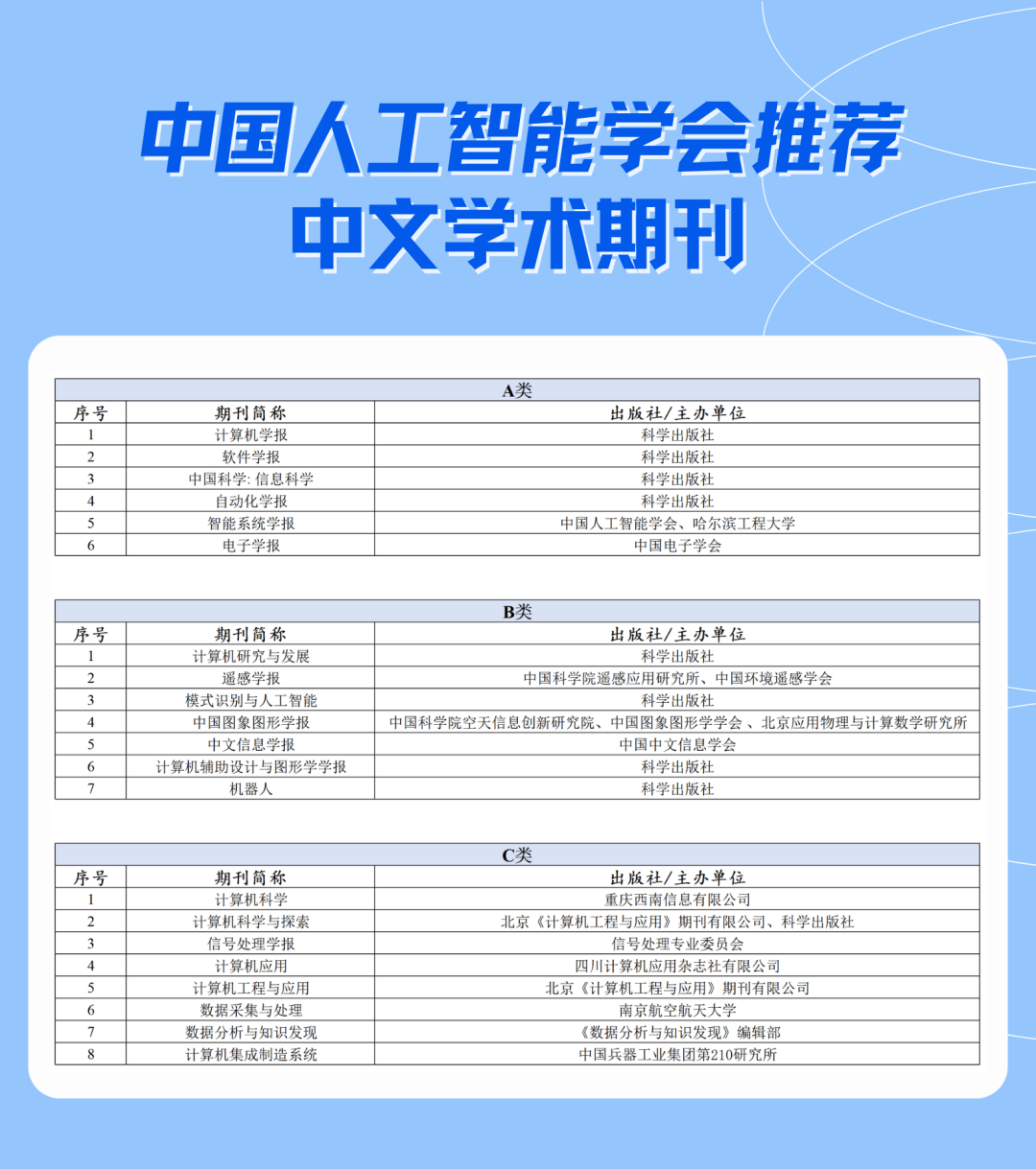
附件:《中国人工智能学会推荐国际学术会议、国际/国内期刊目录》(完整版)
扫码下载 ↓


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









