






自ChatGPT模型问世后,在全球范围内掀起了AI新浪潮。
有很多企业和高校也随之开源了一些效果优异的大模型,例如:Qwen系列模型、MiniCPM序列模型、Yi系列模型、ChatGLM系列模型、Llama系列模型、Baichuan系列模型、Deepseek系列模型、Moss模型等。
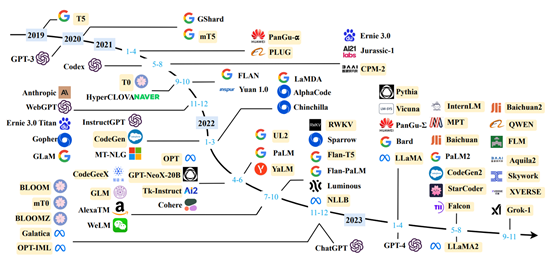
图片来自:A Survey of Large Language Models
并且在去年的一整年中,大多数人都在做底座通用大模型的搭建、垂直领域大模型预训练或微调等工作。虽然大模型基础能力得到了很大程度的提升,但是大模型距离真正地落地,其实还有一段艰难的路要走。
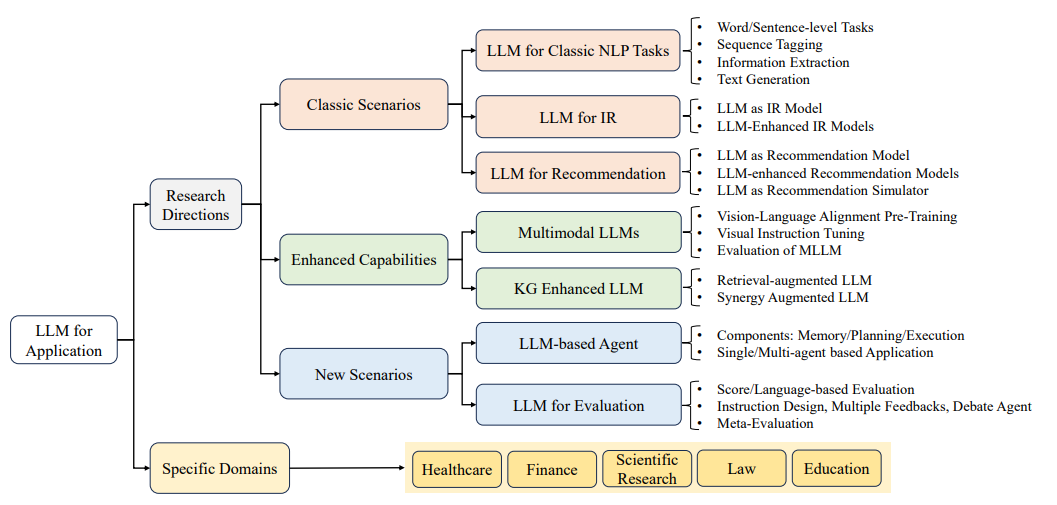
图片来自:A Survey of Large Language Models
那么如何让大模型更好地进行场景落地,变得尤为重要。例如:如何优化通用大模型在领域上的效果,如何在某些场景中合理运用大模型,如何确保生成内容的稳定性和安全性,如何确保大模型可以在生产环境下稳定使用等。

《大型语言模型实战指南》一书从大模型应用落地角度出发,系统梳理了大模型的相关技术,也帮助读者学习如何优化开源大模型在不同领域或场景中的效果,详细讲述了如何搭建角色扮演、信息抽取、知识问答、AI Agent等各种各样的大模型应用。
角色扮演
角色扮演应用主要利用大模型来模拟不同属性和风格的人物和角色,如游戏人物、动漫角色、网络小说的主角、电影人物、电视人物,以及历史名人等,旨在为用户带来更精细、更沉浸的交互体验。
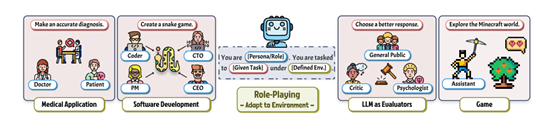
图片来自:From Persona to Personalization: A Survey on Role-Playing Language Agents
为了确保用户获得最佳的体验,角色扮演应用不仅需模拟角色基本的对话流程,还要求大型语言模型深入理解角色的性格、故事背景、情感状态和行为模式,从而塑造出更为智能和生动的AI角色。可以应用在教育、游戏、咨询、创作、培训等多个领域中。

图片来自:Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization
Text2SQL
Text2SQL应用就是将自然语言查询转换为结构化查询语言(SQL)语句,以便从数据库中检索数据。随着大模型能力的逐步提高,解决Text2SQL的任务的方法也从传统深度学习模型转向大模型。并且各种平台系统的ChatBI、数据分析等功能,均离不开Text2SQL技术。
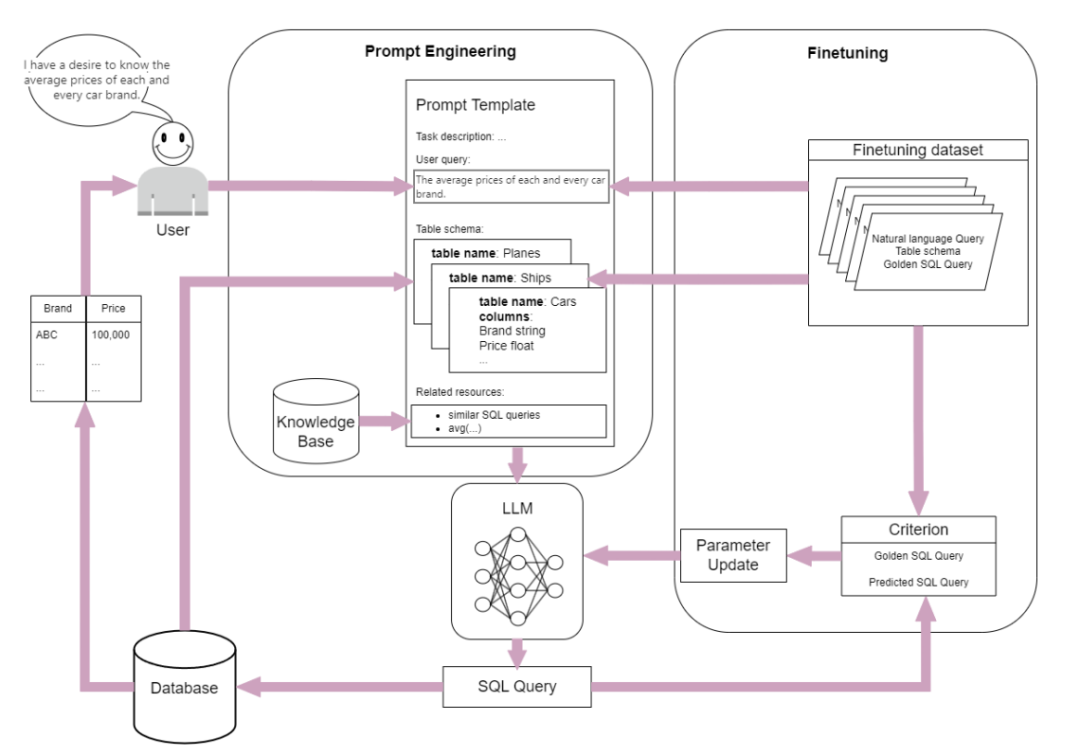
图片来自:A Survey on Employing Large Language Models for Text-to-SQL Tasks
RAG
RAG(Retrieval-Augmented Generation,检索增强生成)技术,主要是在大型语言模型生成答案之前,通过检索方法从数据库中检索与用户查询相关的信息,利用这些相关信息指引大型语言模型进行答案生成。
RAG不仅极大程度地解决大型语言模型幻觉的问题,还提高模型回复的可靠性,提供生成答案的溯源信息,并且通过更新外部知识库实现对于知识的更新,无需重新训练模型,减少了模型训练更新的成本。目前,已经成为大型语言模型应用落地的重要方向。
RAG的整体流程主要涉及查询处理模块、内容检索模块、内容组装模块和大模型生成4个部分。当系统接收到用户查询Query进行初步处理后,利用向量检索模型从构建的向量知识库中检索到与其最相关的文档片段内容,再通过提示工程对用户查询Query和文档片段进行组装,最后利用大模型生成一个答案。
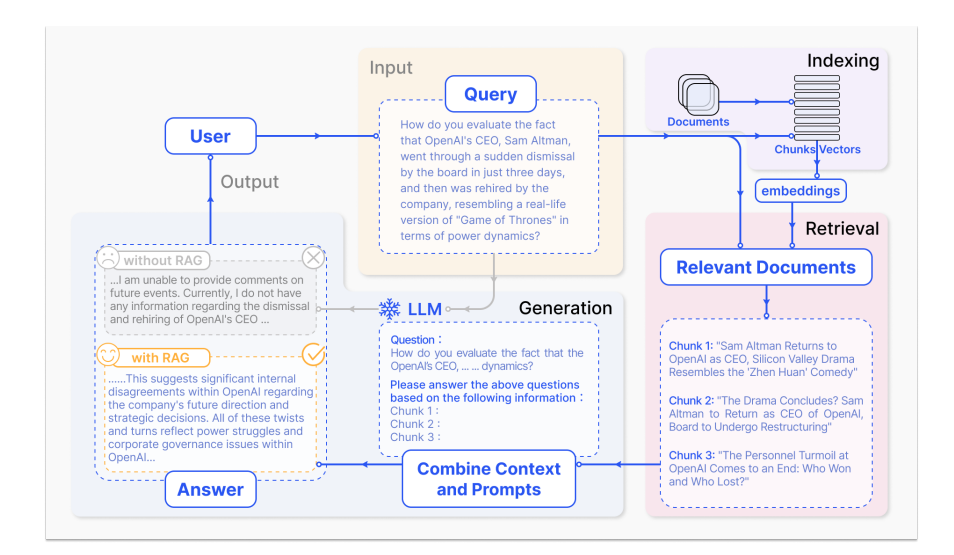
图片来自:Retrieval-Augmented Generation for Large Language Models: A Survey
AI Agent
Agent是能够感知自身所处环境、自我决策并采取行动的人工智能实体。Agent技术的应用范围广泛且多样化,它们不仅仅是简单的自动化工具,而是能够在多个领域中提供高效和创新的解决方案。
自动化和效率化的工具:从简单的数据查询到复杂的决策制定,它们都能显著减少人工操作的需求,优化工作流程。
数据分析和处理:在处理大量数据和执行复杂分析方面,能够从海量数据中提取有价值的信息,为企业和研究者提供快速、准确的洞察。
交互式用户体验:通过自然语言处理和上下文感知技术,提供个性化和互动的用户体验,从而改善用户交互。
智能决策支持:作为决策支持工具,在分析复杂情况和提供基于数据的建议方面表现突出,特别是在商业、医疗和科研等领域。
集成与扩展服务:通过API调用外部服务,为用户提供全面和扩展的功能。可以通过API调用外部服务,将不同的功能和信息源集成到一个统一的接口中。
自适应学习和进化:能够根据用户反馈和行为模式不断进化,以更好地满足用户需求。
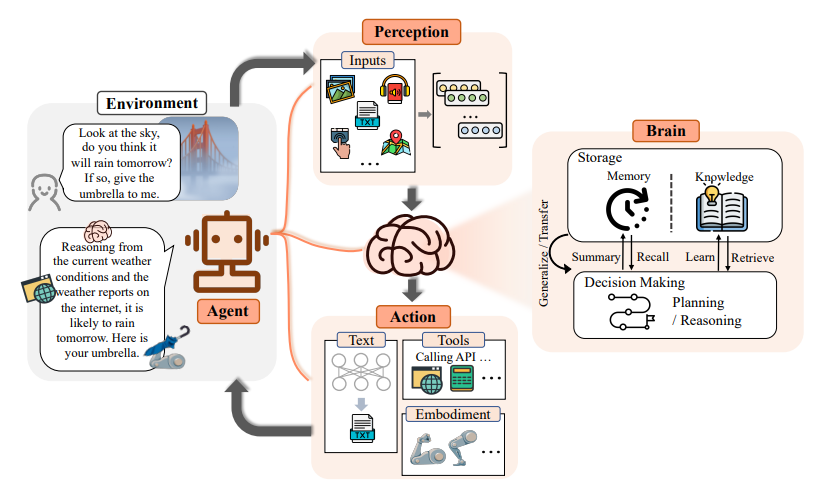
The Rise and Potential of Large Language Model Based Agents: A Survey
文章来源:IT阅读排行榜
本文摘编自《大型语言模型实战指南:应用实践与场景落地》,机械工业出版社出版,经出版方授权发布,转载请标明文章来源。
▼
延伸阅读

《大型语言模型实战指南:应用实践与场景落地》
刘聪 沈盛宇 李特丽 杜振东 著
资深大模型技术专家撰写
零一万物、通义千问、面壁智能等
多个主流大模型的负责人力荐
内容简介:
这是一本系统梳理并深入解析大模型的基础理论、算法实现、数据构造流程、模型微调方法、偏好对齐方法的著作,也是一本能手把手教你构建角色扮演、信息抽取、知识问答、AI Agent等各种强大的应用程序的著作。本书得到了零一万物、面壁智能、通义千问、百姓AI、澜舟科技等国内主流大模型团队的负责人的高度评价和鼎力推荐。

本文来源:原创,图片来源:原创
责任编辑:王莹,部门领导:宁姗
发布人:白钰

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









