






关注公众号,发现CV技术之美
本篇分享 NeurIPS 2024 论文MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model,北大联合阿里提出 MaVEn:面向多模态大模型多图理解的连续/离散视觉混合编码策略。

论文地址:https://arxiv.org/pdf/2408.12321
代码地址:https://github.com/orgs/X-PLUG/repositories
研究动机与背景
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在处理复杂的视觉-语言任务上表现出巨大潜力。通过结合自然语言处理和计算机视觉技术,这些模型在单图像描述生成、视觉问答等任务中取得了突破。然而,随着实际应用需求的不断增长,当前的MLLMs在多图像推理任务上仍然面临重大挑战。这些挑战主要表现在以下几个方面:
视觉信息冗余与序列长度问题
多图像任务(如多视角事件推理、多图像关系分析)通常涉及多张图像输入。这会导致视觉特征序列过长,不仅增加了模型的计算开销,还可能引入大量冗余信息,削弱模型对关键语义的捕获能力。例如,传统视觉编码方式常将图像的每一局部特征以连续序列的形式输入到模型中,当输入图像数量增加时,序列长度呈指数级增长,极大地限制了推理效率。语义抽象能力不足
当前的MLLMs在处理视觉信息时,大多依赖连续特征(如卷积神经网络或视觉Transformer生成的特征向量)。虽然这种方式能够捕获图像的细节信息,但在语义层次上的抽象能力较弱,尤其是在多图像场景中,难以精准地建模图像间的高层语义关联。此外,这种特征表示容易受到无关细节的干扰,限制了模型在语义推理任务中的表现。多模态对齐与跨图像推理的困难
多图像任务要求模型不仅能够提取单张图像的语义,还需要综合多张图像的语义信息,进行逻辑推理和关系建模。这种跨图像的语义关联需要更强大的多粒度信息融合能力,而现有模型在这方面存在明显不足。例如,多图像任务中的图像间关系可能涉及时间序列、空间分布或抽象事件的因果关联,单一粒度的视觉表征很难全面捕捉这些复杂关系。
基于上述挑战,作者提出了一种名为 MaVEn(Multi-granularity Hybrid Visual Encoding Framework 的混合视觉编码框架。该框架旨在通过整合离散和连续的视觉表征方式,以多粒度的语义建模来提升MLLMs在多图像任务中的推理能力,并通过动态序列压缩机制解决计算效率问题。
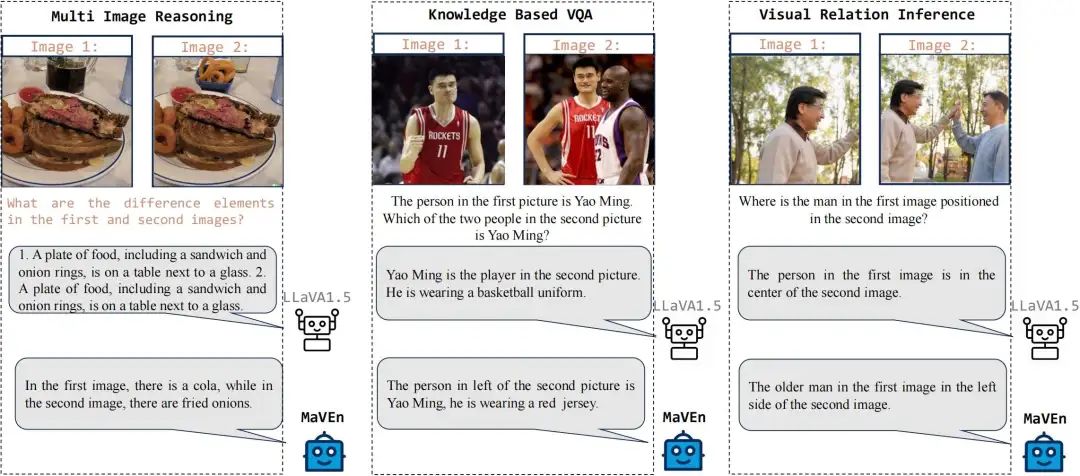
图1. 我们对比了经典的单图像任务训练的多模态大语言模型 LLaVA1.5和Mavenn在三种多图像场景(多图像推理、基于知识的视觉问答和视觉关系推断)中的性能表现。LLaVA1.5 在多图像场景下表现出显著的局限性
方法(Method)
本文提出了一种基于多粒度视觉特征的多模态大语言模型(MLLM)架构,如图2所示,该架构能够有效增强多图像理解能力。图像输入被编码为离散符号序列和连续高维向量序列两种形式。
离散视觉符号序列提取了图像中粗粒度的核心视觉概念,而连续向量序列则保留了图像的细粒度信息。此外,为了减少多图像场景中连续视觉序列的冗余信息和无关表示,并缩短输入上下文长度,框架还引入了一种基于文本语义引导的动态视觉特征缩减策略。以下为该方法的具体模块和机制。
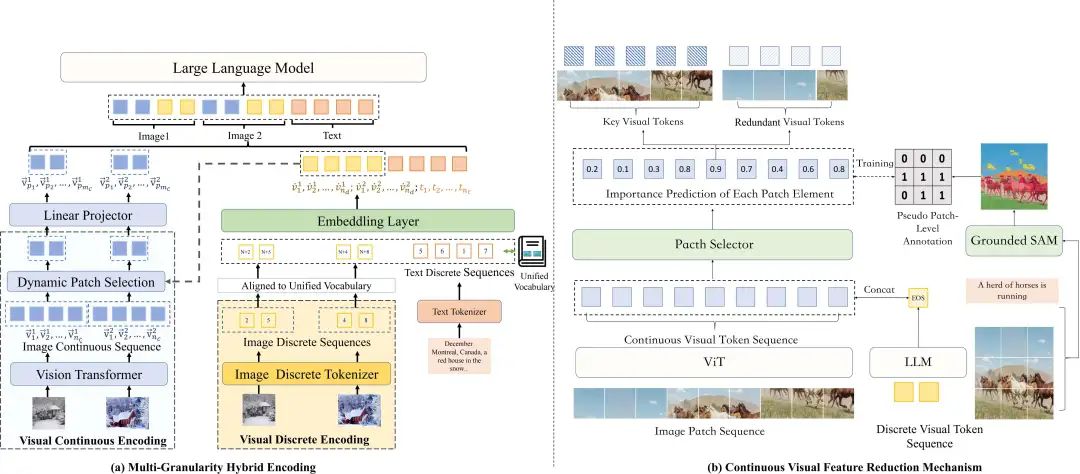
图2. 子图(a)展示了多粒度混合视觉编码框架的结构示意图;子图(b)展示了在离散视觉信息指导下的连续视觉特征缩减机制
1.多粒度混合编码(Multi-Granularity Hybrid Encoding)
如图2 所示,假设输入为 ,其中 表示 张图像的集合, 为对应的文本内容。对于每张图像 (),分别采用离散视觉编码器()和连续视觉编码器()进行编码。
1.1 离散视觉编码(Visual Discrete Encoding)
离散化过程:
图像 通过离散视觉标记器 ,例如 ()被离散化为一组视觉符号序列:其中,, 是视觉离散编码词汇表的大小。
统一多模态词汇:
将视觉离散词汇与文本词汇合并形成统一的多模态词汇。假设语言模型的词汇表大小为 ,视觉词汇表大小为 ,则多模态词汇表大小为 。
视觉离散序列 被重新对齐到多模态词汇表的索引中,最终离散编码形式为:其中,。
同时,语言模型嵌入层的权重矩阵 从 扩展到 ,从而能够同时嵌入视觉和文本离散符号。
最终视觉表示:
将连续视觉特征与离散视觉特征进行序列拼接,形成输入到 LLM 的最终视觉表示:
1.2连续视觉编码(Visual Continuous Encoding)
编码过程:
使用视觉变换器(Vision Transformer, ViT)对输入图像 进行编码。假设图像尺寸为 ,首先将其划分为大小为 的图像块(patch),生成 个图像块。
这些图像块通过 ViT 编码器被编码为连续视觉特征序列:其中,, 是维度为 的连续向量。
特征缩减:
使用基于文本语义的补丁(patch)缩减模块,对 中与输入文本内容 无关的特征进行动态裁剪。
得到缩减后的特征序列:
最后,使用类似于 LLaVA 1.5 的多层感知机(MLP)投影器将 投影到与语言模型(LLM)嵌入层一致的语义空间中。
2.连续视觉特征缩减机制(Continuous Visual Tokens Reduction Mechanism)
动机:
连续视觉特征序列 中存在较多冗余或重复语义信息。为了避免这些信息影响模型的推理效率,本文提出了一种在离散视觉信息指导下的连续特征缩减机制,以实现语义协同。离散视觉信息的全局表示:
在获得离散视觉符号序列 后,添加一个 <EOS> 符号。
将 输入 LLM,获取最后一层的 <EOS> 输出隐状态 ,作为离散视觉信息的全局表示。
相关性评分与缩减:
将每个图像块特征与 进行拼接,构造输入 。
通过多层感知机(MLP)预测每个图像块与离散视觉信息的相关性评分 :
根据相关性评分 ,选择前 个关键图像块特征,未被选中的特征将被丢弃。这里 是控制选择比例的超参数。
伪标签构造:
使用 Grounding SAM 对图像进行文本引导的语义分割,生成像素级掩码。
计算每个图像块与掩码的重叠面积,重叠的图像块被标注为 1,否则标注为 0,以此构造块级伪标签。
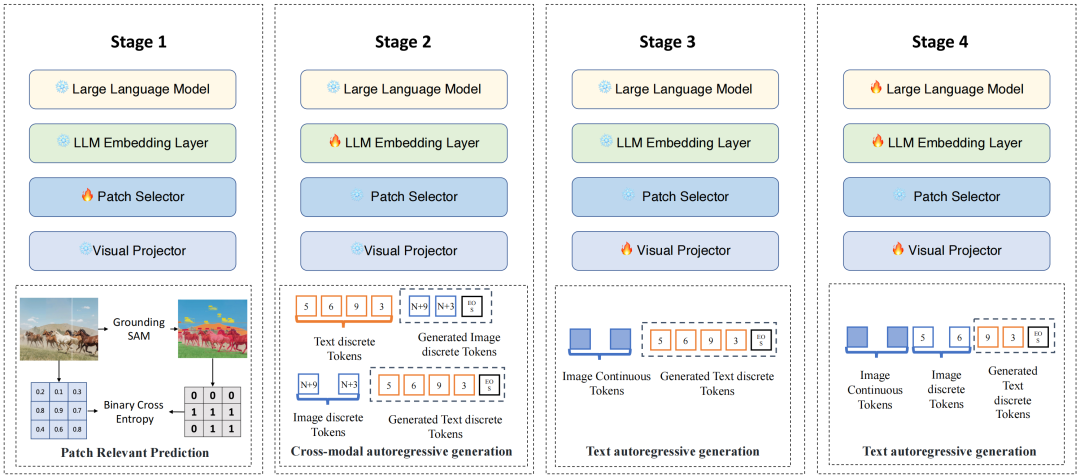
3.模型训练范式(Training Paradigm)
模型的训练分为以下四个阶段:
第一阶段:训练补丁选择器(Patch Selector)。
利用 COCO 和 Visual Genome 数据集生成的语义分割伪标签,冻结其他参数,仅训练补丁选择器。
第二阶段:扩展 LLM 嵌入层以适应多模态词汇表。
使用单图像数据集(如 LLaVA 558K)训练模型的离散视觉编码部分。
第三阶段:优化视觉投影器(Visual Projector)。
使用连续视觉特征生成图像描述,调整视觉投影器与多模态词汇表语义空间的对齐。
第四阶段:全模型微调。
使用 LLaVA 665K 指令微调数据集,解冻除视觉编码器和补丁选择器外的所有参数。
如图3所示,各阶段有机结合,逐步优化模型的多模态语义表示能力。
实验结果
为验证 Maven 在多图像场景中的有效性,我们评估了其在多图像视觉理解和推理方面的表现。在多图像视觉理解任务中,采用了 DemonBench 和 SEED-Bench 作为评估基准。
DemonBench 涵盖七种多图像推理和理解场景,包括多模态对话(Multi-Modal Dialogue)、视觉关系推理(Visual Relation Inference)、知识支撑问答(Knowledge-Grounded QA)以及多图像推理(Multi-Image Reasoning)等任务。而 SEED-Bench 则涉及视频理解相关问题。此外,还对 Maven 在单图像场景中的性能进行了测试。
1. Maven 在多图像视觉理解任务中的表现
1.1 DemonBench 测试结果
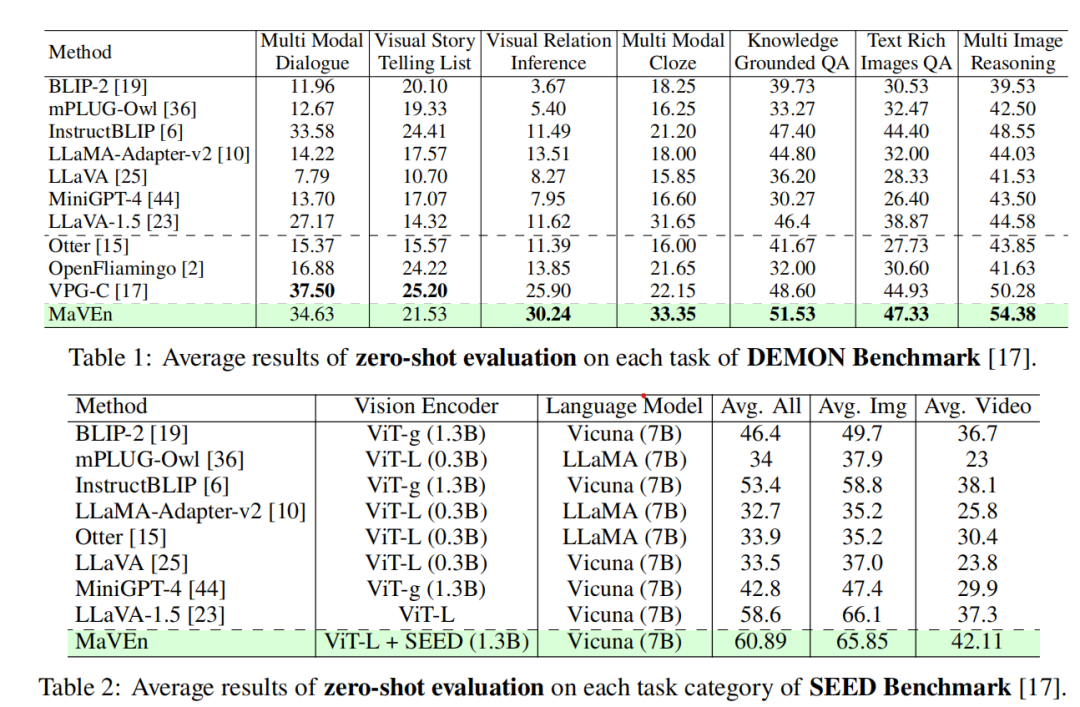
如表 1 所示,我们在 DemonBench 上对 Maven 进行了评估,并与多图像数据训练的多模态大语言模型(如 Openflamingo、Otter、VPG-C)以及单图像场景模型进行了比较。
实验结果显示,Maven 在多个任务中表现优异,例如视觉关系推理(Visual Relation Inference)、多模态填空(Multi-Modal Cloze)、富文本图像问答(Text-Rich Images QA)、知识支撑问答(Knowledge-Grounded QA)和多图像推理(Multi-Image Reasoning)。
此外,在视觉故事生成(Visual Storytelling)和多模态对话(Multi-Modal Dialogue)任务中,Maven 的表现与现有最优方法相当。
1.2 SEED-Bench 测试结果
在 SEED-Bench 上,特别是在视频理解任务(如动作预测、动作识别和过程理解)中,Maven 的表现同样出色。如表2 所示,Maven 在视频理解任务上的性能显著优于现有模型,例如 Otter 和 LLaVA 1.5。例如,在视频理解任务中,相较于 Otter(30.4 分),Maven 提高了 12 个百分点,达到 42.11 分。这些结果表明,Maven 在多图像理解场景中具有显著优势。
2. Maven 在单图像视觉理解任务中的表现
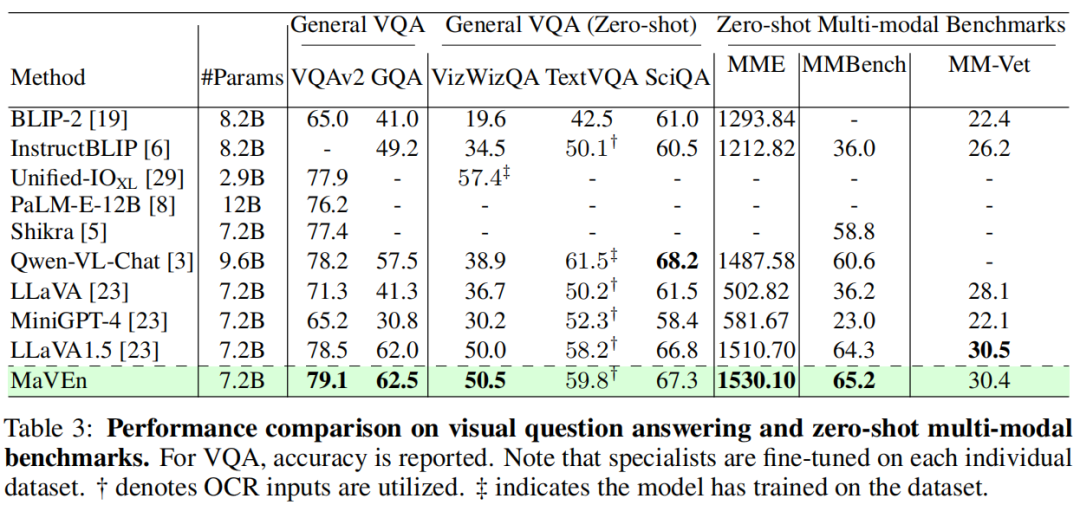
我们还探讨了 Maven 对单图像视觉理解和生成能力的提升效果。在此背景下,我们选用了常见基准(如视觉问答 VQA 数据集 )以及最近设计的多模态基准(如 MME、MMBench 和 MM-Vet)进行评估。
如表3 所示,我们将 Maven 的性能与其他最先进的多模态大模型(如 BLIP2、InstructBLIP、Shikra 和 Qwen-VL-Chat)进行了比较。实验结果表明,Maven 在单图像理解任务中的性能也显著提升。
3. 消融实验
3.1 多粒度混合编码的有效性
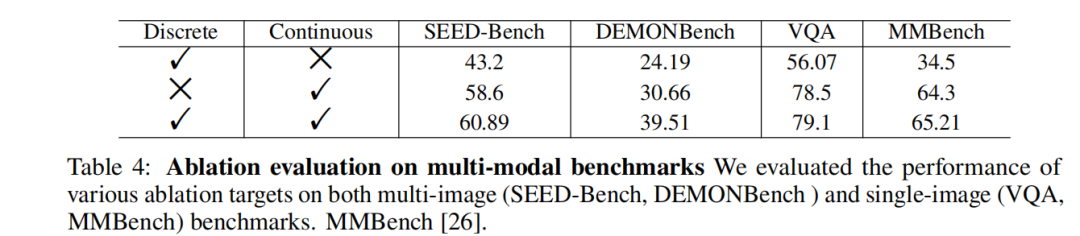
为验证多粒度混合编码的有效性,我们分别采用仅使用视觉离散编码和仅使用视觉连续编码的模型进行训练,并将其结果与多粒度混合编码模型的性能进行了对比。结果如表 4 所示:
仅使用视觉离散编码的模型在多图像和单图像场景中的表现较差。这是因为离散视觉特征编码在捕获图像高维语义信息的同时,丢失了大量低维细粒度细节信息,从而导致编码过程存在损耗。
仅使用视觉连续编码的模型也未能实现最优性能,尤其是在多图像任务中。这表明单一的视觉连续编码方法不适合复杂的多图像场景。
采用多粒度混合编码的模型在所有基准上的表现均显著优于上述单一编码方法,验证了其在保留语义细节和高效推理方面的优势。
3.2 连续视觉特征缩减机制的效率
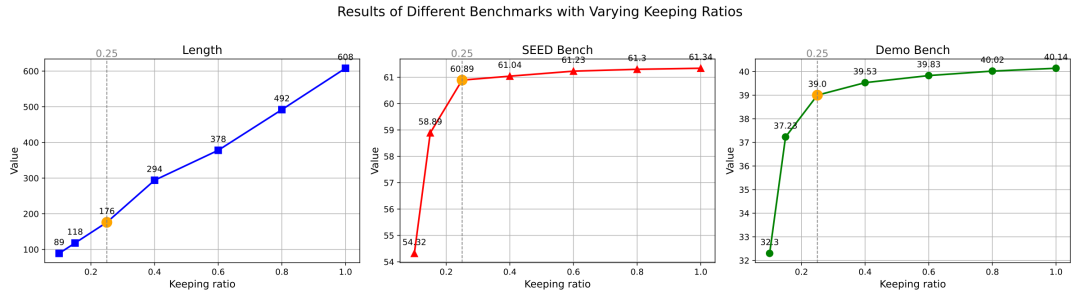
为验证补丁缩减机制的有效性,我们在不同保持比例(Keeping Ratio)下,比较了视觉标记长度的变化以及模型在多种基准任务上的表现。
实验结果如图4 所示:
当保持比例为 0.1 时,视觉标记数量大幅减少至 89,但模型性能显著下降。
当保持比例为 0.25 时,视觉标记数量适中且性能较为稳定,模型在多种基准任务中的表现均达到较高水平。因此,我们最终选择保持比例为 0.25。
4. 定性分析
4.1 离散与连续视觉标记的语义粒度
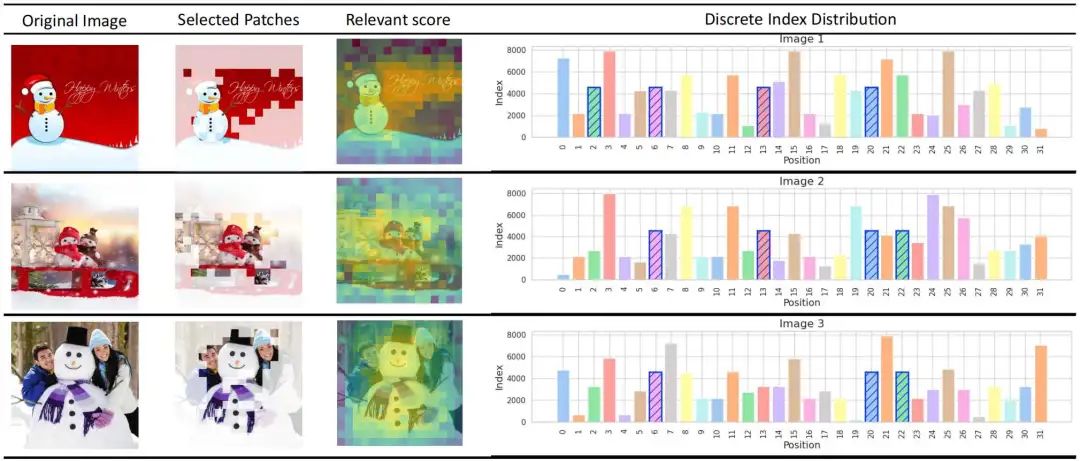
为研究离散标记的语义,我们从视觉离散字典中随机选择一个索引值(例如索引值 4568),并在 CC/SUB 数据集中搜索含有该索引的图像。如图 5 所示,我们发现包含索引 4568 的图像均描绘了雪人。这表明索引 4568 可表示高层语义(如雪人或白雪)。
4.2 离散与连续视觉表示的语义协同
如图5所示,通过补丁选择器的相关性评分以及保持比例为 0.25 时选中的图像块,我们观察到补丁选择器倾向于选择与离散视觉语义相关的图像块。这些补丁补充了离散标记中缺失的低级细节信息,进一步验证了多粒度混合编码在实现语义协同方面的有效性。
4.3 离散视觉标记在多图像推理中的作用

如图6 所示,在仅使用连续视觉标记时,模型推理过程中主要关注文本标记,忽视了视觉标记。而采用多粒度混合编码后,模型在回答问题时建立了与离散视觉标记的注意力关联。这表明离散视觉标记在多图像推理过程中引导语言模型关注视觉信息。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「大语言模型」交流群👇备注:LLM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









