






关注公众号,发现CV技术之美
本篇分享论文AnyDressing:Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models,字节提出AnyDressing:文字指令一键换装、换姿势、换背景、换风格,开启个性化时尚新纪元!

论文链接:https://arxiv.org/abs/2412.04146
项目链接:https://crayon-shinchan.github.io/AnyDressing/
Abstract
基于扩散模型的以服装为中心的文本和图像提示图像生成的最新进展令人印象深刻。然而,现有的方法缺乏对各种服装组合的支持,并且难以在保持对文本提示的忠实度的同时保留服装细节,从而限制了它们在不同场景中的表现。
在本文中,我们专注于一项新任务,即多服装虚拟穿衣,并提出了一种新颖的 AnyDressing 方法,用于根据任何服装组合和任何个性化文本提示定制角色。AnyDressing 包含两个主要网络,分别名为 GarmentsNet 和 DressingNet,分别用于提取详细的服装特征和生成定制图像。
具体来说,我们在 GarmentsNet 中提出了一个高效且可扩展的模块,称为服装特定特征提取器,用于并行单独编码服装纹理。这种设计在确保网络效率的同时防止了服装混淆。
同时,我们在 DressingNet 中设计了一种自适应的 Dressing-Attention 机制和一种新颖的实例级服装定位学习策略,以将多服装特征准确地注入其相应区域。该方法有效地将多件服装的纹理线索整合到生成的图像中,并进一步增强了文本与图像的一致性。
此外,我们引入了服装增强纹理学习策略来改善服装的细粒度纹理细节。得益于我们精心设计,AnyDressing 可以作为插件模块,轻松与任何社区控制扩展集成以用于扩散模型,从而提高合成图像的多样性和可控性。
大量实验表明,AnyDressing 取得了最先进的成果。
Introduction
近年来,图像生成领域经历了变革性进步,特别是基于潜在扩散模型 (LDM) 的方法在文本到图像生成任务中取得了显著成功。考虑到仅使用文本信息不足以实现图像定制,许多方法将参考图像与文本描述结合起来生成图像。
特别是,基于参考服装的个性化服装中心图像生成(Virtual Dressing, VD)引起了极大的关注,因为它在电子商务和时装设计中具有巨大的实际应用潜力。
VD之前被当作传统的主体驱动图像生成的子领域,这类方法只是将主体图像的特征集成到文本嵌入中,而没有充分利用参考图像中的信息,这在捕捉服装的复杂风格和细节方面是行不通的。
虽然IP-Adapter通过训练额外的交叉注意层将参考图像特征集成到扩散模型中,更全面地利用了参考图像的特征,但这仍然不足以保留复杂的纹理。最近的一些方法利用扩散UNet的完整副本作为服装编码器,称为ReferenceNet,以提取细粒度的服装信息。
然而,这些方法只针对单件服装量身定制,缺乏对多种条件的支持,因此阻碍了自由搭配各种服装的能力。此外,这些方法在根据定制的文本提示生成连贯且有吸引力的图像方面遇到困难,这进一步限制了它们的实际应用。
在这项工作中,我们的重点是关注多服饰虚拟试穿任务,根据定制的文本提示或其他控件对穿着任意组合的目标服装的角色进行个性化,利用预先训练的文本到图像扩散模型提供的先验知识。
这项任务带来了几个挑战,包括:
服装保真度:防止多件服装之间混淆,同时保持每件服装的复杂纹理;
文本一致性:确保生成的图像忠实于文本提示;
插件支持:实现与任何社区控制插件的无缝集成以用于扩散模型。解决这些挑战对于任务的实际应用至关重要。
为了解决上述问题,我们提出了 AnyDressing,这是一种新颖的方法,可以根据任何服装组合和任何个性化文本提示来定制角色。AnyDressing 主要由两个 U-Nets 组成,分别名为 GarmentsNet 和 DressingNet,分别用于提取详细的服装特征和生成定制图像。
认识到只有自注意力层对于隐式扭曲至关重要,而其他组件主要用作一般特征提取器,我们设计的 GarmentsNet 利用Garment-Specific Feature Extractor(GFE)模块提取多件服装的特征,核心是利用共享 UNet 架构中的并行自注意力LoRA层。这个设计不仅避免多服饰间的污染问题,同时保证了网络的高效性,可以轻松扩展至任意服装数量的组合。
为了保持生成的图像与参考服装的高度一致性,我们设计了一种Dressing-Attention机制,将参考图像特征无缝集成到去噪过程中。我们还引入了一个Instance-Level Garment Localization Learning策略,以提高对任意自定义文本提示的保真度并进一步最大限度地减少服装混淆,该策略明确指导模型将每种服装状况与图像的正确区域相关联,同时避免在训练阶段影响不相关的区域。该策略有助于在推理阶段生成高质量的多服装虚拟穿衣结果而无需额外输入。
为了进一步提高模型对服装细节的关注,我们另外设计了一种Garment-Enhanced Texture Learning来提供高频先验,从而指导生成图像中精细细节的合成,旨在在虚拟穿衣任务中更好地保留高频纹理细节。
大量实验表明,AnyDressing 能够在生成的图像中保留参考多件服装的细节,同时保持对文本提示的忠实度。与最先进的方法相比,我们的方法在定量和定性比较中具有明显的优势。特别地,AnyDressing还可以作为插件兼容各种微调的LDM、定制化的LoRA以及ControlNet、IP-Adapter等其他扩展,增强生成图像的多样性和可控性。总体来说,我们的贡献点可以总结为:
我们提出了一种新颖的 GarmentsNet结构,通过使用核心的Garment-Specific Feature Extractor(GFE)来高效地并行捕获多服装纹理信息
我们设计了一种新颖的 DressingNet,结合了 Dressing-Attention 机制和Instance-Level Garment Localization Learning 策略,以准确地将多服装特征注入其相应区域
我们引入了一种 Garment-Enhanced Texture Learning 策略,以有效增强合成图像中的细粒度纹理细节
我们的框架可以与任何社区控制插件无缝集成以用于扩散模型。定量和定性的实验均表明我们方法达到了SOTA的效果
Method
给定 套目标服装,AnyDressing 旨在根据文本提示生成一个新图像,定制角色在不同场景、风格和动作下穿着多套目标服装。如我们的框架概览图所示,AnyDressing 包含两个主要网络:GarmentsNet,从多套服装中提取特征以及 DressingNet是主要的去噪 Unet,负责整合详细的服装特征并促进多套服装的虚拟试穿。此外,我们设计了一种服装增强纹理学习机制来增强合成图像中的关键纹理细节。
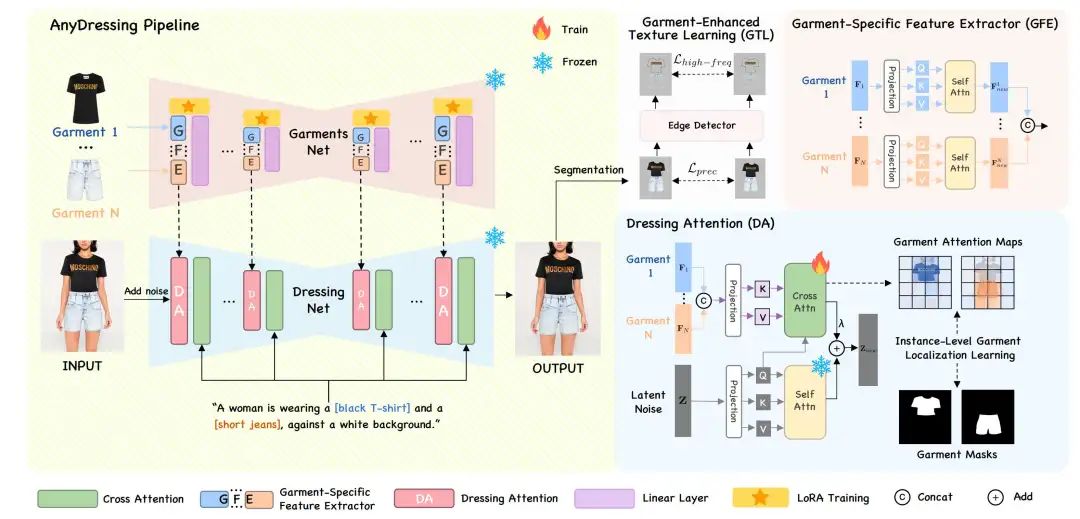
GarmentsNet
以往的方法引入了一种与稳定扩散结构类似的服装编码网络ReferenceNet用来提取服装细节特征,但仅限于处理单件服装,在处理多服饰VD任务面临严重的服饰污染问题。在处理穿多件服装的任务时,一种简单的方法是复制几个服装编码网络来管理不同的条件。然而,这种方法会导致参数数量大幅增加,使其在计算上不切实际。
从上述介绍的参考机制中汲取灵感,我们发现self-attn层对于服装特征的隐式扭曲至关重要,这使得输入服装能够有效地与适当的身体部位匹配,而其他网络架构通常负责一般特征提取,可以在不影响模型性能的情况下在不同的服装之间共享。由此,我们创新性地设计了一个简单而有效的架构,名为 GarmentsNet,核心是利用Garment-Specific Feature Extractor (GFE) 模块,利用共享 U-Net 框架内的 LoRA层对每件服装的特征进行单独编码。因此,这种设计在保持网络效率的同时,显著避免了服装混合。
值得注意的是,GarmentsNet 具有强大的可扩展性,可以轻松扩展以适应任何条件组合,并且每个附加条件的参数增加量仅有self-attn层的一些LoRA参数,与复制整个服装编码网络相比,这种设计显著减少了训练和推理时间。
DressingNet
为了在扩散过程中融入多服装特征,我们精心设计了一个名为 DressingNet 的架构,它作为主要的去噪网络,主要包括 Dressing-Attention 机制和 Instance-Level Garment Localization Learning 策略。
Adaptive Dressing-Attention
在虚拟试衣任务中,主去噪网络应尽可能保留其原有的编辑和生成能力,因此其权重在训练期间是冻结的。然而,这也使得预训练的注意模块无法有效捕捉参考服装特征与潜在噪声之间的关系。
为了解决这个问题,我们设计了一种自适应的 Dressing-Attention 机制,将参考图像特征集成到去噪 UNet(DressingNet)中。Dressing-Attention 模块由可学习的交叉注意模块和冻结的自注意模块组成。具体而言,我们引入两个可训练的线性投影层 和 来将参考服装特征与潜在噪声对齐。
假设 {} 表示 GarmentsNet 在相应位置输出的 个服装状况特征,我们首先沿空间维度连接这些特征以获得最终特征
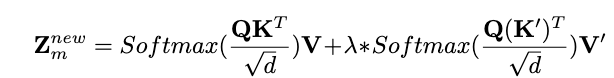
Instance-Level Garment Localization Learning
尽管 Dressing-Attention 机制允许将从 GarmentsNet 中提取的多服装特征隐式扭曲并无缝集成到 DressingNet 中,但文本提示不一致和局部服装混淆的问题仍然存在。我们观察到这些问题是由于服装特征倾向于同时关注所有图像区域,导致以多服装为中心的图像生成中的背景污染和服装混合。
我们引入了一种实例级服装定位 (IGL) 学习策略来规范注意力图。我们利用详细的参考服装特征来限制注意力区域,方法的核心是鼓励服装特征在训练阶段仅关注相应服装占据的图像区域,从而实现高质量的图像合成。
具体来说,对于每个服装特征,我们可以在 Dressing-Attention 模块的每一层中利用潜在噪声得到其注意力图 :
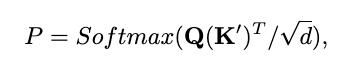
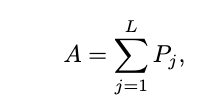
我们引入了一个正则化项,明确约束模型学习每个服装实例的注意力定位。形式上,我们提出的定位监督 如下:
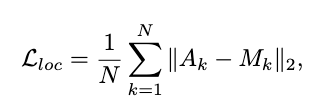
Garment-Enhanced Texture Learning
通常,扩散模型仅依靠均方损失进行优化,该损失对合成图像的所有区域进行同等对待,导致难以保持服装的一致性,尤其是在较小文字和图案复杂的情况下。因此,为了实现细粒度的纹理,我们设计了一种服装增强纹理学习 (GTL) 策略来加强对服装细节的监督,结合了感知损失 和高频损失 。假设 表示噪声注入步骤的总数。给定时间步长的阈值 ,我们可以估计去噪后的潜在 :
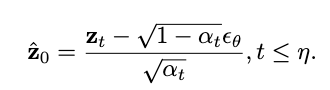
然后使用 VAE 解码器 从潜在空间解码潜在的 ,以获得预测图像 。考虑到一步逆转可能会生成嘈杂且有缺陷的图像,我们仅在噪声较少的阶段应用学习策略。最后,我们将损失 定义如下:
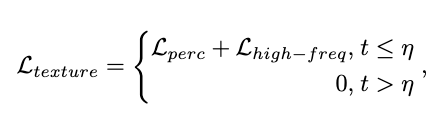
Perception Loss
为了同时增强与参考服装的结构一致性和图案相似性,基于深度图像结构和纹理相似性 (DISTS) 指标,我们设计了感知损失。具体来说,我们使用分割mask来得到生成图像和真实图像中的服装位置区域,平均他们在特征空间内的结构和纹理不一致性距离,定义为:
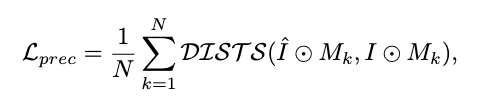
High-Frequency Loss
由于服装中的复杂细节通常表现为具有丰富边缘信息的高频成分,我们使用边缘检测来提取这种高频信息,旨在加强对细节图案的约束。
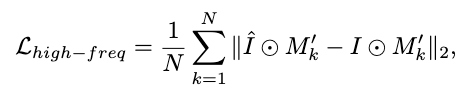
Experiments
Dataset
值得注意的是,目前缺少包含模型图像与多件摆放服装配对的图像三元组的数据集。因此,我们利用 HumanParsing 模型从 DressCode和从互联网收集的另一个专有数据集中提取服装,形成三元组数据对(上衣、下衣、人物图像)。在这些三元组中,一件服装是原始摆放图像,而另一件是从人物图像中分割出来的图像。
最后,我们从 Dresscode 构建了 26114 个三元组,从专有数据集构建了 37065 个三元组来训练 AnyDressing。
对于模型评估,我们引入了两个基准,分别在单件服装和多件服装着装上评估模型。
具体来说,对于单件服装评估,我们从 VITON-HD中精心挑选了 300 件风格各异、颜色各异的服装,此外还从互联网上收集了 300 件纹理复杂的参考服装和非服装图像。对于多件服装评估,我们从互联网上精心收集了 25 件下装,并将每件下装与 10 件不同的上装配对,共计 250 对,称为 Dressing-Pair 数据集。
Metrics
与以前的方法类似,我们从三个角度定量评估生成的结果:CLIP-T 用于文本一致性,CLIP-I 用于纹理一致性,美学评分 (AS) 用于整体生成质量。特别是,为了更好地评估多服装着装,我们引入了一种新的指标 来评估纹理一致性,方法是利用 OpenPose 获得生成图像中对应每件参考服装的匹配位置的分割图像并对其 CLIP-I 指标取平均值。
Qualitative Results
Metric Evaluation
表 1 显示了我们的方法相对于基线的定量结果。对于单件服装评估,在 VITON-HD [5] 和专有数据集上进行的大量实验证明了 AnyDressing 与所有基线相比的优越性。
并且我们的方法在多件服装虚拟试衣结果的所有指标上都显著超越了所有基线,充分证明了 AnyDressing 在处理单件服装和多件服装虚拟试衣任务方面的可靠性。

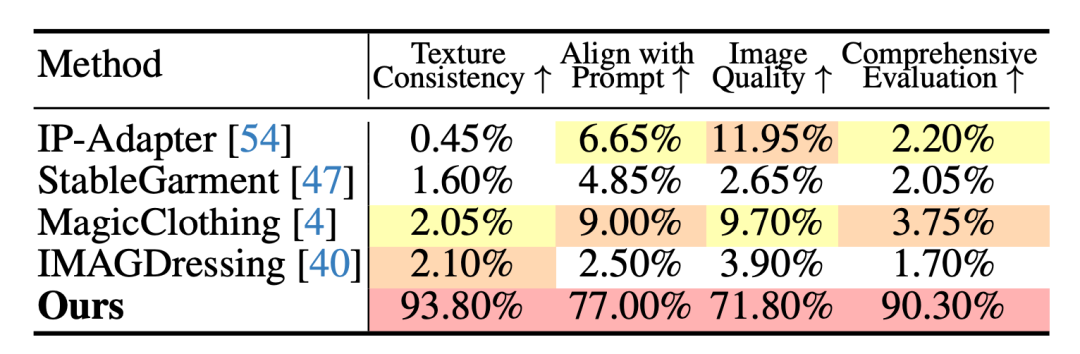
User Study
我们额外利用User Study来评估我们模型的生成质量。我们使用数据集中的所有测试服装和提示,并随机向用户展示来自基线和我们方法的 25 个单服装结果和 25 个多服装结果。要求每个参与者根据四个标准选择最喜欢的结果:纹理一致性、与文本提示的对齐、图像质量和综合评估。
最后,我们收到了 40 位用户的有效回复。收集到的偏好报告在表 2 中。就四个标准而言,我们的方法受到大多数参与者的青睐,百分比分别达到 93.80%、77.00%、71.80% 和 90.30%
Quantity Results
由于比较的方法缺乏多服装支持,我们通过沿空间维度连接多件服装作为输入来获得基线结果。
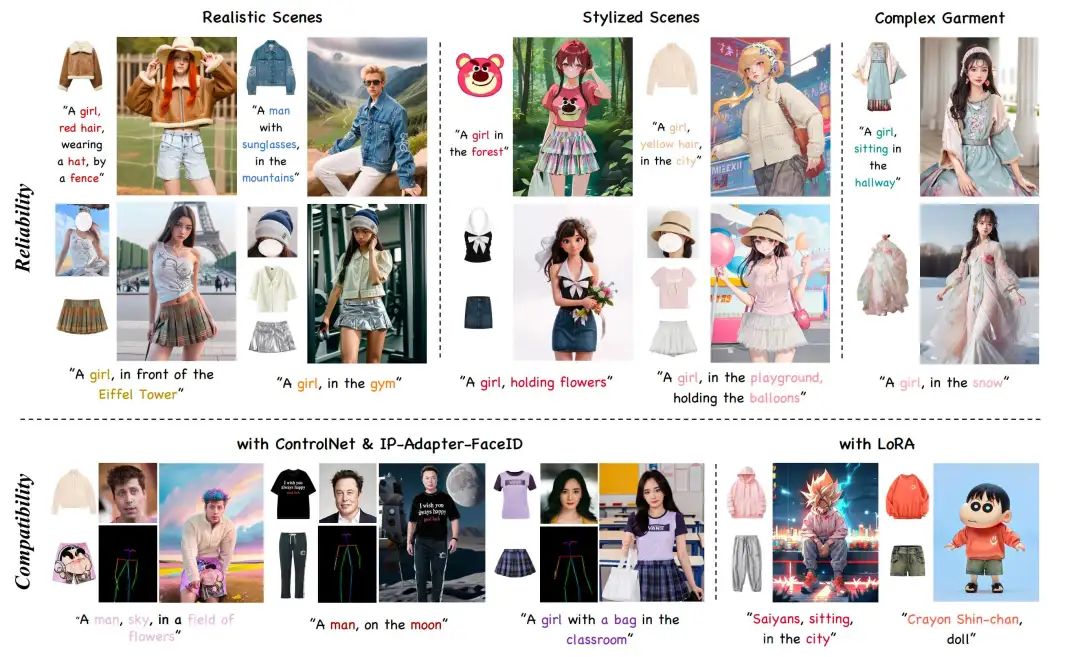
图 3 展示了我们的方法与基线方法之间的视觉比较。AnyDressing 在服装风格和质地方面保持了卓越的一致性,并表现出更好的文本保真度,而其他方法则难以平衡服装纹理保持和对文本的响应。特别是,基线在多服装穿衣结果中遇到严重的背景污染和服装混淆,而我们的方法表现出卓越的可靠性,这归功于我们设计的 GarmentsNet 和 DressingNet 架构。
图 4 展示了 AnyDressing 作为插件模块与其他扩展和定制的 LoRA 相结合的结果,展示了其强大的兼容性。请参阅补充资料了解更多结果。



Ablation Study
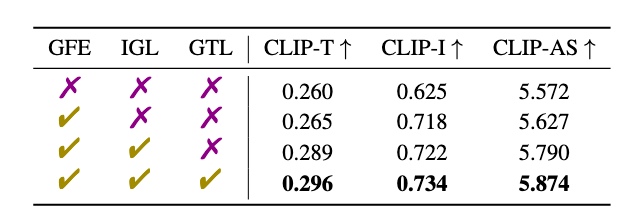
GFE 和 IGL:为了验证我们提出的架构的有效性,我们使用传统的 ReferenceNet同时对多件服装进行编码,然后将它们合并到类似于之前对比方法的去噪 U-Net 中作为我们的基础模型。如图 5 所示,与 Base 相比,Base+GFE 显著减少了服装混淆并提高了服装一致性,这归功于 GFE 模块的多服装并行处理设计。
Base+GFE+IGL 对文本提示的保真度更高,并进一步减轻了背景污染,这表明 IGL 机制有效地限制了服装特征以关注正确的区域。表 3 中的定量比较进一步证明了每个模块的有效性,其中 GFE 主要改进了 CLIP-I∗,而 IGL 增强了 CLIP-T 和 CLIP-AS。
GTL:图 6 直观地展示了我们提出的 GTL 策略的有效性,鼓励模型增强细节保存,特别是在小文本和复杂图案中。表 3 中的定量结果也验证了我们设计的 GTL 提高了纹理一致性。
|
|


最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「虚拟试衣」交流群👇备注:try-on



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









